 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedSteer: Taming Extreme Gradient Staleness in Federated Learning with Corrective Projections and Caching
Jun 08, 2026Federated learning (FL) is often subject to aggregation variance if clients do not consistently participate in training rounds. While reusing stale model updates from inactive clients is a common technique to reduce this variance, we find that with skewed client participation, the resulting update staleness can become severe enough to destabilize training. To remedy this, we propose FedSteer, a novel method that constructs a gradient subspace from a cache of recent client gradients to serve as a low-dimensional representation of the current optimization landscape. FedSteer projects an active client's true gradient onto this subspace to find a set of optimal coordinates. For an inactive client, FedSteer reuses these coordinates with the now-evolved subspace drifted by other active clients. This process effectively "steers" outdated gradients toward the current global objective. This is complemented by a selective caching strategy that identifies a representative client subset to form the subspace, reducing server memory. Experiments demonstrate that FedSteer significantly outperforms baselines, preventing performance collapse in challenging scenarios while delivering accuracy gains of over 7% in others.
EmCoop: A Framework and Benchmark for Embodied Cooperation Among LLM Agents
Feb 27, 2026Real-world scenarios increasingly require multiple embodied agents to collaborate in dynamic environments under embodied constraints, as many tasks exceed the capabilities of any single agent. Recent advances in large language models (LLMs) enable high-level cognitive coordination through reasoning, planning, and natural language communication. However, fine-grained analyses of how such collaboration emerges, unfolds, and contributes to task success in embodied multi-agent systems are difficult to conduct with existing benchmarks. In this paper, we introduce EmCoop, a benchmark framework for studying cooperation in LLM-based embodied multi-agent systems. Our framework separates a high-level cognitive layer from a low-level embodied interaction layer, allowing us to characterize agent cooperation through their interleaved dynamics over time. Given a cooperation-constrained embodied task, we propose generalizable, process-level metrics that diagnose collaboration quality and failure modes, beyond final task success. We instantiate our framework in two embodied environments that scale to arbitrary numbers of agents and support diverse communication topologies, and use these instantiations to demonstrate how EmCoop enables systematic analysis of cooperation dynamics across team sizes and task settings. The project web page can be found at: https://happyeureka.github.io/emcoop.
Towards Optimal Heterogeneous Client Sampling in Multi-Model Federated Learning
Apr 08, 2025Federated learning (FL) allows edge devices to collaboratively train models without sharing local data. As FL gains popularity, clients may need to train multiple unrelated FL models, but communication constraints limit their ability to train all models simultaneously. While clients could train FL models sequentially, opportunistically having FL clients concurrently train different models -- termed multi-model federated learning (MMFL) -- can reduce the overall training time. Prior work uses simple client-to-model assignments that do not optimize the contribution of each client to each model over the course of its training. Prior work on single-model FL shows that intelligent client selection can greatly accelerate convergence, but na\"ive extensions to MMFL can violate heterogeneous resource constraints at both the server and the clients. In this work, we develop a novel convergence analysis of MMFL with arbitrary client sampling methods, theoretically demonstrating the strengths and limitations of previous well-established gradient-based methods. Motivated by this analysis, we propose MMFL-LVR, a loss-based sampling method that minimizes training variance while explicitly respecting communication limits at the server and reducing computational costs at the clients. We extend this to MMFL-StaleVR, which incorporates stale updates for improved efficiency and stability, and MMFL-StaleVRE, a lightweight variant suitable for low-overhead deployment. Experiments show our methods improve average accuracy by up to 19.1% over random sampling, with only a 5.4% gap from the theoretical optimum (full client participation).
LLM-Powered Decentralized Generative Agents with Adaptive Hierarchical Knowledge Graph for Cooperative Planning
Feb 08, 2025Developing intelligent agents for long-term cooperation in dynamic open-world scenarios is a major challenge in multi-agent systems. Traditional Multi-agent Reinforcement Learning (MARL) frameworks like centralized training decentralized execution (CTDE) struggle with scalability and flexibility. They require centralized long-term planning, which is difficult without custom reward functions, and face challenges in processing multi-modal data. CTDE approaches also assume fixed cooperation strategies, making them impractical in dynamic environments where agents need to adapt and plan independently. To address decentralized multi-agent cooperation, we propose Decentralized Adaptive Knowledge Graph Memory and Structured Communication System (DAMCS) in a novel Multi-agent Crafter environment. Our generative agents, powered by Large Language Models (LLMs), are more scalable than traditional MARL agents by leveraging external knowledge and language for long-term planning and reasoning. Instead of fully sharing information from all past experiences, DAMCS introduces a multi-modal memory system organized as a hierarchical knowledge graph and a structured communication protocol to optimize agent cooperation. This allows agents to reason from past interactions and share relevant information efficiently. Experiments on novel multi-agent open-world tasks show that DAMCS outperforms both MARL and LLM baselines in task efficiency and collaboration. Compared to single-agent scenarios, the two-agent scenario achieves the same goal with 63% fewer steps, and the six-agent scenario with 74% fewer steps, highlighting the importance of adaptive memory and structured communication in achieving long-term goals. We publicly release our project at: https://happyeureka.github.io/damcs.
Fair Concurrent Training of Multiple Models in Federated Learning
Apr 22, 2024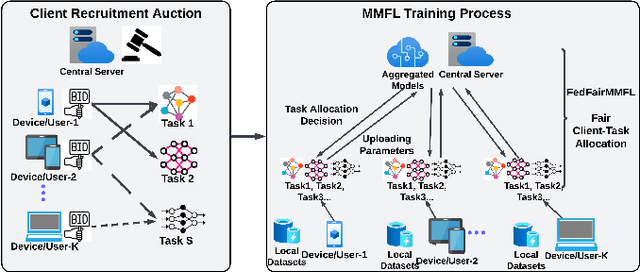
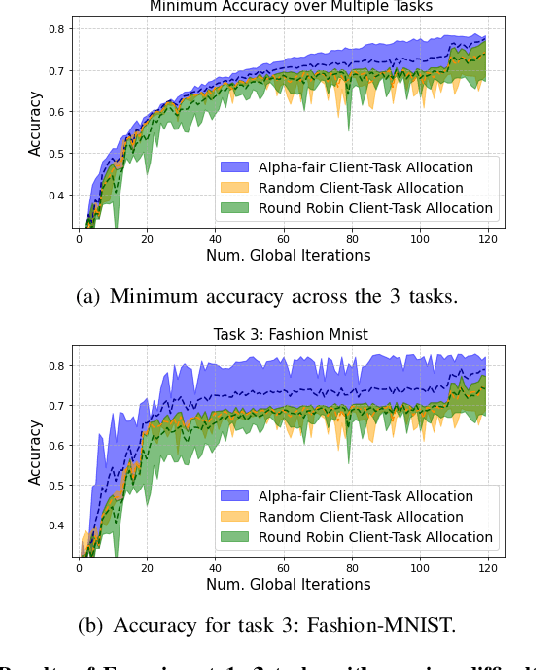
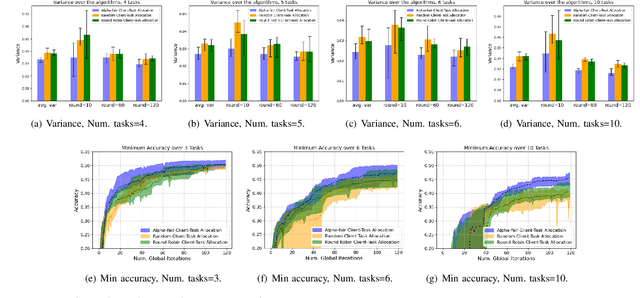
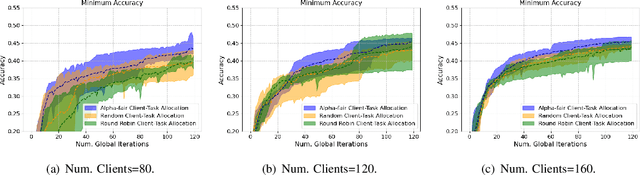
Federated learning (FL) enables collaborative learning across multiple clients. In most FL work, all clients train a single learning task. However, the recent proliferation of FL applications may increasingly require multiple FL tasks to be trained simultaneously, sharing clients' computing and communication resources, which we call Multiple-Model Federated Learning (MMFL). Current MMFL algorithms use naive average-based client-task allocation schemes that can lead to unfair performance when FL tasks have heterogeneous difficulty levels, e.g., tasks with larger models may need more rounds and data to train. Just as naively allocating resources to generic computing jobs with heterogeneous resource needs can lead to unfair outcomes, naive allocation of clients to FL tasks can lead to unfairness, with some tasks having excessively long training times, or lower converged accuracies. Furthermore, in the FL setting, since clients are typically not paid for their training effort, we face a further challenge that some clients may not even be willing to train some tasks, e.g., due to high computational costs, which may exacerbate unfairness in training outcomes across tasks. We address both challenges by firstly designing FedFairMMFL, a difficulty-aware algorithm that dynamically allocates clients to tasks in each training round. We provide guarantees on airness and FedFairMMFL's convergence rate. We then propose a novel auction design that incentivizes clients to train multiple tasks, so as to fairly distribute clients' training efforts across the tasks. We show how our fairness-based learning and incentive mechanisms impact training convergence and finally evaluate our algorithm with multiple sets of learning tasks on real world datasets.
An LLM-Based Digital Twin for Optimizing Human-in-the Loop Systems
Mar 25, 2024



The increasing prevalence of Cyber-Physical Systems and the Internet of Things (CPS-IoT) applications and Foundation Models are enabling new applications that leverage real-time control of the environment. For example, real-time control of Heating, Ventilation and Air-Conditioning (HVAC) systems can reduce its usage when not needed for the comfort of human occupants, hence reducing energy consumption. Collecting real-time feedback on human preferences in such human-in-the-loop (HITL) systems, however, is difficult in practice. We propose the use of large language models (LLMs) to deal with the challenges of dynamic environments and difficult-to-obtain data in CPS optimization. In this paper, we present a case study that employs LLM agents to mimic the behaviors and thermal preferences of various population groups (e.g. young families, the elderly) in a shopping mall. The aggregated thermal preferences are integrated into an agent-in-the-loop based reinforcement learning algorithm AitL-RL, which employs the LLM as a dynamic simulation of the physical environment to learn how to balance between energy savings and occupant comfort. Our results show that LLMs are capable of simulating complex population movements within large open spaces. Besides, AitL-RL demonstrates superior performance compared to the popular existing policy of set point control, suggesting that adaptive and personalized decision-making is critical for efficient optimization in CPS-IoT applications. Through this case study, we demonstrate the potential of integrating advanced Foundation Models like LLMs into CPS-IoT to enhance system adaptability and efficiency. The project's code can be found on our GitHub repository.
Differentially Private Deep Q-Learning for Pattern Privacy Preservation in MEC Offloading
Feb 09, 2023Mobile edge computing (MEC) is a promising paradigm to meet the quality of service (QoS) requirements of latency-sensitive IoT applications. However, attackers may eavesdrop on the offloading decisions to infer the edge server's (ES's) queue information and users' usage patterns, thereby incurring the pattern privacy (PP) issue. Therefore, we propose an offloading strategy which jointly minimizes the latency, ES's energy consumption, and task dropping rate, while preserving PP. Firstly, we formulate the dynamic computation offloading procedure as a Markov decision process (MDP). Next, we develop a Differential Privacy Deep Q-learning based Offloading (DP-DQO) algorithm to solve this problem while addressing the PP issue by injecting noise into the generated offloading decisions. This is achieved by modifying the deep Q-network (DQN) with a Function-output Gaussian process mechanism. We provide a theoretical privacy guarantee and a utility guarantee (learning error bound) for the DP-DQO algorithm and finally, conduct simulations to evaluate the performance of our proposed algorithm by comparing it with greedy and DQN-based algorithms.
FIRE: A Failure-Adaptive Reinforcement Learning Framework for Edge Computing Migrations
Sep 28, 2022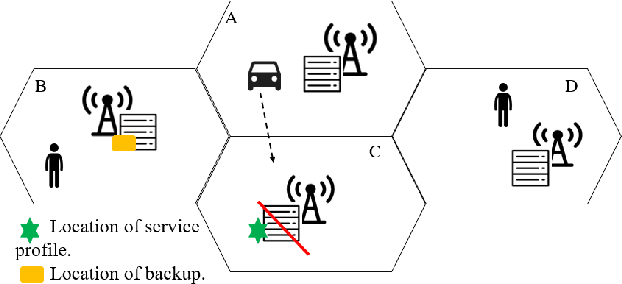
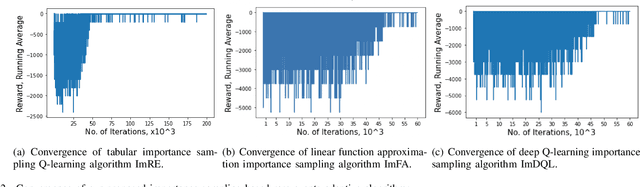
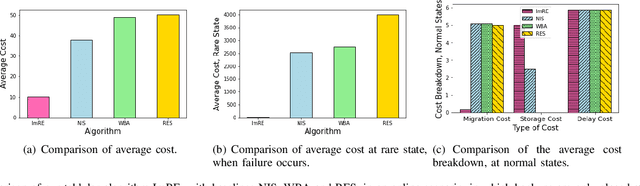
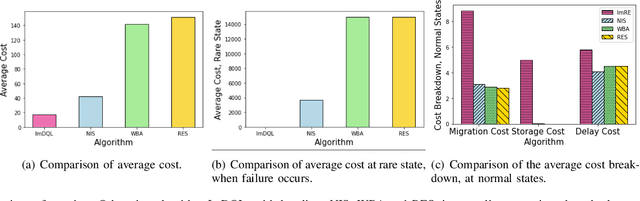
In edge computing, users' service profiles must be migrated in response to user mobility. Reinforcement learning (RL) frameworks have been proposed to do so. Nevertheless, these frameworks do not consider occasional server failures, which although rare, can prevent the smooth and safe functioning of edge computing users' latency sensitive applications such as autonomous driving and real-time obstacle detection, because users' computing jobs can no longer be completed. As these failures occur at a low probability, it is difficult for RL algorithms, which are inherently data-driven, to learn an optimal service migration solution for both the typical and rare event scenarios. Therefore, we introduce a rare events adaptive resilience framework FIRE, which integrates importance sampling into reinforcement learning to place backup services. We sample rare events at a rate proportional to their contribution to the value function, to learn an optimal policy. Our framework balances service migration trade-offs between delay and migration costs, with the costs of failure and the costs of backup placement and migration. We propose an importance sampling based Q-learning algorithm, and prove its boundedness and convergence to optimality. Following which we propose novel eligibility traces, linear function approximation and deep Q-learning versions of our algorithm to ensure it scales to real-world scenarios. We extend our framework to cater to users with different risk tolerances towards failure. Finally, we use trace driven experiments to show that our algorithm gives cost reductions in the event of failures.