 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRGMDT: Return-Gap-Minimizing Decision Tree Extraction in Non-Euclidean Metric Space
Paper and Code
Oct 21, 2024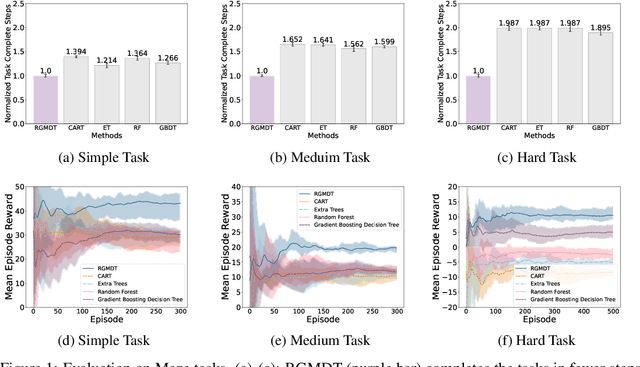

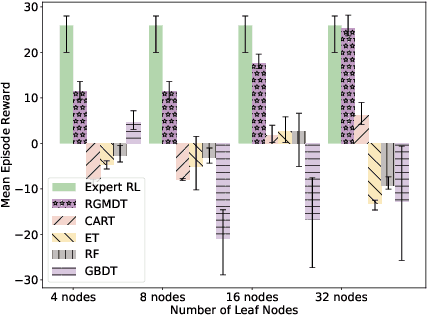

Deep Reinforcement Learning (DRL) algorithms have achieved great success in solving many challenging tasks while their black-box nature hinders interpretability and real-world applicability, making it difficult for human experts to interpret and understand DRL policies. Existing works on interpretable reinforcement learning have shown promise in extracting decision tree (DT) based policies from DRL policies with most focus on the single-agent settings while prior attempts to introduce DT policies in multi-agent scenarios mainly focus on heuristic designs which do not provide any quantitative guarantees on the expected return. In this paper, we establish an upper bound on the return gap between the oracle expert policy and an optimal decision tree policy. This enables us to recast the DT extraction problem into a novel non-euclidean clustering problem over the local observation and action values space of each agent, with action values as cluster labels and the upper bound on the return gap as clustering loss. Both the algorithm and the upper bound are extended to multi-agent decentralized DT extractions by an iteratively-grow-DT procedure guided by an action-value function conditioned on the current DTs of other agents. Further, we propose the Return-Gap-Minimization Decision Tree (RGMDT) algorithm, which is a surprisingly simple design and is integrated with reinforcement learning through the utilization of a novel Regularized Information Maximization loss. Evaluations on tasks like D4RL show that RGMDT significantly outperforms heuristic DT-based baselines and can achieve nearly optimal returns under given DT complexity constraints (e.g., maximum number of DT nodes).