 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal Optimization on Graph-Structured Data via Gaussian Processes with Spectral Representations
Nov 11, 2025Bayesian optimization (BO) is a powerful framework for optimizing expensive black-box objectives, yet extending it to graph-structured domains remains challenging due to the discrete and combinatorial nature of graphs. Existing approaches often rely on either full graph topology-impractical for large or partially observed graphs-or incremental exploration, which can lead to slow convergence. We introduce a scalable framework for global optimization over graphs that employs low-rank spectral representations to build Gaussian process (GP) surrogates from sparse structural observations. The method jointly infers graph structure and node representations through learnable embeddings, enabling efficient global search and principled uncertainty estimation even with limited data. We also provide theoretical analysis establishing conditions for accurate recovery of underlying graph structure under different sampling regimes. Experiments on synthetic and real-world datasets demonstrate that our approach achieves faster convergence and improved optimization performance compared to prior methods.
Using Diffusion Models as Generative Replay in Continual Federated Learning -- What will Happen?
Nov 10, 2024



Federated learning (FL) has become a cornerstone in decentralized learning, where, in many scenarios, the incoming data distribution will change dynamically over time, introducing continuous learning (CL) problems. This continual federated learning (CFL) task presents unique challenges, particularly regarding catastrophic forgetting and non-IID input data. Existing solutions include using a replay buffer to store historical data or leveraging generative adversarial networks. Nevertheless, motivated by recent advancements in the diffusion model for generative tasks, this paper introduces DCFL, a novel framework tailored to address the challenges of CFL in dynamic distributed learning environments. Our approach harnesses the power of the conditional diffusion model to generate synthetic historical data at each local device during communication, effectively mitigating latent shifts in dynamic data distribution inputs. We provide the convergence bound for the proposed CFL framework and demonstrate its promising performance across multiple datasets, showcasing its effectiveness in tackling the complexities of CFL tasks.
RGMDT: Return-Gap-Minimizing Decision Tree Extraction in Non-Euclidean Metric Space
Oct 21, 2024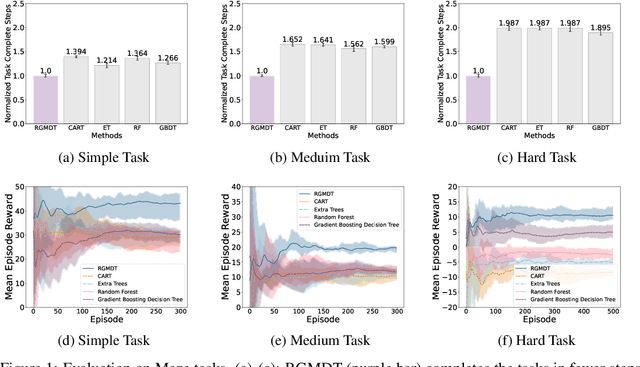

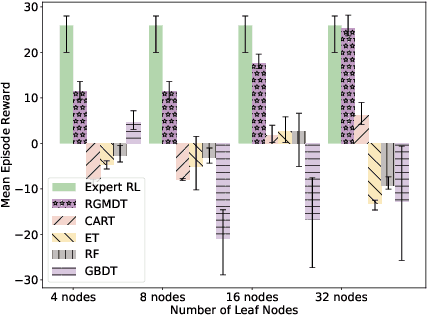

Deep Reinforcement Learning (DRL) algorithms have achieved great success in solving many challenging tasks while their black-box nature hinders interpretability and real-world applicability, making it difficult for human experts to interpret and understand DRL policies. Existing works on interpretable reinforcement learning have shown promise in extracting decision tree (DT) based policies from DRL policies with most focus on the single-agent settings while prior attempts to introduce DT policies in multi-agent scenarios mainly focus on heuristic designs which do not provide any quantitative guarantees on the expected return. In this paper, we establish an upper bound on the return gap between the oracle expert policy and an optimal decision tree policy. This enables us to recast the DT extraction problem into a novel non-euclidean clustering problem over the local observation and action values space of each agent, with action values as cluster labels and the upper bound on the return gap as clustering loss. Both the algorithm and the upper bound are extended to multi-agent decentralized DT extractions by an iteratively-grow-DT procedure guided by an action-value function conditioned on the current DTs of other agents. Further, we propose the Return-Gap-Minimization Decision Tree (RGMDT) algorithm, which is a surprisingly simple design and is integrated with reinforcement learning through the utilization of a novel Regularized Information Maximization loss. Evaluations on tasks like D4RL show that RGMDT significantly outperforms heuristic DT-based baselines and can achieve nearly optimal returns under given DT complexity constraints (e.g., maximum number of DT nodes).
Deep Generative Models for Offline Policy Learning: Tutorial, Survey, and Perspectives on Future Directions
Feb 26, 2024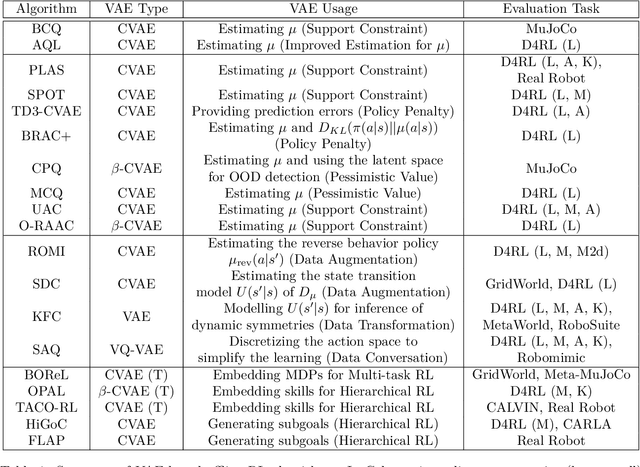
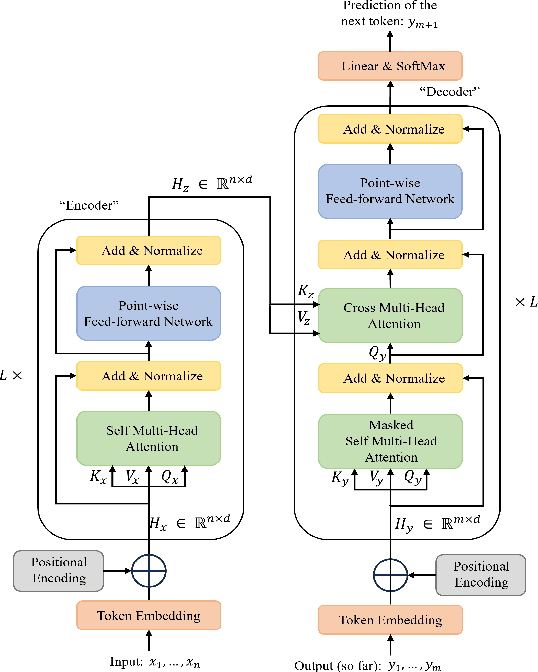
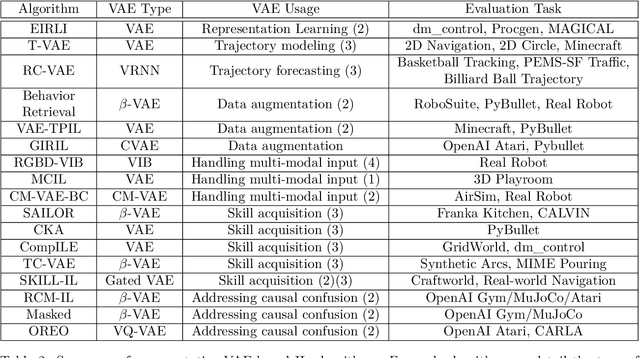
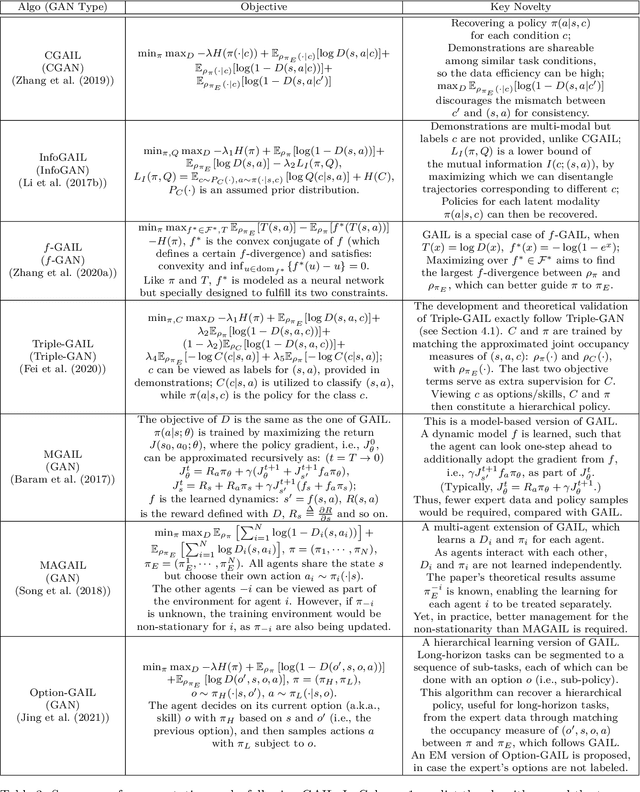
Deep generative models (DGMs) have demonstrated great success across various domains, particularly in generating texts, images, and videos using models trained from offline data. Similarly, data-driven decision-making and robotic control also necessitate learning a generator function from the offline data to serve as the strategy or policy. In this case, applying deep generative models in offline policy learning exhibits great potential, and numerous studies have explored in this direction. However, this field still lacks a comprehensive review and so developments of different branches are relatively independent. Thus, we provide the first systematic review on the applications of deep generative models for offline policy learning. In particular, we cover five mainstream deep generative models, including Variational Auto-Encoders, Generative Adversarial Networks, Normalizing Flows, Transformers, and Diffusion Models, and their applications in both offline reinforcement learning (offline RL) and imitation learning (IL). Offline RL and IL are two main branches of offline policy learning and are widely-adopted techniques for sequential decision-making. Specifically, for each type of DGM-based offline policy learning, we distill its fundamental scheme, categorize related works based on the usage of the DGM, and sort out the development process of algorithms in that field. Subsequent to the main content, we provide in-depth discussions on deep generative models and offline policy learning as a summary, based on which we present our perspectives on future research directions. This work offers a hands-on reference for the research progress in deep generative models for offline policy learning, and aims to inspire improved DGM-based offline RL or IL algorithms. For convenience, we maintain a paper list on https://github.com/LucasCJYSDL/DGMs-for-Offline-Policy-Learning.
Bayesian Optimization through Gaussian Cox Process Models for Spatio-temporal Data
Jan 25, 2024Bayesian optimization (BO) has established itself as a leading strategy for efficiently optimizing expensive-to-evaluate functions. Existing BO methods mostly rely on Gaussian process (GP) surrogate models and are not applicable to (doubly-stochastic) Gaussian Cox processes, where the observation process is modulated by a latent intensity function modeled as a GP. In this paper, we propose a novel maximum a posteriori inference of Gaussian Cox processes. It leverages the Laplace approximation and change of kernel technique to transform the problem into a new reproducing kernel Hilbert space, where it becomes more tractable computationally. It enables us to obtain both a functional posterior of the latent intensity function and the covariance of the posterior, thus extending existing works that often focus on specific link functions or estimating the posterior mean. Using the result, we propose a BO framework based on the Gaussian Cox process model and further develop a Nystr\"om approximation for efficient computation. Extensive evaluations on various synthetic and real-world datasets demonstrate significant improvement over state-of-the-art inference solutions for Gaussian Cox processes, as well as effective BO with a wide range of acquisition functions designed through the underlying Gaussian Cox process model.
Real-time Network Intrusion Detection via Decision Transformers
Dec 17, 2023Many cybersecurity problems that require real-time decision-making based on temporal observations can be abstracted as a sequence modeling problem, e.g., network intrusion detection from a sequence of arriving packets. Existing approaches like reinforcement learning may not be suitable for such cybersecurity decision problems, since the Markovian property may not necessarily hold and the underlying network states are often not observable. In this paper, we cast the problem of real-time network intrusion detection as casual sequence modeling and draw upon the power of the transformer architecture for real-time decision-making. By conditioning a causal decision transformer on past trajectories, consisting of the rewards, network packets, and detection decisions, our proposed framework will generate future detection decisions to achieve the desired return. It enables decision transformers to be applied to real-time network intrusion detection, as well as a novel tradeoff between the accuracy and timeliness of detection. The proposed solution is evaluated on public network intrusion detection datasets and outperforms several baseline algorithms using reinforcement learning and sequence modeling, in terms of detection accuracy and timeliness.
MAC-PO: Multi-Agent Experience Replay via Collective Priority Optimization
Feb 28, 2023Experience replay is crucial for off-policy reinforcement learning (RL) methods. By remembering and reusing the experiences from past different policies, experience replay significantly improves the training efficiency and stability of RL algorithms. Many decision-making problems in practice naturally involve multiple agents and require multi-agent reinforcement learning (MARL) under centralized training decentralized execution paradigm. Nevertheless, existing MARL algorithms often adopt standard experience replay where the transitions are uniformly sampled regardless of their importance. Finding prioritized sampling weights that are optimized for MARL experience replay has yet to be explored. To this end, we propose MAC-PO, which formulates optimal prioritized experience replay for multi-agent problems as a regret minimization over the sampling weights of transitions. Such optimization is relaxed and solved using the Lagrangian multiplier approach to obtain the close-form optimal sampling weights. By minimizing the resulting policy regret, we can narrow the gap between the current policy and a nominal optimal policy, thus acquiring an improved prioritization scheme for multi-agent tasks. Our experimental results on Predator-Prey and StarCraft Multi-Agent Challenge environments demonstrate the effectiveness of our method, having a better ability to replay important transitions and outperforming other state-of-the-art baselines.
ReMIX: Regret Minimization for Monotonic Value Function Factorization in Multiagent Reinforcement Learning
Feb 11, 2023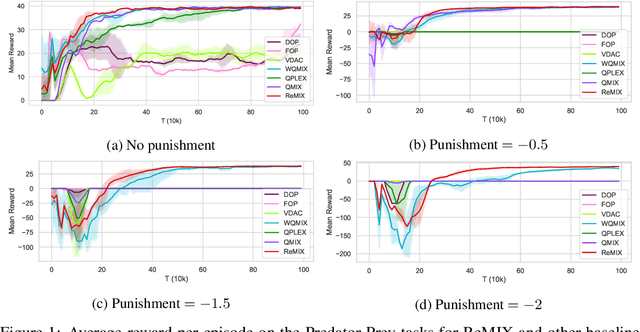

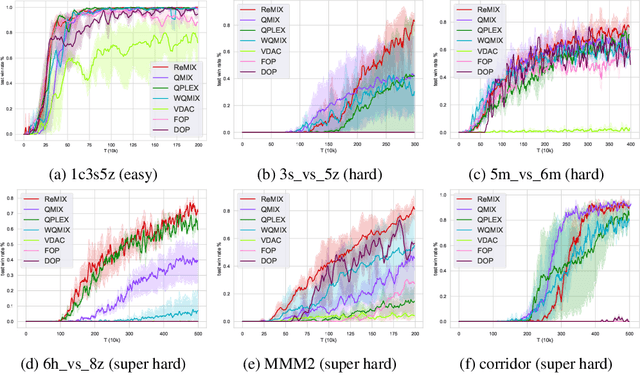

Value function factorization methods have become a dominant approach for cooperative multiagent reinforcement learning under a centralized training and decentralized execution paradigm. By factorizing the optimal joint action-value function using a monotonic mixing function of agents' utilities, these algorithms ensure the consistency between joint and local action selections for decentralized decision-making. Nevertheless, the use of monotonic mixing functions also induces representational limitations. Finding the optimal projection of an unrestricted mixing function onto monotonic function classes is still an open problem. To this end, we propose ReMIX, formulating this optimal projection problem for value function factorization as a regret minimization over the projection weights of different state-action values. Such an optimization problem can be relaxed and solved using the Lagrangian multiplier method to obtain the close-form optimal projection weights. By minimizing the resulting policy regret, we can narrow the gap between the optimal and the restricted monotonic mixing functions, thus obtaining an improved monotonic value function factorization. Our experimental results on Predator-Prey and StarCraft Multiagent Challenge environments demonstrate the effectiveness of our method, indicating the better capabilities of handling environments with non-monotonic value functions.
Exploiting Partial Common Information Microstructure for Multi-Modal Brain Tumor Segmentation
Feb 06, 2023



Learning with multiple modalities is crucial for automated brain tumor segmentation from magnetic resonance imaging data. Explicitly optimizing the common information shared among all modalities (e.g., by maximizing the total correlation) has been shown to achieve better feature representations and thus enhance the segmentation performance. However, existing approaches are oblivious to partial common information shared by subsets of the modalities. In this paper, we show that identifying such partial common information can significantly boost the discriminative power of image segmentation models. In particular, we introduce a novel concept of partial common information mask (PCI-mask) to provide a fine-grained characterization of what partial common information is shared by which subsets of the modalities. By solving a masked correlation maximization and simultaneously learning an optimal PCI-mask, we identify the latent microstructure of partial common information and leverage it in a self-attention module to selectively weight different feature representations in multi-modal data. We implement our proposed framework on the standard U-Net. Our experimental results on the Multi-modal Brain Tumor Segmentation Challenge (BraTS) datasets consistently outperform those of state-of-the-art segmentation baselines, with validation Dice similarity coefficients of 0.920, 0.897, 0.837 for the whole tumor, tumor core, and enhancing tumor on BraTS-2020.
A Bayesian Optimization Framework for Finding Local Optima in Expensive Multi-Modal Functions
Oct 13, 2022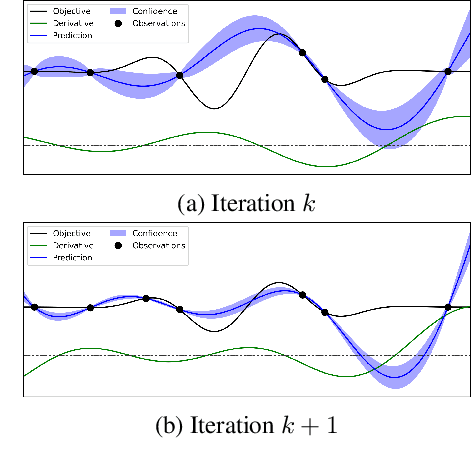
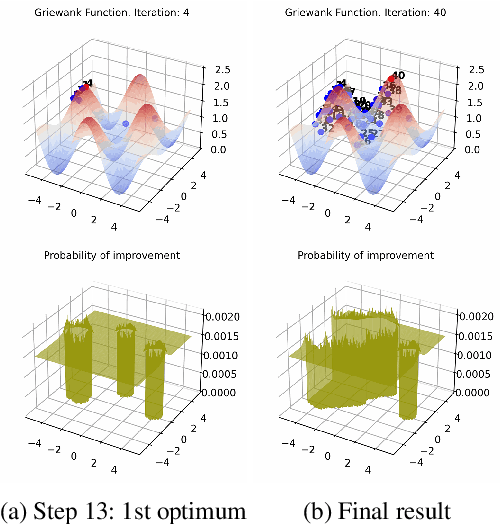
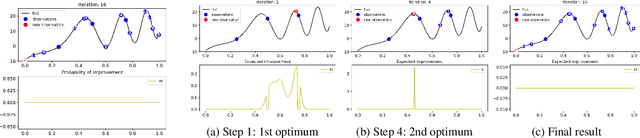
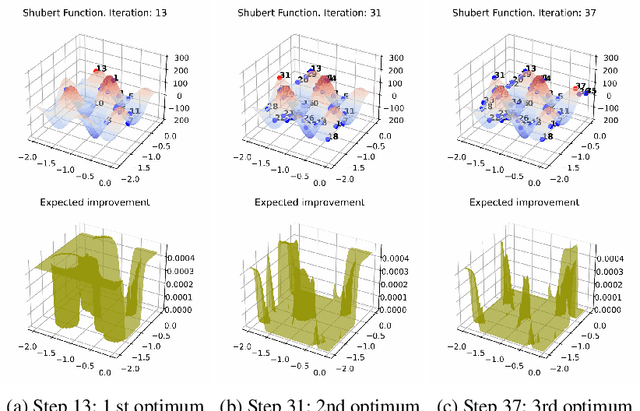
Bayesian optimization (BO) is a popular global optimization scheme for sample-efficient optimization in domains with expensive function evaluations. The existing BO techniques are capable of finding a single global optimum solution. However, finding a set of global and local optimum solutions is crucial in a wide range of real-world problems, as implementing some of the optimal solutions might not be feasible due to various practical restrictions (e.g., resource limitation, physical constraints, etc.). In such domains, if multiple solutions are known, the implementation can be quickly switched to another solution, and the best possible system performance can still be obtained. This paper develops a multi-modal BO framework to effectively find a set of local/global solutions for expensive-to-evaluate multi-modal objective functions. We consider the standard BO setting with Gaussian process regression representing the objective function. We analytically derive the joint distribution of the objective function and its first-order gradients. This joint distribution is used in the body of the BO acquisition functions to search for local optima during the optimization process. We introduce variants of the well-known BO acquisition functions to the multi-modal setting and demonstrate the performance of the proposed framework in locating a set of local optimum solutions using multiple optimization problems.