 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHubs and Spokes Learning: Efficient and Scalable Collaborative Machine Learning
Apr 29, 2025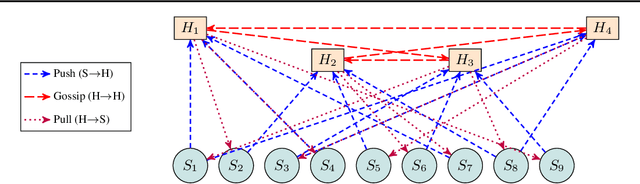
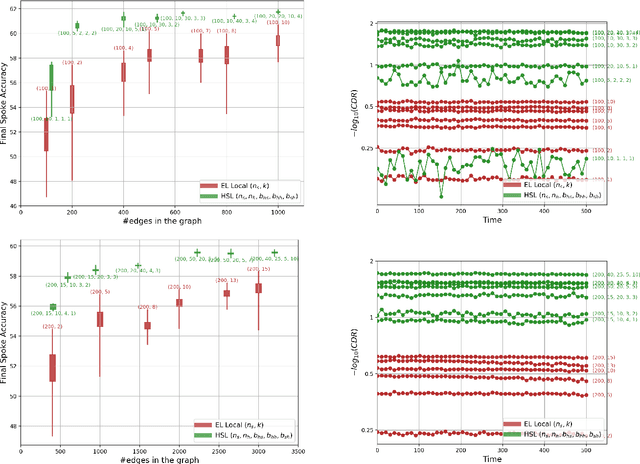
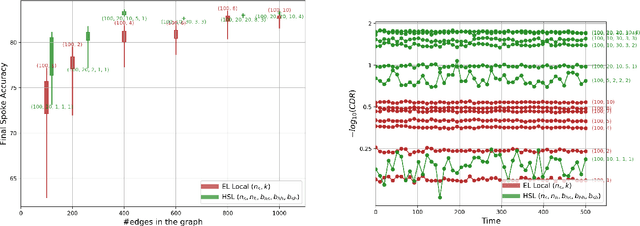
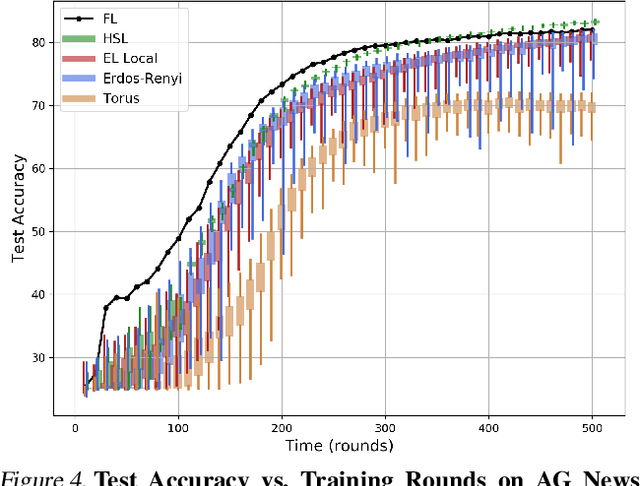
We introduce the Hubs and Spokes Learning (HSL) framework, a novel paradigm for collaborative machine learning that combines the strengths of Federated Learning (FL) and Decentralized Learning (P2PL). HSL employs a two-tier communication structure that avoids the single point of failure inherent in FL and outperforms the state-of-the-art P2PL framework, Epidemic Learning Local (ELL). At equal communication budgets (total edges), HSL achieves higher performance than ELL, while at significantly lower communication budgets, it can match ELL's performance. For instance, with only 400 edges, HSL reaches the same test accuracy that ELL achieves with 1000 edges for 100 peers (spokes) on CIFAR-10, demonstrating its suitability for resource-constrained systems. HSL also achieves stronger consensus among nodes after mixing, resulting in improved performance with fewer training rounds. We substantiate these claims through rigorous theoretical analyses and extensive experimental results, showcasing HSL's practicality for large-scale collaborative learning.
Learning to Inference Adaptively for Multimodal Large Language Models
Mar 13, 2025
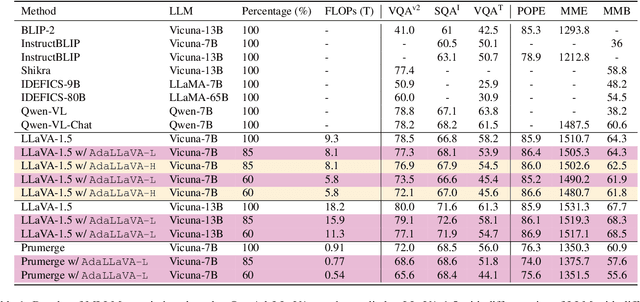
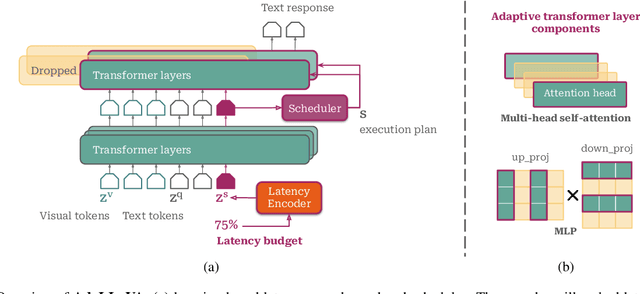
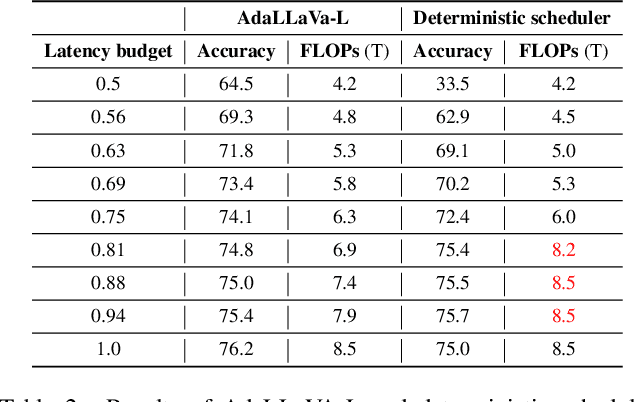
Multimodal Large Language Models (MLLMs) have shown impressive capabilities in reasoning, yet come with substantial computational cost, limiting their deployment in resource-constrained settings. Despite recent efforts on improving the efficiency of MLLMs, prior solutions fall short in responding to varying runtime conditions, in particular changing resource availability (e.g., contention due to the execution of other programs on the device). To bridge this gap, we introduce AdaLLaVA, an adaptive inference framework that learns to dynamically reconfigure operations in an MLLM during inference, accounting for the input data and a latency budget. We conduct extensive experiments across benchmarks involving question-answering, reasoning, and hallucination. Our results show that AdaLLaVA effectively adheres to input latency budget, achieving varying accuracy and latency tradeoffs at runtime. Further, we demonstrate that AdaLLaVA adapts to both input latency and content, can be integrated with token selection for enhanced efficiency, and generalizes across MLLMs.Our project webpage with code release is at https://zhuoyan-xu.github.io/ada-llava/.
SKALD: Learning-Based Shot Assembly for Coherent Multi-Shot Video Creation
Mar 11, 2025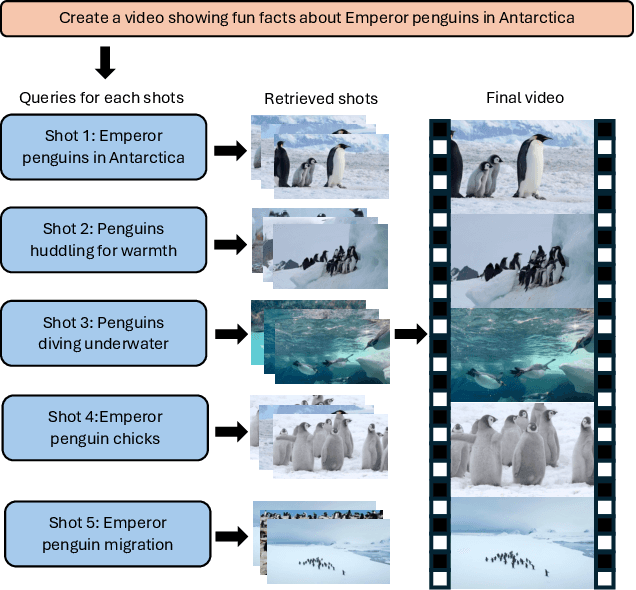
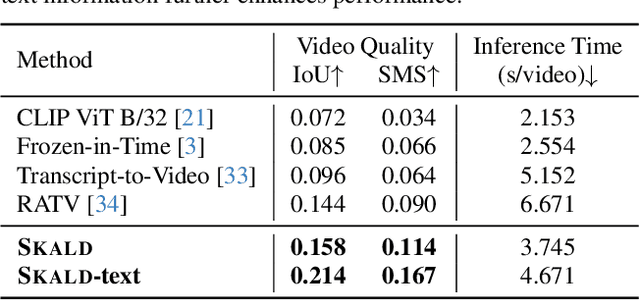

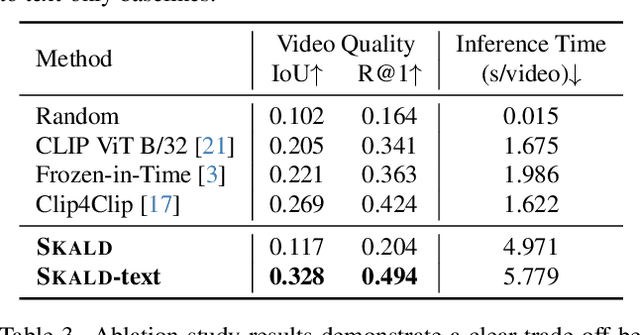
We present SKALD, a multi-shot video assembly method that constructs coherent video sequences from candidate shots with minimal reliance on text. Central to our approach is the Learned Clip Assembly (LCA) score, a learning-based metric that measures temporal and semantic relationships between shots to quantify narrative coherence. We tackle the exponential complexity of combining multiple shots with an efficient beam-search algorithm guided by the LCA score. To train our model effectively with limited human annotations, we propose two tasks for the LCA encoder: Shot Coherence Learning, which uses contrastive learning to distinguish coherent and incoherent sequences, and Feature Regression, which converts these learned representations into a real-valued coherence score. We develop two variants: a base SKALD model that relies solely on visual coherence and SKALD-text, which integrates auxiliary text information when available. Experiments on the VSPD and our curated MSV3C datasets show that SKALD achieves an improvement of up to 48.6% in IoU and a 43% speedup over the state-of-the-art methods. A user study further validates our approach, with 45% of participants favoring SKALD-assembled videos, compared to 22% preferring text-based assembly methods.
Federated Learning Privacy: Attacks, Defenses, Applications, and Policy Landscape - A Survey
May 06, 2024Deep learning has shown incredible potential across a vast array of tasks and accompanying this growth has been an insatiable appetite for data. However, a large amount of data needed for enabling deep learning is stored on personal devices and recent concerns on privacy have further highlighted challenges for accessing such data. As a result, federated learning (FL) has emerged as an important privacy-preserving technology enabling collaborative training of machine learning models without the need to send the raw, potentially sensitive, data to a central server. However, the fundamental premise that sending model updates to a server is privacy-preserving only holds if the updates cannot be "reverse engineered" to infer information about the private training data. It has been shown under a wide variety of settings that this premise for privacy does {\em not} hold. In this survey paper, we provide a comprehensive literature review of the different privacy attacks and defense methods in FL. We identify the current limitations of these attacks and highlight the settings in which FL client privacy can be broken. We dissect some of the successful industry applications of FL and draw lessons for future successful adoption. We survey the emerging landscape of privacy regulation for FL. We conclude with future directions for taking FL toward the cherished goal of generating accurate models while preserving the privacy of the data from its participants.
Virtuoso: Video-based Intelligence for real-time tuning on SOCs
Dec 24, 2021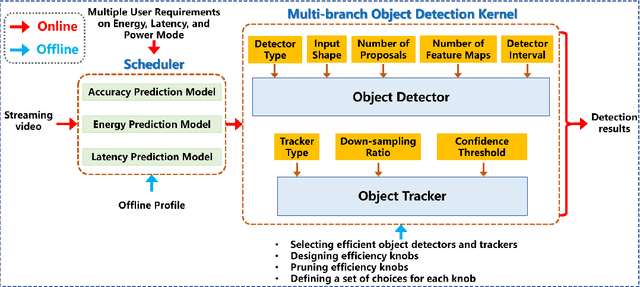
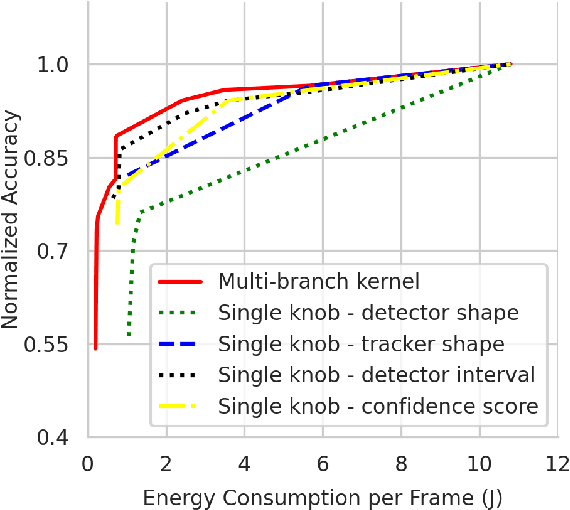
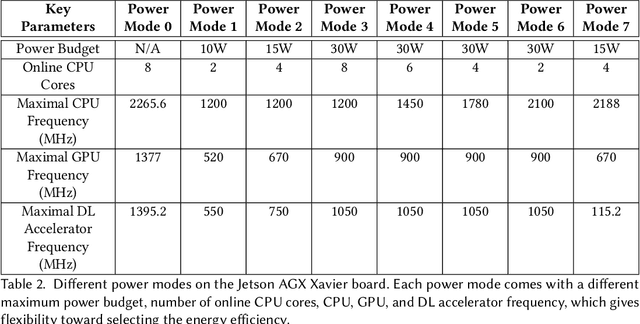
Efficient and adaptive computer vision systems have been proposed to make computer vision tasks, such as image classification and object detection, optimized for embedded or mobile devices. These solutions, quite recent in their origin, focus on optimizing the model (a deep neural network, DNN) or the system by designing an adaptive system with approximation knobs. In spite of several recent efforts, we show that existing solutions suffer from two major drawbacks. First, the system does not consider energy consumption of the models while making a decision on which model to run. Second, the evaluation does not consider the practical scenario of contention on the device, due to other co-resident workloads. In this work, we propose an efficient and adaptive video object detection system, Virtuoso, which is jointly optimized for accuracy, energy efficiency, and latency. Underlying Virtuoso is a multi-branch execution kernel that is capable of running at different operating points in the accuracy-energy-latency axes, and a lightweight runtime scheduler to select the best fit execution branch to satisfy the user requirement. To fairly compare with Virtuoso, we benchmark 15 state-of-the-art or widely used protocols, including Faster R-CNN (FRCNN), YOLO v3, SSD, EfficientDet, SELSA, MEGA, REPP, FastAdapt, and our in-house adaptive variants of FRCNN+, YOLO+, SSD+, and EfficientDet+ (our variants have enhanced efficiency for mobiles). With this comprehensive benchmark, Virtuoso has shown superiority to all the above protocols, leading the accuracy frontier at every efficiency level on NVIDIA Jetson mobile GPUs. Specifically, Virtuoso has achieved an accuracy of 63.9%, which is more than 10% higher than some of the popular object detection models, FRCNN at 51.1%, and YOLO at 49.5%.
Lerna: Transformer Architectures for Configuring Error Correction Tools for Short- and Long-Read Genome Sequencing
Dec 19, 2021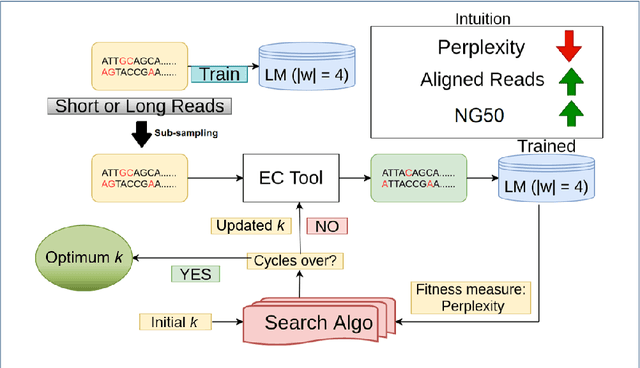
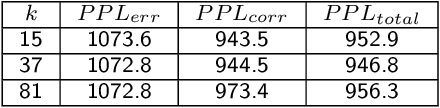
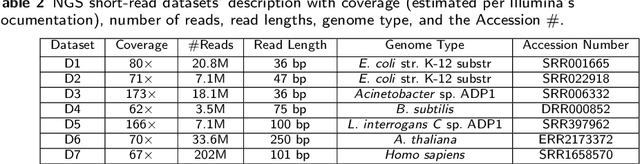
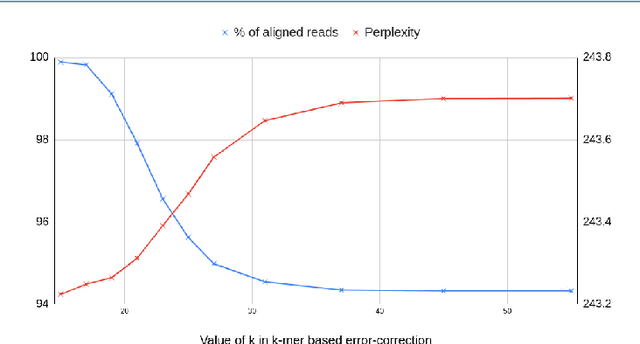
Sequencing technologies are prone to errors, making error correction (EC) necessary for downstream applications. EC tools need to be manually configured for optimal performance. We find that the optimal parameters (e.g., k-mer size) are both tool- and dataset-dependent. Moreover, evaluating the performance (i.e., Alignment-rate or Gain) of a given tool usually relies on a reference genome, but quality reference genomes are not always available. We introduce Lerna for the automated configuration of k-mer-based EC tools. Lerna first creates a language model (LM) of the uncorrected genomic reads; then, calculates the perplexity metric to evaluate the corrected reads for different parameter choices. Next, it finds the one that produces the highest alignment rate without using a reference genome. The fundamental intuition of our approach is that the perplexity metric is inversely correlated with the quality of the assembly after error correction. Results: First, we show that the best k-mer value can vary for different datasets, even for the same EC tool. Second, we show the gains of our LM using its component attention-based transformers. We show the model's estimation of the perplexity metric before and after error correction. The lower the perplexity after correction, the better the k-mer size. We also show that the alignment rate and assembly quality computed for the corrected reads are strongly negatively correlated with the perplexity, enabling the automated selection of k-mer values for better error correction, and hence, improved assembly quality. Additionally, we show that our attention-based models have significant runtime improvement for the entire pipeline -- 18X faster than previous works, due to parallelizing the attention mechanism and the use of JIT compilation for GPU inferencing.
TESSERACT: Gradient Flip Score to Secure Federated Learning Against Model Poisoning Attacks
Oct 19, 2021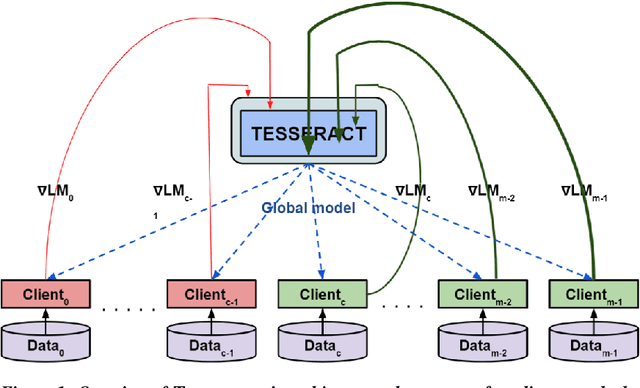

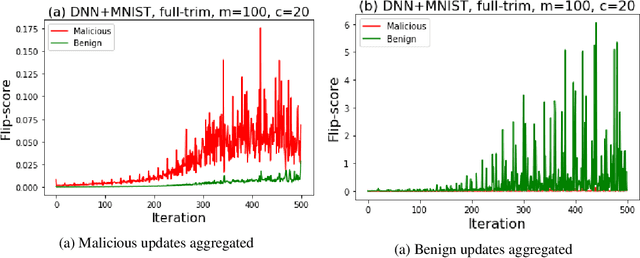
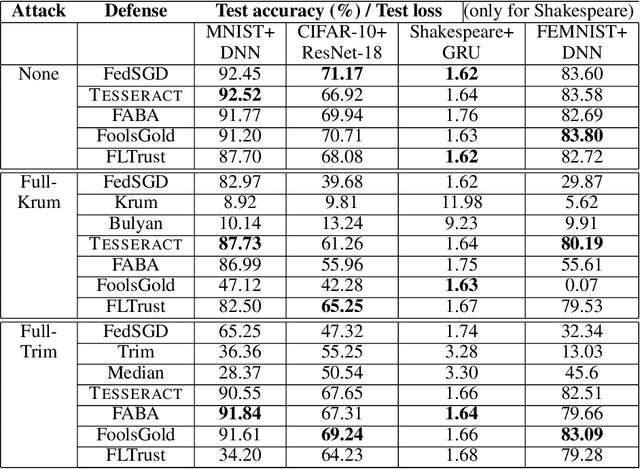
Federated learning---multi-party, distributed learning in a decentralized environment---is vulnerable to model poisoning attacks, even more so than centralized learning approaches. This is because malicious clients can collude and send in carefully tailored model updates to make the global model inaccurate. This motivated the development of Byzantine-resilient federated learning algorithms, such as Krum, Bulyan, FABA, and FoolsGold. However, a recently developed untargeted model poisoning attack showed that all prior defenses can be bypassed. The attack uses the intuition that simply by changing the sign of the gradient updates that the optimizer is computing, for a set of malicious clients, a model can be diverted from the optima to increase the test error rate. In this work, we develop TESSERACT---a defense against this directed deviation attack, a state-of-the-art model poisoning attack. TESSERACT is based on a simple intuition that in a federated learning setting, certain patterns of gradient flips are indicative of an attack. This intuition is remarkably stable across different learning algorithms, models, and datasets. TESSERACT assigns reputation scores to the participating clients based on their behavior during the training phase and then takes a weighted contribution of the clients. We show that TESSERACT provides robustness against even a white-box version of the attack.
Federated Action Recognition on Heterogeneous Embedded Devices
Jul 18, 2021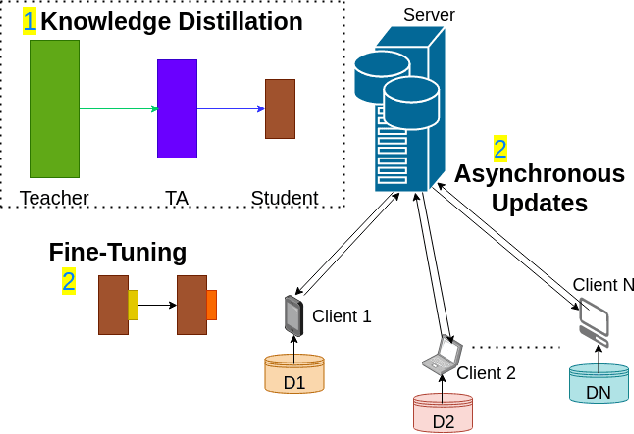
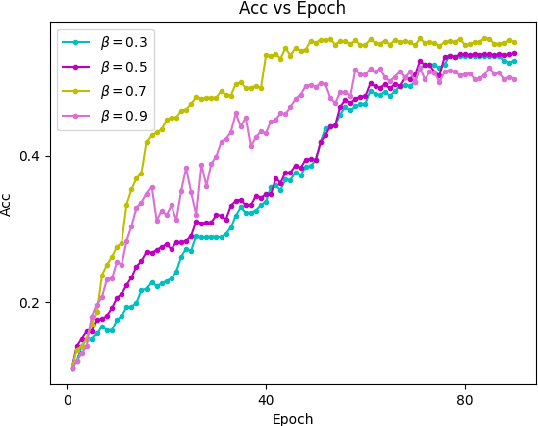
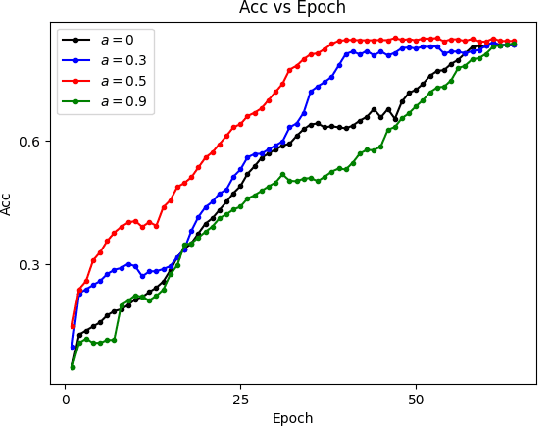
Federated learning allows a large number of devices to jointly learn a model without sharing data. In this work, we enable clients with limited computing power to perform action recognition, a computationally heavy task. We first perform model compression at the central server through knowledge distillation on a large dataset. This allows the model to learn complex features and serves as an initialization for model fine-tuning. The fine-tuning is required because the limited data present in smaller datasets is not adequate for action recognition models to learn complex spatio-temporal features. Because the clients present are often heterogeneous in their computing resources, we use an asynchronous federated optimization and we further show a convergence bound. We compare our approach to two baseline approaches: fine-tuning at the central server (no clients) and fine-tuning using (heterogeneous) clients using synchronous federated averaging. We empirically show on a testbed of heterogeneous embedded devices that we can perform action recognition with comparable accuracy to the two baselines above, while our asynchronous learning strategy reduces the training time by 40%, relative to synchronous learning.
* 13 pages, 12 figures
Ambrosia: Reduction in Data Transfer from Sensor to Server for Increased Lifetime of IoT Sensor Nodes
Jul 11, 2021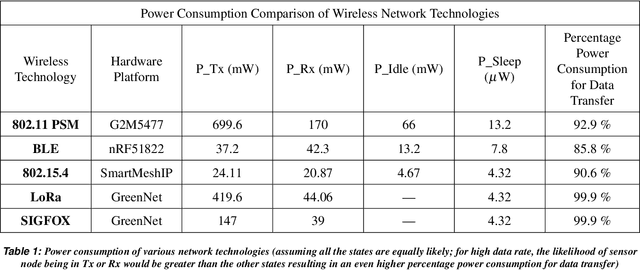
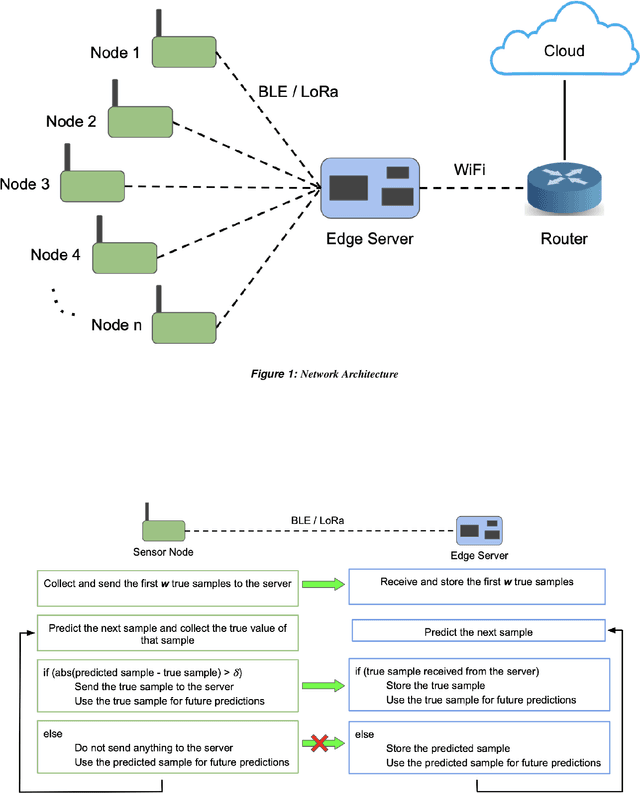
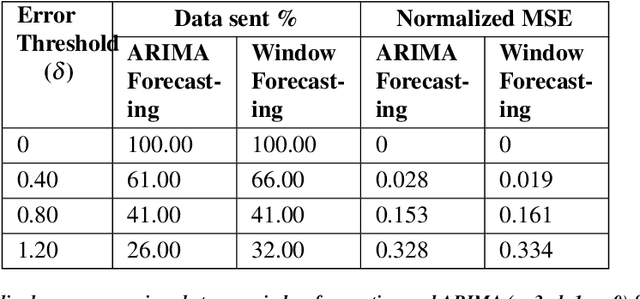
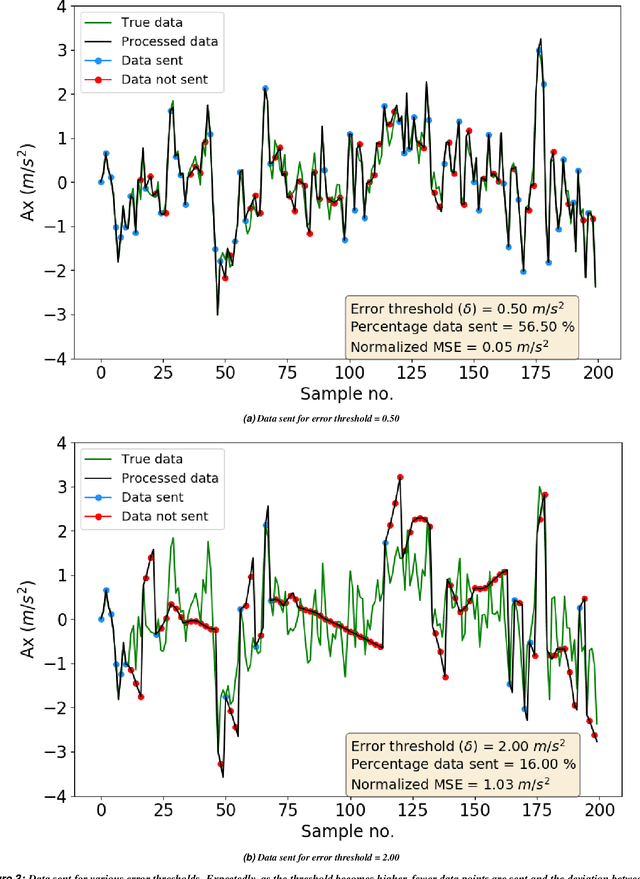
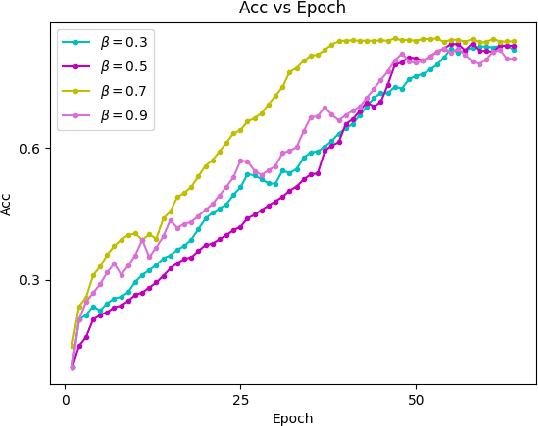
Data transmission accounts for significant energy consumption in wireless sensor networks where streaming data is generatedby the sensors. This impedes their use in many settings, including livestock monitoring over large pastures (which formsour target application). We present Ambrosia, a lightweight protocol that utilizes a window-based timeseries forecastingmechanism for data reduction. Ambrosia employs a configurable error threshold to ensure that the accuracy of end applicationsis unaffected by the data transfer reduction. Experimental evaluations using LoRa and BLE on a real livestock monitoringdeployment demonstrate 60% reduction in data transmission and a 2X increase in battery lifetime.
JANUS: Benchmarking Commercial and Open-Source Cloud and Edge Platforms for Object and Anomaly Detection Workloads
Dec 09, 2020
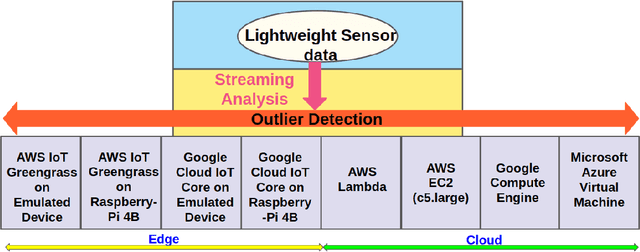
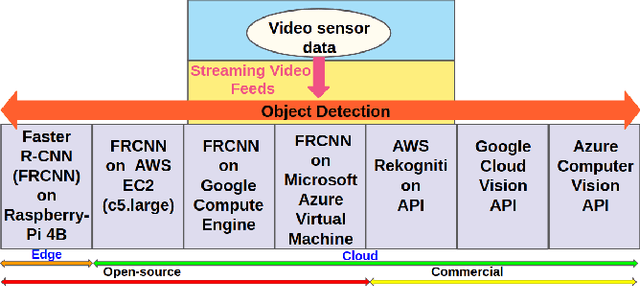
With diverse IoT workloads, placing compute and analytics close to where data is collected is becoming increasingly important. We seek to understand what is the performance and the cost implication of running analytics on IoT data at the various available platforms. These workloads can be compute-light, such as outlier detection on sensor data, or compute-intensive, such as object detection from video feeds obtained from drones. In our paper, JANUS, we profile the performance/$ and the compute versus communication cost for a compute-light IoT workload and a compute-intensive IoT workload. In addition, we also look at the pros and cons of some of the proprietary deep-learning object detection packages, such as Amazon Rekognition, Google Vision, and Azure Cognitive Services, to contrast with open-source and tunable solutions, such as Faster R-CNN (FRCNN). We find that AWS IoT Greengrass delivers at least 2X lower latency and 1.25X lower cost compared to all other cloud platforms for the compute-light outlier detection workload. For the compute-intensive streaming video analytics task, an opensource solution to object detection running on cloud VMs saves on dollar costs compared to proprietary solutions provided by Amazon, Microsoft, and Google, but loses out on latency (up to 6X). If it runs on a low-powered edge device, the latency is up to 49X lower.
* Appeared at the IEEE Cloud 2020 conference. 10 pages