 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Powered Decentralized Generative Agents with Adaptive Hierarchical Knowledge Graph for Cooperative Planning
Feb 08, 2025Developing intelligent agents for long-term cooperation in dynamic open-world scenarios is a major challenge in multi-agent systems. Traditional Multi-agent Reinforcement Learning (MARL) frameworks like centralized training decentralized execution (CTDE) struggle with scalability and flexibility. They require centralized long-term planning, which is difficult without custom reward functions, and face challenges in processing multi-modal data. CTDE approaches also assume fixed cooperation strategies, making them impractical in dynamic environments where agents need to adapt and plan independently. To address decentralized multi-agent cooperation, we propose Decentralized Adaptive Knowledge Graph Memory and Structured Communication System (DAMCS) in a novel Multi-agent Crafter environment. Our generative agents, powered by Large Language Models (LLMs), are more scalable than traditional MARL agents by leveraging external knowledge and language for long-term planning and reasoning. Instead of fully sharing information from all past experiences, DAMCS introduces a multi-modal memory system organized as a hierarchical knowledge graph and a structured communication protocol to optimize agent cooperation. This allows agents to reason from past interactions and share relevant information efficiently. Experiments on novel multi-agent open-world tasks show that DAMCS outperforms both MARL and LLM baselines in task efficiency and collaboration. Compared to single-agent scenarios, the two-agent scenario achieves the same goal with 63% fewer steps, and the six-agent scenario with 74% fewer steps, highlighting the importance of adaptive memory and structured communication in achieving long-term goals. We publicly release our project at: https://happyeureka.github.io/damcs.
RGMDT: Return-Gap-Minimizing Decision Tree Extraction in Non-Euclidean Metric Space
Oct 21, 2024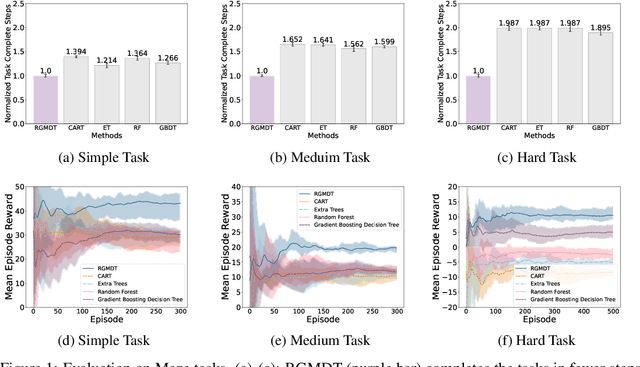

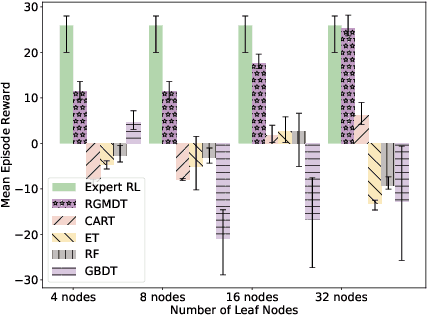

Deep Reinforcement Learning (DRL) algorithms have achieved great success in solving many challenging tasks while their black-box nature hinders interpretability and real-world applicability, making it difficult for human experts to interpret and understand DRL policies. Existing works on interpretable reinforcement learning have shown promise in extracting decision tree (DT) based policies from DRL policies with most focus on the single-agent settings while prior attempts to introduce DT policies in multi-agent scenarios mainly focus on heuristic designs which do not provide any quantitative guarantees on the expected return. In this paper, we establish an upper bound on the return gap between the oracle expert policy and an optimal decision tree policy. This enables us to recast the DT extraction problem into a novel non-euclidean clustering problem over the local observation and action values space of each agent, with action values as cluster labels and the upper bound on the return gap as clustering loss. Both the algorithm and the upper bound are extended to multi-agent decentralized DT extractions by an iteratively-grow-DT procedure guided by an action-value function conditioned on the current DTs of other agents. Further, we propose the Return-Gap-Minimization Decision Tree (RGMDT) algorithm, which is a surprisingly simple design and is integrated with reinforcement learning through the utilization of a novel Regularized Information Maximization loss. Evaluations on tasks like D4RL show that RGMDT significantly outperforms heuristic DT-based baselines and can achieve nearly optimal returns under given DT complexity constraints (e.g., maximum number of DT nodes).
Real-time Network Intrusion Detection via Decision Transformers
Dec 17, 2023Many cybersecurity problems that require real-time decision-making based on temporal observations can be abstracted as a sequence modeling problem, e.g., network intrusion detection from a sequence of arriving packets. Existing approaches like reinforcement learning may not be suitable for such cybersecurity decision problems, since the Markovian property may not necessarily hold and the underlying network states are often not observable. In this paper, we cast the problem of real-time network intrusion detection as casual sequence modeling and draw upon the power of the transformer architecture for real-time decision-making. By conditioning a causal decision transformer on past trajectories, consisting of the rewards, network packets, and detection decisions, our proposed framework will generate future detection decisions to achieve the desired return. It enables decision transformers to be applied to real-time network intrusion detection, as well as a novel tradeoff between the accuracy and timeliness of detection. The proposed solution is evaluated on public network intrusion detection datasets and outperforms several baseline algorithms using reinforcement learning and sequence modeling, in terms of detection accuracy and timeliness.
RIDE: Real-time Intrusion Detection via Explainable Machine Learning Implemented in a Memristor Hardware Architecture
Nov 27, 2023
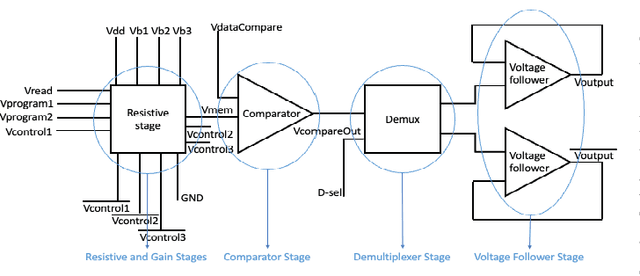


Deep Learning (DL) based methods have shown great promise in network intrusion detection by identifying malicious network traffic behavior patterns with high accuracy, but their applications to real-time, packet-level detections in high-speed communication networks are challenging due to the high computation time and resource requirements of Deep Neural Networks (DNNs), as well as lack of explainability. To this end, we propose a packet-level network intrusion detection solution that makes novel use of Recurrent Autoencoders to integrate an arbitrary-length sequence of packets into a more compact joint feature embedding, which is fed into a DNN-based classifier. To enable explainability and support real-time detections at micro-second speed, we further develop a Software-Hardware Co-Design approach to efficiently realize the proposed solution by converting the learned detection policies into decision trees and implementing them using an emerging architecture based on memristor devices. By jointly optimizing associated software and hardware constraints, we show that our approach leads to an extremely efficient, real-time solution with high detection accuracy at the packet level. Evaluation results on real-world datasets (e.g., UNSW and CIC-IDS datasets) demonstrate nearly three-nines detection accuracy with a substantial speedup of nearly four orders of magnitude.
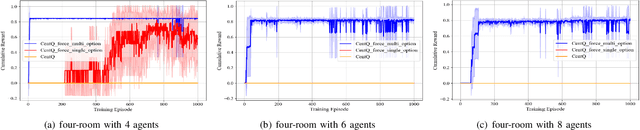
Discrete Message via Online Clustering Labels in Decentralized POMDP
Aug 14, 2023Communication is crucial for solving cooperative Multi-Agent Reinforcement Learning tasks in Partially-Observable Markov Decision Processes. Existing works often rely on black-box methods to encode local information/features into messages shared with other agents. However, such black-box approaches are unable to provide any quantitative guarantees on the expected return and often lead to the generation of continuous messages with high communication overhead and poor interpretability. In this paper, we establish an upper bound on the return gap between an ideal policy with full observability and an optimal partially-observable policy with discrete communication. This result enables us to recast multi-agent communication into a novel online clustering problem over the local observations at each agent, with messages as cluster labels and the upper bound on the return gap as clustering loss. By minimizing the upper bound, we propose a surprisingly simple design of message generation functions in multi-agent communication and integrate it with reinforcement learning using a Regularized Information Maximization loss function. Evaluations show that the proposed discrete communication significantly outperforms state-of-the-art multi-agent communication baselines and can achieve nearly-optimal returns with few-bit messages that are naturally interpretable.
Scalable Multi-agent Skill Discovery based on Kronecker Graphs
Jul 21, 2023Covering skill (a.k.a., option) discovery has been developed to improve the exploration of RL in single-agent scenarios with sparse reward signals, through connecting the most distant states in the embedding space provided by the Fiedler vector of the state transition graph. Given that joint state space grows exponentially with the number of agents in multi-agent systems, existing researches still relying on single-agent option discovery either become prohibitive or fail to directly discover joint options that improve the connectivity of the joint state space. In this paper, we show how to directly compute multi-agent options with collaborative exploratory behaviors while still enjoying the ease of decomposition. Our key idea is to approximate the joint state space as a Kronecker graph, based on which we can directly estimate its Fiedler vector using the Laplacian spectrum of individual agents' transition graphs. Further, considering that directly computing the Laplacian spectrum is intractable for tasks with infinite-scale state spaces, we further propose a deep learning extension of our method by estimating eigenfunctions through NN-based representation learning techniques. The evaluation on multi-agent tasks built with simulators like Mujoco, shows that the proposed algorithm can successfully identify multi-agent options, and significantly outperforms the state-of-the-art. Codes are available at: https://github.itap.purdue.edu/Clan-labs/Scalable_MAOD_via_KP.
Multi-agent Covering Option Discovery based on Kronecker Product of Factor Graphs
Jan 20, 2022


Covering option discovery has been developed to improve the exploration of reinforcement learning in single-agent scenarios with sparse reward signals, through connecting the most distant states in the embedding space provided by the Fiedler vector of the state transition graph. However, these option discovery methods cannot be directly extended to multi-agent scenarios, since the joint state space grows exponentially with the number of agents in the system. Thus, existing researches on adopting options in multi-agent scenarios still rely on single-agent option discovery and fail to directly discover the joint options that can improve the connectivity of the joint state space of agents. In this paper, we show that it is indeed possible to directly compute multi-agent options with collaborative exploratory behaviors among the agents, while still enjoying the ease of decomposition. Our key idea is to approximate the joint state space as a Kronecker graph -- the Kronecker product of individual agents' state transition graphs, based on which we can directly estimate the Fiedler vector of the joint state space using the Laplacian spectrum of individual agents' transition graphs. This decomposition enables us to efficiently construct multi-agent joint options by encouraging agents to connect the sub-goal joint states which are corresponding to the minimum or maximum values of the estimated joint Fiedler vector. The evaluation based on multi-agent collaborative tasks shows that the proposed algorithm can successfully identify multi-agent options, and significantly outperforms prior works using single-agent options or no options, in terms of both faster exploration and higher cumulative rewards.