 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Learning Privacy: Attacks, Defenses, Applications, and Policy Landscape - A Survey
May 06, 2024Deep learning has shown incredible potential across a vast array of tasks and accompanying this growth has been an insatiable appetite for data. However, a large amount of data needed for enabling deep learning is stored on personal devices and recent concerns on privacy have further highlighted challenges for accessing such data. As a result, federated learning (FL) has emerged as an important privacy-preserving technology enabling collaborative training of machine learning models without the need to send the raw, potentially sensitive, data to a central server. However, the fundamental premise that sending model updates to a server is privacy-preserving only holds if the updates cannot be "reverse engineered" to infer information about the private training data. It has been shown under a wide variety of settings that this premise for privacy does {\em not} hold. In this survey paper, we provide a comprehensive literature review of the different privacy attacks and defense methods in FL. We identify the current limitations of these attacks and highlight the settings in which FL client privacy can be broken. We dissect some of the successful industry applications of FL and draw lessons for future successful adoption. We survey the emerging landscape of privacy regulation for FL. We conclude with future directions for taking FL toward the cherished goal of generating accurate models while preserving the privacy of the data from its participants.
Leak and Learn: An Attacker's Cookbook to Train Using Leaked Data from Federated Learning
Mar 26, 2024
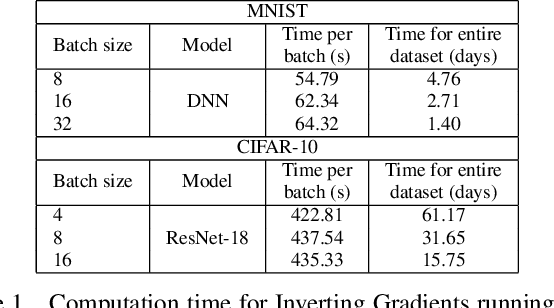
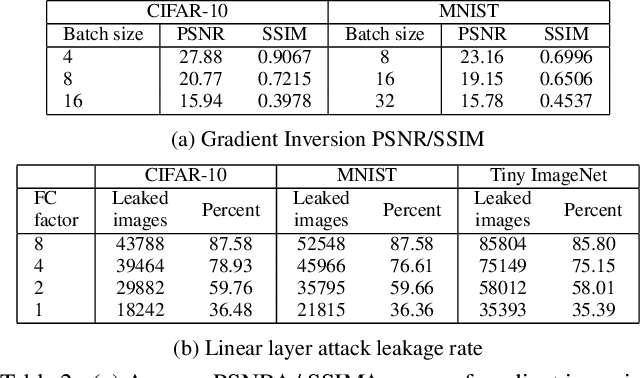

Federated learning is a decentralized learning paradigm introduced to preserve privacy of client data. Despite this, prior work has shown that an attacker at the server can still reconstruct the private training data using only the client updates. These attacks are known as data reconstruction attacks and fall into two major categories: gradient inversion (GI) and linear layer leakage attacks (LLL). However, despite demonstrating the effectiveness of these attacks in breaching privacy, prior work has not investigated the usefulness of the reconstructed data for downstream tasks. In this work, we explore data reconstruction attacks through the lens of training and improving models with leaked data. We demonstrate the effectiveness of both GI and LLL attacks in maliciously training models using the leaked data more accurately than a benign federated learning strategy. Counter-intuitively, this bump in training quality can occur despite limited reconstruction quality or a small total number of leaked images. Finally, we show the limitations of these attacks for downstream training, individually for GI attacks and for LLL attacks.
The Resource Problem of Using Linear Layer Leakage Attack in Federated Learning
Mar 27, 2023



Secure aggregation promises a heightened level of privacy in federated learning, maintaining that a server only has access to a decrypted aggregate update. Within this setting, linear layer leakage methods are the only data reconstruction attacks able to scale and achieve a high leakage rate regardless of the number of clients or batch size. This is done through increasing the size of an injected fully-connected (FC) layer. However, this results in a resource overhead which grows larger with an increasing number of clients. We show that this resource overhead is caused by an incorrect perspective in all prior work that treats an attack on an aggregate update in the same way as an individual update with a larger batch size. Instead, by attacking the update from the perspective that aggregation is combining multiple individual updates, this allows the application of sparsity to alleviate resource overhead. We show that the use of sparsity can decrease the model size overhead by over 327$\times$ and the computation time by 3.34$\times$ compared to SOTA while maintaining equivalent total leakage rate, 77% even with $1000$ clients in aggregation.
Secure Aggregation in Federated Learning is not Private: Leaking User Data at Large Scale through Model Modification
Mar 21, 2023



Security and privacy are important concerns in machine learning. End user devices often contain a wealth of data and this information is sensitive and should not be shared with servers or enterprises. As a result, federated learning was introduced to enable machine learning over large decentralized datasets while promising privacy by eliminating the need for data sharing. However, prior work has shown that shared gradients often contain private information and attackers can gain knowledge either through malicious modification of the architecture and parameters or by using optimization to approximate user data from the shared gradients. Despite this, most attacks have so far been limited in scale of number of clients, especially failing when client gradients are aggregated together using secure model aggregation. The attacks that still function are strongly limited in the number of clients attacked, amount of training samples they leak, or number of iterations they take to be trained. In this work, we introduce MANDRAKE, an attack that overcomes previous limitations to directly leak large amounts of client data even under secure aggregation across large numbers of clients. Furthermore, we break the anonymity of aggregation as the leaked data is identifiable and directly tied back to the clients they come from. We show that by sending clients customized convolutional parameters, the weight gradients of data points between clients will remain separate through aggregation. With an aggregation across many clients, prior work could only leak less than 1% of images. With the same number of non-zero parameters, and using only a single training iteration, MANDRAKE leaks 70-80% of data samples.