 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Diffusion Models as Generative Replay in Continual Federated Learning -- What will Happen?
Nov 10, 2024



Federated learning (FL) has become a cornerstone in decentralized learning, where, in many scenarios, the incoming data distribution will change dynamically over time, introducing continuous learning (CL) problems. This continual federated learning (CFL) task presents unique challenges, particularly regarding catastrophic forgetting and non-IID input data. Existing solutions include using a replay buffer to store historical data or leveraging generative adversarial networks. Nevertheless, motivated by recent advancements in the diffusion model for generative tasks, this paper introduces DCFL, a novel framework tailored to address the challenges of CFL in dynamic distributed learning environments. Our approach harnesses the power of the conditional diffusion model to generate synthetic historical data at each local device during communication, effectively mitigating latent shifts in dynamic data distribution inputs. We provide the convergence bound for the proposed CFL framework and demonstrate its promising performance across multiple datasets, showcasing its effectiveness in tackling the complexities of CFL tasks.
Federated Learning Privacy: Attacks, Defenses, Applications, and Policy Landscape - A Survey
May 06, 2024Deep learning has shown incredible potential across a vast array of tasks and accompanying this growth has been an insatiable appetite for data. However, a large amount of data needed for enabling deep learning is stored on personal devices and recent concerns on privacy have further highlighted challenges for accessing such data. As a result, federated learning (FL) has emerged as an important privacy-preserving technology enabling collaborative training of machine learning models without the need to send the raw, potentially sensitive, data to a central server. However, the fundamental premise that sending model updates to a server is privacy-preserving only holds if the updates cannot be "reverse engineered" to infer information about the private training data. It has been shown under a wide variety of settings that this premise for privacy does {\em not} hold. In this survey paper, we provide a comprehensive literature review of the different privacy attacks and defense methods in FL. We identify the current limitations of these attacks and highlight the settings in which FL client privacy can be broken. We dissect some of the successful industry applications of FL and draw lessons for future successful adoption. We survey the emerging landscape of privacy regulation for FL. We conclude with future directions for taking FL toward the cherished goal of generating accurate models while preserving the privacy of the data from its participants.
Federated Learning with Flexible Control
Dec 16, 2022Federated learning (FL) enables distributed model training from local data collected by users. In distributed systems with constrained resources and potentially high dynamics, e.g., mobile edge networks, the efficiency of FL is an important problem. Existing works have separately considered different configurations to make FL more efficient, such as infrequent transmission of model updates, client subsampling, and compression of update vectors. However, an important open problem is how to jointly apply and tune these control knobs in a single FL algorithm, to achieve the best performance by allowing a high degree of freedom in control decisions. In this paper, we address this problem and propose FlexFL - an FL algorithm with multiple options that can be adjusted flexibly. Our FlexFL algorithm allows both arbitrary rates of local computation at clients and arbitrary amounts of communication between clients and the server, making both the computation and communication resource consumption adjustable. We prove a convergence upper bound of this algorithm. Based on this result, we further propose a stochastic optimization formulation and algorithm to determine the control decisions that (approximately) minimize the convergence bound, while conforming to constraints related to resource consumption. The advantage of our approach is also verified using experiments.
Joint Coreset Construction and Quantization for Distributed Machine Learning
Apr 13, 2022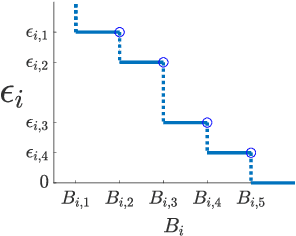
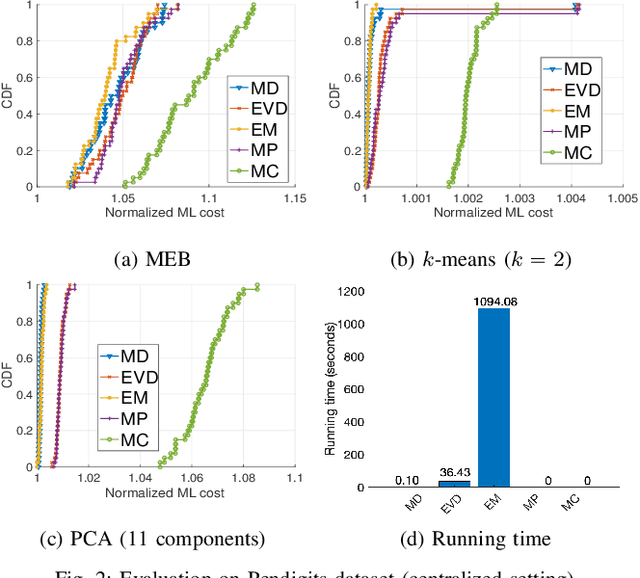
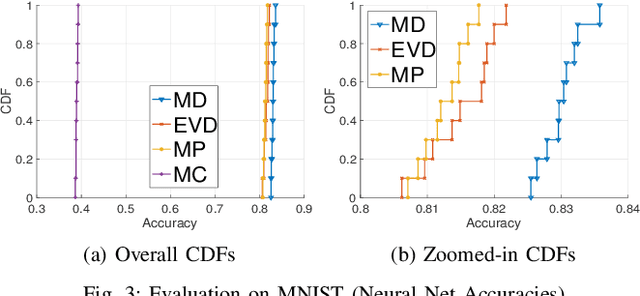
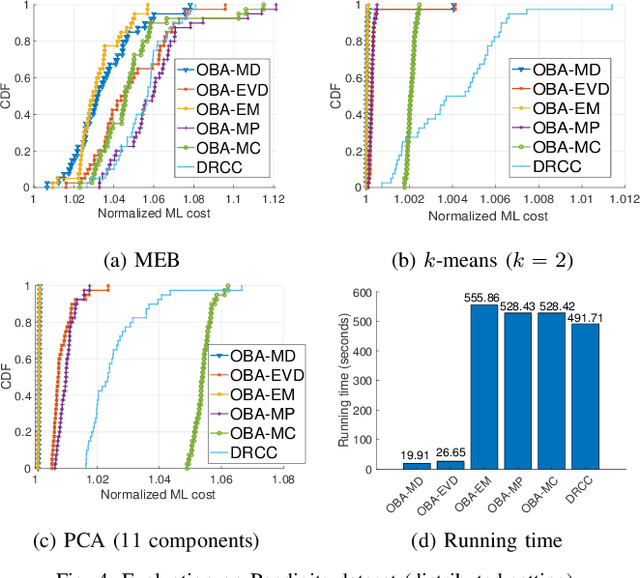
Coresets are small, weighted summaries of larger datasets, aiming at providing provable error bounds for machine learning (ML) tasks while significantly reducing the communication and computation costs. To achieve a better trade-off between ML error bounds and costs, we propose the first framework to incorporate quantization techniques into the process of coreset construction. Specifically, we theoretically analyze the ML error bounds caused by a combination of coreset construction and quantization. Based on that, we formulate an optimization problem to minimize the ML error under a fixed budget of communication cost. To improve the scalability for large datasets, we identify two proxies of the original objective function, for which efficient algorithms are developed. For the case of data on multiple nodes, we further design a novel algorithm to allocate the communication budget to the nodes while minimizing the overall ML error. Through extensive experiments on multiple real-world datasets, we demonstrate the effectiveness and efficiency of our proposed algorithms for a variety of ML tasks. In particular, our algorithms have achieved more than 90% data reduction with less than 10% degradation in ML performance in most cases.
Communication-efficient k-Means for Edge-based Machine Learning
Feb 08, 2021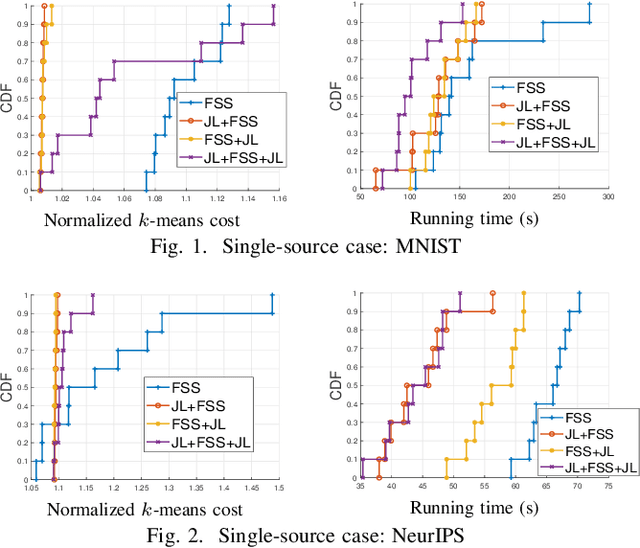
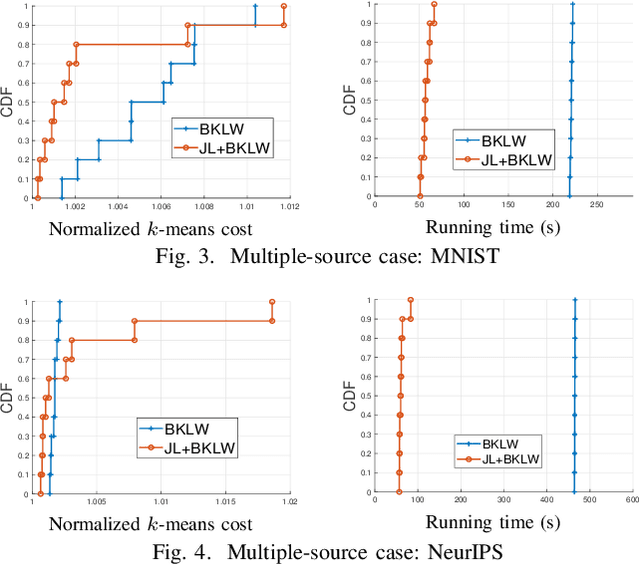
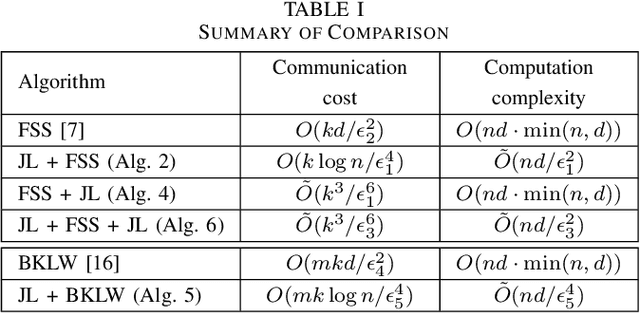
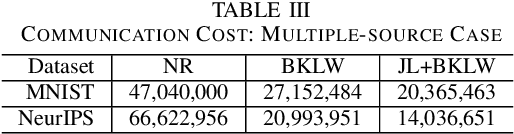
We consider the problem of computing the k-means centers for a large high-dimensional dataset in the context of edge-based machine learning, where data sources offload machine learning computation to nearby edge servers. k-Means computation is fundamental to many data analytics, and the capability of computing provably accurate k-means centers by leveraging the computation power of the edge servers, at a low communication and computation cost to the data sources, will greatly improve the performance of these analytics. We propose to let the data sources send small summaries, generated by joint dimensionality reduction (DR) and cardinality reduction (CR), to support approximate k-means computation at reduced complexity and communication cost. By analyzing the complexity, the communication cost, and the approximation error of k-means algorithms based on state-of-the-art DR/CR methods, we show that: (i) it is possible to achieve a near-optimal approximation at a near-linear complexity and a constant or logarithmic communication cost, (ii) the order of applying DR and CR significantly affects the complexity and the communication cost, and (iii) combining DR/CR methods with a properly configured quantizer can further reduce the communication cost without compromising the other performance metrics. Our findings are validated through experiments based on real datasets.
Sharing Models or Coresets: A Study based on Membership Inference Attack
Jul 06, 2020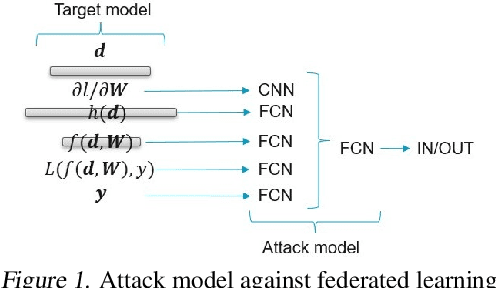
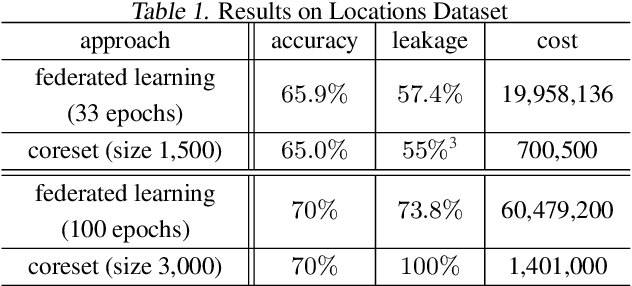
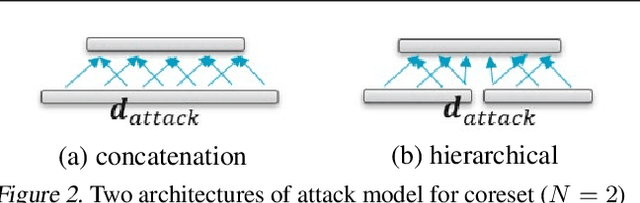
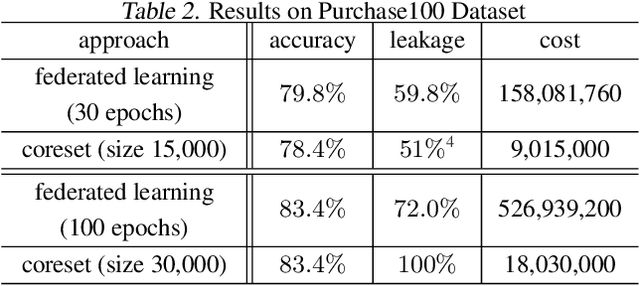
Distributed machine learning generally aims at training a global model based on distributed data without collecting all the data to a centralized location, where two different approaches have been proposed: collecting and aggregating local models (federated learning) and collecting and training over representative data summaries (coreset). While each approach preserves data privacy to some extent thanks to not sharing the raw data, the exact extent of protection is unclear under sophisticated attacks that try to infer the raw data from the shared information. We present the first comparison between the two approaches in terms of target model accuracy, communication cost, and data privacy, where the last is measured by the accuracy of a state-of-the-art attack strategy called the membership inference attack. Our experiments quantify the accuracy-privacy-cost tradeoff of each approach, and reveal a nontrivial comparison that can be used to guide the design of model training processes.
A4 : Evading Learning-based Adblockers
Jan 29, 2020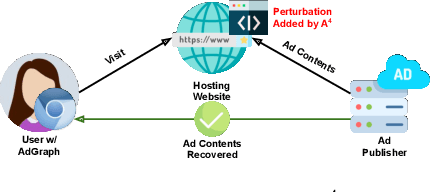
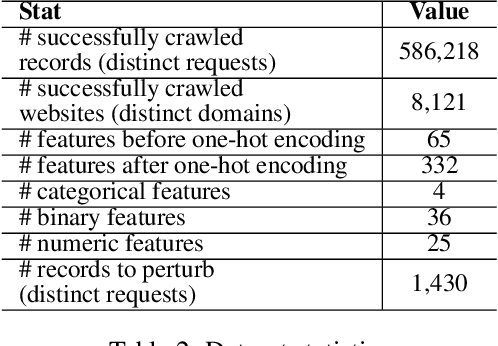
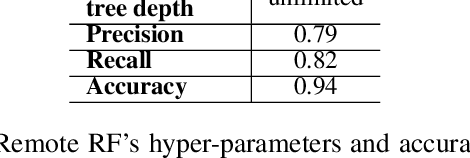
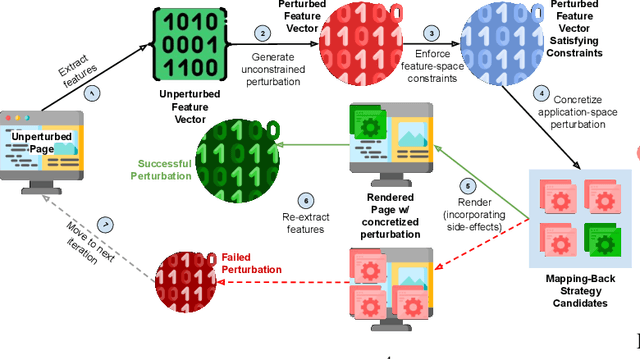
Efforts by online ad publishers to circumvent traditional ad blockers towards regaining fiduciary benefits, have been demonstrably successful. As a result, there have recently emerged a set of adblockers that apply machine learning instead of manually curated rules and have been shown to be more robust in blocking ads on websites including social media sites such as Facebook. Among these, AdGraph is arguably the state-of-the-art learning-based adblocker. In this paper, we develop A4, a tool that intelligently crafts adversarial samples of ads to evade AdGraph. Unlike the popular research on adversarial samples against images or videos that are considered less- to un-restricted, the samples that A4 generates preserve application semantics of the web page, or are actionable. Through several experiments we show that A4 can bypass AdGraph about 60% of the time, which surpasses the state-of-the-art attack by a significant margin of 84.3%; in addition, changes to the visual layout of the web page due to these perturbations are imperceptible. We envision the algorithmic framework proposed in A4 is also promising in improving adversarial attacks against other learning-based web applications with similar requirements.
Learning and Planning in Feature Deception Games
May 13, 2019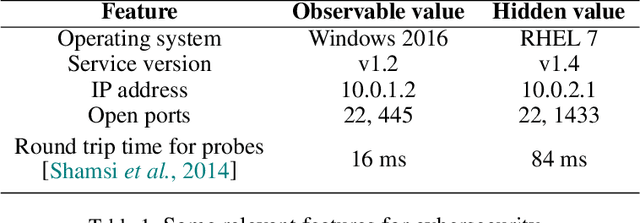
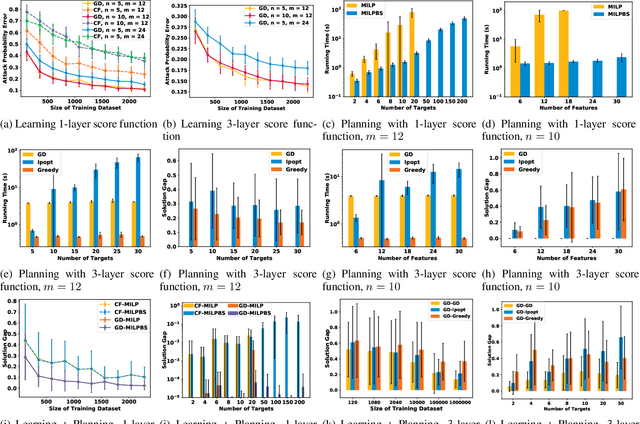
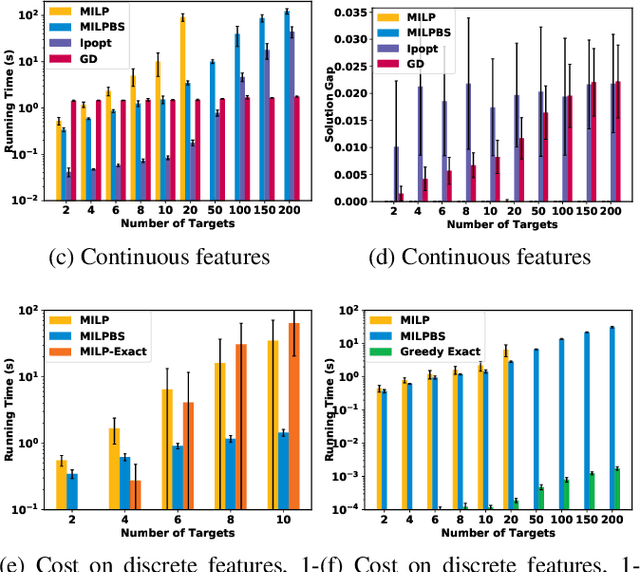

Today's high-stakes adversarial interactions feature attackers who constantly breach the ever-improving security measures. Deception mitigates the defender's loss by misleading the attacker to make suboptimal decisions. In order to formally reason about deception, we introduce the feature deception game (FDG), a domain-independent game-theoretic model and present a learning and planning framework. We make the following contributions. (1) We show that we can uniformly learn the adversary's preferences using data from a modest number of deception strategies. (2) We propose an approximation algorithm for finding the optimal deception strategy and show that the problem is NP-hard. (3) We perform extensive experiments to empirically validate our methods and results.