 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimilarity-Aware Mixture-of-Experts for Data-Efficient Continual Learning
Mar 24, 2026Machine learning models often need to adapt to new data after deployment due to structured or unstructured real-world dynamics. The Continual Learning (CL) framework enables continuous model adaptation, but most existing approaches either assume each task contains sufficiently many data samples or that the learning tasks are non-overlapping. In this paper, we address the more general setting where each task may have a limited dataset, and tasks may overlap in an arbitrary manner without a priori knowledge. This general setting is substantially more challenging for two reasons. On the one hand, data scarcity necessitates effective contextualization of general knowledge and efficient knowledge transfer across tasks. On the other hand, unstructured task overlapping can easily result in negative knowledge transfer. To address the above challenges, we propose an adaptive mixture-of-experts (MoE) framework over pre-trained models that progressively establishes similarity awareness among tasks. Our design contains two innovative algorithmic components: incremental global pooling and instance-wise prompt masking. The former mitigates prompt association noise through gradual prompt introduction over time. The latter decomposes incoming task samples into those aligning with current prompts (in-distribution) and those requiring new prompts (out-of-distribution). Together, our design strategically leverages potential task overlaps while actively preventing negative mutual interference in the presence of per-task data scarcity. Experiments across varying data volumes and inter-task similarity show that our method enhances sample efficiency and is broadly applicable.
Latent Dynamics-Aware OOD Monitoring for Trajectory Prediction with Provable Guarantees
Mar 15, 2026In safety-critical Cyber-Physical Systems (CPS), accurate trajectory prediction provides vital guidance for downstream planning and control, yet although deep learning models achieve high-fidelity forecasts on validation data, their reliability degrades under out-of-distribution (OOD) scenarios caused by environmental uncertainty or rare traffic behaviors in real-world deployment; detecting such OOD events is challenging due to evolving traffic conditions and changing interaction patterns, while safety-critical applications demand formal guarantees on detection delay and false-alarm rates, motivating us-following recent work [1]-to formulate OOD monitoring for trajectory prediction as a quickest changepoint detection (QCD) problem that offers a principled statistical framework with established theory; we further observe that the real-world evolution of prediction errors under in-distribution (ID) conditions can be effectively modeled by a Hidden Markov Model (HMM), and by leveraging this structure we extend the cumulative Maximum Mean Discrepancy approach to enable detection without requiring explicit knowledge of the post-change distribution while still admitting provable guarantees on delay and false alarms, with experiments on three real-world driving datasets demonstrating reduced detection delay and robustness to heavy-tailed errors and unknown post-change conditions.
Personalized Multi-Agent Average Reward TD-Learning via Joint Linear Approximation
Mar 02, 2026We study personalized multi-agent average reward TD learning, in which a collection of agents interacts with different environments and jointly learns their respective value functions. We focus on the setting where there exists a shared linear representation, and the agents' optimal weights collectively lie in an unknown linear subspace. Inspired by the recent success of personalized federated learning (PFL), we study the convergence of cooperative single-timescale TD learning in which agents iteratively estimate the common subspace and local heads. We showed that this decomposition can filter out conflicting signals, effectively mitigating the negative impacts of ``misaligned'' signals, and achieving linear speedup. The main technical challenges lie in the heterogeneity, the Markovian sampling, and their intricate interplay in shaping error evolutions. Specifically, not only are the error dynamics of multiple variables closely interconnected, but there is also no direct contraction for the principal angle distance between the optimal subspace and the estimated subspace. We hope our analytical techniques can be useful to inspire research on deeper exploration into leveraging common structures. Experiments are provided to show the benefits of learning via a shared structure to the more general control problem.
On the Power of Source Screening for Learning Shared Feature Extractors
Feb 18, 2026Learning with shared representation is widely recognized as an effective way to separate commonalities from heterogeneity across various heterogeneous sources. Most existing work includes all related data sources via simultaneously training a common feature extractor and source-specific heads. It is well understood that data sources with low relevance or poor quality may hinder representation learning. In this paper, we further dive into the question of which data sources should be learned jointly by focusing on the traditionally deemed ``good'' collection of sources, in which individual sources have similar relevance and qualities with respect to the true underlying common structure. Towards tractability, we focus on the linear setting where sources share a low-dimensional subspace. We find that source screening can play a central role in statistically optimal subspace estimation. We show that, for a broad class of problem instances, training on a carefully selected subset of sources suffices to achieve minimax optimality, even when a substantial portion of data is discarded. We formalize the notion of an informative subpopulation, develop algorithms and practical heuristics for identifying such subsets, and validate their effectiveness through both theoretical analysis and empirical evaluations on synthetic and real-world datasets.
Personalized Federated Learning via Feature Distribution Adaptation
Nov 01, 2024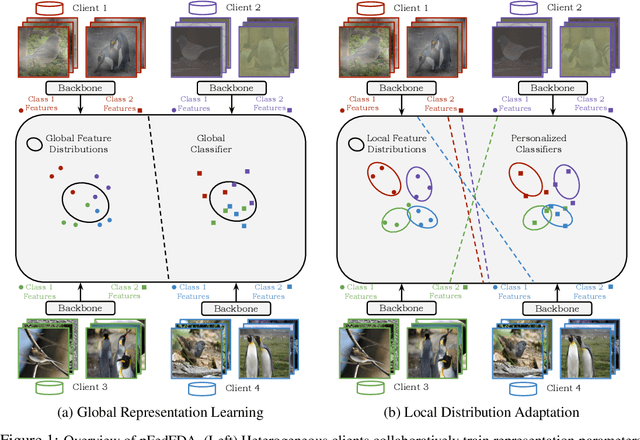
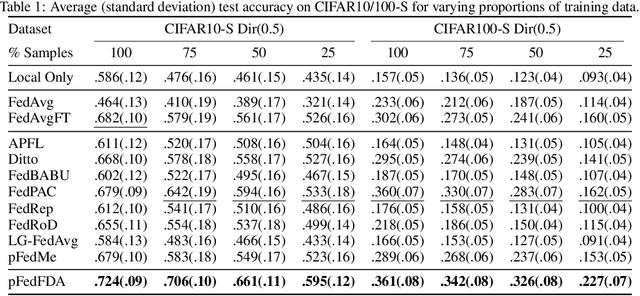
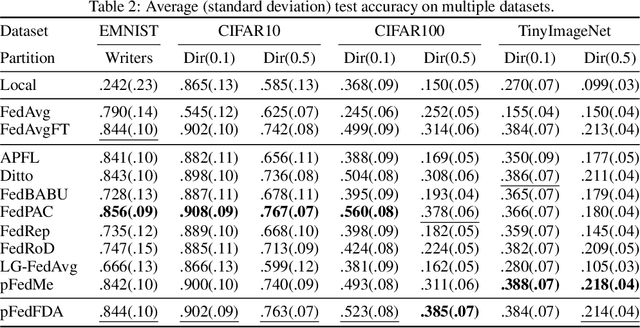
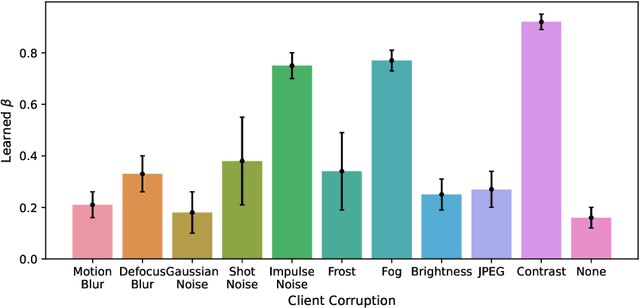
Federated learning (FL) is a distributed learning framework that leverages commonalities between distributed client datasets to train a global model. Under heterogeneous clients, however, FL can fail to produce stable training results. Personalized federated learning (PFL) seeks to address this by learning individual models tailored to each client. One approach is to decompose model training into shared representation learning and personalized classifier training. Nonetheless, previous works struggle to navigate the bias-variance trade-off in classifier learning, relying solely on limited local datasets or introducing costly techniques to improve generalization. In this work, we frame representation learning as a generative modeling task, where representations are trained with a classifier based on the global feature distribution. We then propose an algorithm, pFedFDA, that efficiently generates personalized models by adapting global generative classifiers to their local feature distributions. Through extensive computer vision benchmarks, we demonstrate that our method can adjust to complex distribution shifts with significant improvements over current state-of-the-art in data-scarce settings.
Non-transferable Pruning
Oct 10, 2024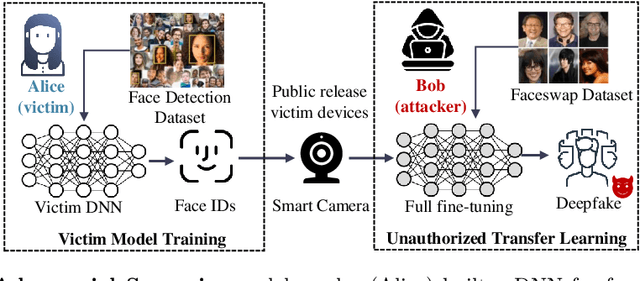
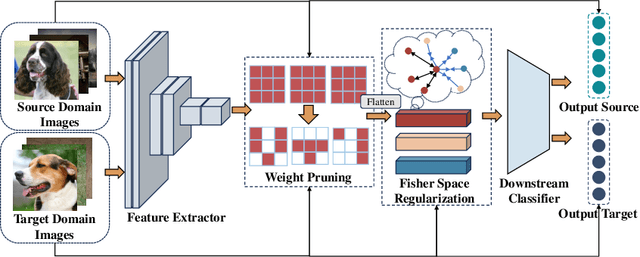
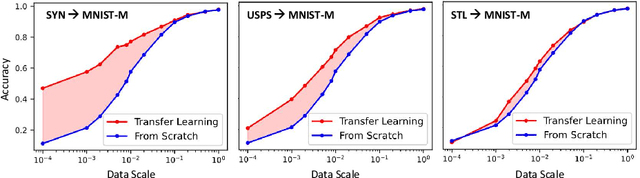
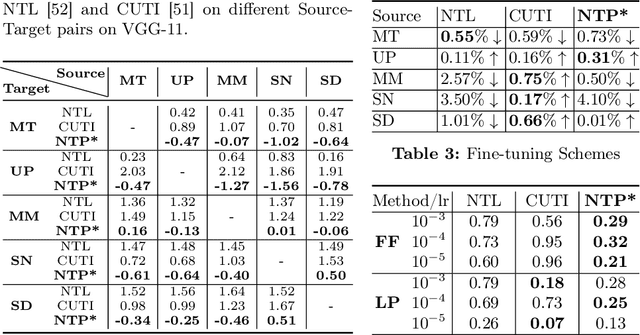
Pretrained Deep Neural Networks (DNNs), developed from extensive datasets to integrate multifaceted knowledge, are increasingly recognized as valuable intellectual property (IP). To safeguard these models against IP infringement, strategies for ownership verification and usage authorization have emerged. Unlike most existing IP protection strategies that concentrate on restricting direct access to the model, our study addresses an extended DNN IP issue: applicability authorization, aiming to prevent the misuse of learned knowledge, particularly in unauthorized transfer learning scenarios. We propose Non-Transferable Pruning (NTP), a novel IP protection method that leverages model pruning to control a pretrained DNN's transferability to unauthorized data domains. Selective pruning can deliberately diminish a model's suitability on unauthorized domains, even with full fine-tuning. Specifically, our framework employs the alternating direction method of multipliers (ADMM) for optimizing both the model sparsity and an innovative non-transferable learning loss, augmented with Fisher space discriminative regularization, to constrain the model's generalizability to the target dataset. We also propose a novel effective metric to measure the model non-transferability: Area Under the Sample-wise Learning Curve (SLC-AUC). This metric facilitates consideration of full fine-tuning across various sample sizes. Experimental results demonstrate that NTP significantly surpasses the state-of-the-art non-transferable learning methods, with an average SLC-AUC at $-0.54$ across diverse pairs of source and target domains, indicating that models trained with NTP do not suit for transfer learning to unauthorized target domains. The efficacy of NTP is validated in both supervised and self-supervised learning contexts, confirming its applicability in real-world scenarios.
Efficient Federated Learning against Heterogeneous and Non-stationary Client Unavailability
Sep 26, 2024
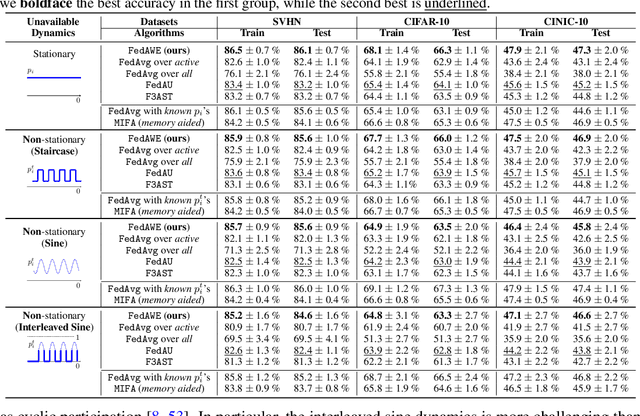
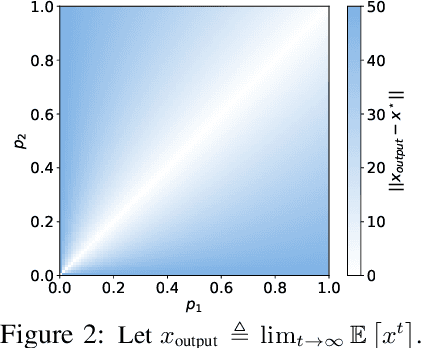

Addressing intermittent client availability is critical for the real-world deployment of federated learning algorithms. Most prior work either overlooks the potential non-stationarity in the dynamics of client unavailability or requires substantial memory/computation overhead. We study federated learning in the presence of heterogeneous and non-stationary client availability, which may occur when the deployment environments are uncertain or the clients are mobile. The impacts of the heterogeneity and non-stationarity in client unavailability can be significant, as we illustrate using FedAvg, the most widely adopted federated learning algorithm. We propose FedAPM, which includes novel algorithmic structures that (i) compensate for missed computations due to unavailability with only $O(1)$ additional memory and computation with respect to standard FedAvg, and (ii) evenly diffuse local updates within the federated learning system through implicit gossiping, despite being agnostic to non-stationary dynamics. We show that FedAPM converges to a stationary point of even non-convex objectives while achieving the desired linear speedup property. We corroborate our analysis with numerical experiments over diversified client unavailability dynamics on real-world data sets.
Data-efficient Trajectory Prediction via Coreset Selection
Sep 25, 2024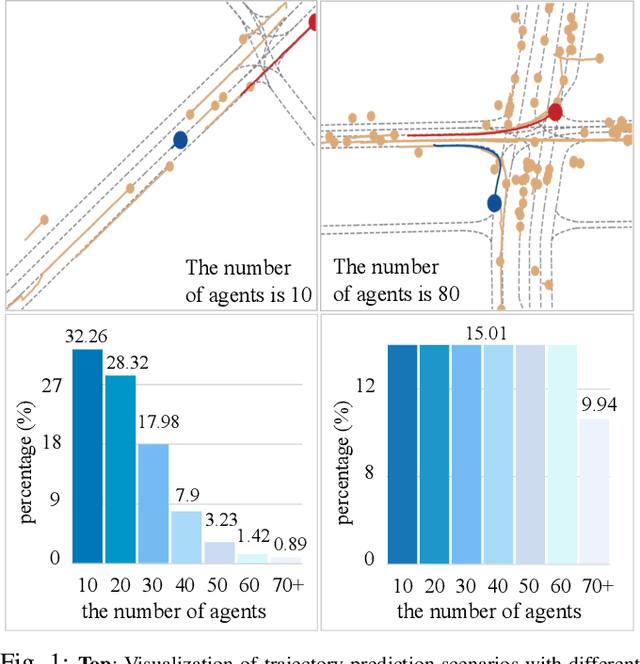
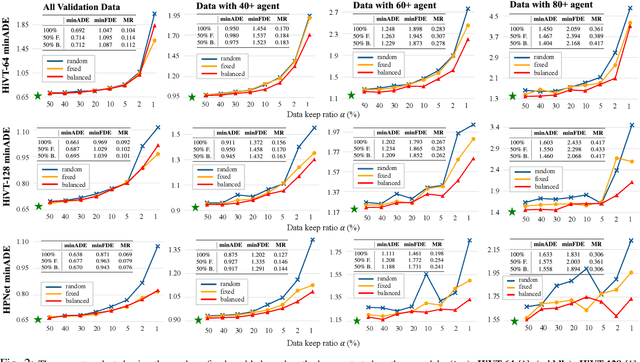
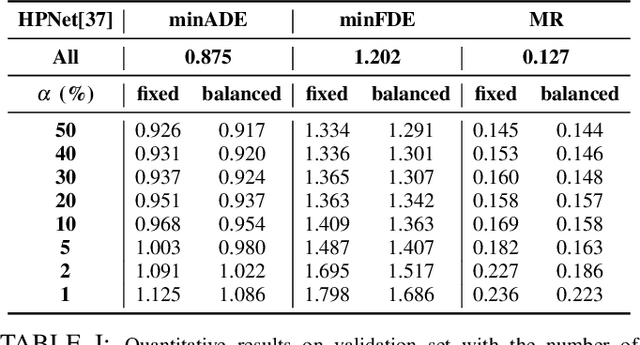
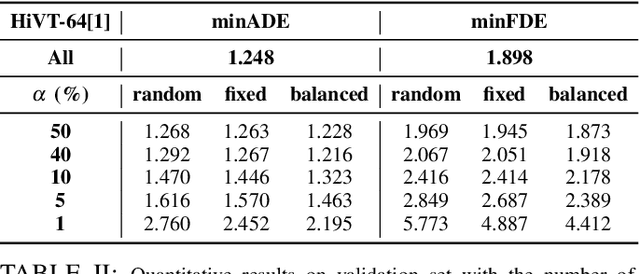
Modern vehicles are equipped with multiple information-collection devices such as sensors and cameras, continuously generating a large volume of raw data. Accurately predicting the trajectories of neighboring vehicles is a vital component in understanding the complex driving environment. Yet, training trajectory prediction models is challenging in two ways. Processing the large-scale data is computation-intensive. Moreover, easy-medium driving scenarios often overwhelmingly dominate the dataset, leaving challenging driving scenarios such as dense traffic under-represented. For example, in the Argoverse motion prediction dataset, there are very few instances with $\ge 50$ agents, while scenarios with $10 \thicksim 20$ agents are far more common. In this paper, to mitigate data redundancy in the over-represented driving scenarios and to reduce the bias rooted in the data scarcity of complex ones, we propose a novel data-efficient training method based on coreset selection. This method strategically selects a small but representative subset of data while balancing the proportions of different scenario difficulties. To the best of our knowledge, we are the first to introduce a method capable of effectively condensing large-scale trajectory dataset, while achieving a state-of-the-art compression ratio. Notably, even when using only 50% of the Argoverse dataset, the model can be trained with little to no decline in performance. Moreover, the selected coreset maintains excellent generalization ability.
Reactive Multi-Robot Navigation in Outdoor Environments Through Uncertainty-Aware Active Learning of Human Preference Landscape
Sep 25, 2024
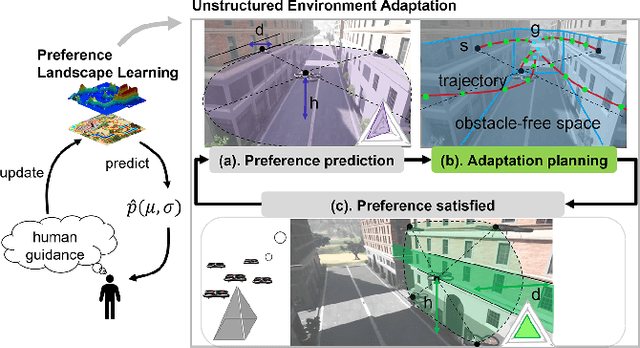
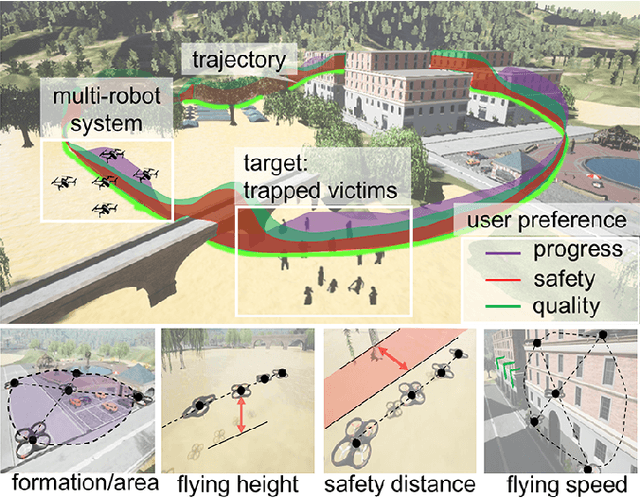
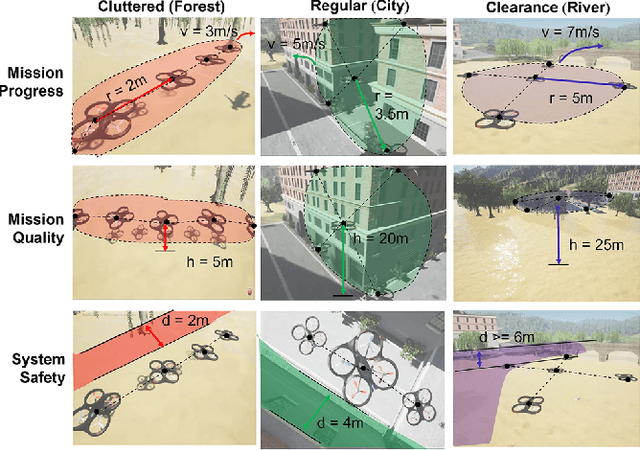
Compared with single robots, Multi-Robot Systems (MRS) can perform missions more efficiently due to the presence of multiple members with diverse capabilities. However, deploying an MRS in wide real-world environments is still challenging due to uncertain and various obstacles (e.g., building clusters and trees). With a limited understanding of environmental uncertainty on performance, an MRS cannot flexibly adjust its behaviors (e.g., teaming, load sharing, trajectory planning) to ensure both environment adaptation and task accomplishments. In this work, a novel joint preference landscape learning and behavior adjusting framework (PLBA) is designed. PLBA efficiently integrates real-time human guidance to MRS coordination and utilizes Sparse Variational Gaussian Processes with Varying Output Noise to quickly assess human preferences by leveraging spatial correlations between environment characteristics. An optimization-based behavior-adjusting method then safely adapts MRS behaviors to environments. To validate PLBA's effectiveness in MRS behavior adaption, a flood disaster search and rescue task was designed. 20 human users provided 1764 feedback based on human preferences obtained from MRS behaviors related to "task quality", "task progress", "robot safety". The prediction accuracy and adaptation speed results show the effectiveness of PLBA in preference learning and MRS behavior adaption.
Building Real-time Awareness of Out-of-distribution in Trajectory Prediction for Autonomous Vehicles
Sep 25, 2024



Trajectory prediction describes the motions of surrounding moving obstacles for an autonomous vehicle; it plays a crucial role in enabling timely decision-making, such as collision avoidance and trajectory replanning. Accurate trajectory planning is the key to reliable vehicle deployments in open-world environment, where unstructured obstacles bring in uncertainties that are impossible to fully capture by training data. For traditional machine learning tasks, such uncertainties are often addressed reasonably well via methods such as continual learning. On the one hand, naively applying those methods to trajectory prediction can result in continuous data collection and frequent model updates, which can be resource-intensive. On the other hand, the predicted trajectories can be far away from the true trajectories, leading to unsafe decision-making. In this paper, we aim to establish real-time awareness of out-of-distribution in trajectory prediction for autonomous vehicles. We focus on the challenging and practically relevant setting where the out-of-distribution is deceptive, that is, the one not easily detectable by human intuition. Drawing on the well-established techniques of sequential analysis, we build real-time awareness of out-of-distribution by monitoring prediction errors using the quickest change point detection (QCD). Our solutions are lightweight and can handle the occurrence of out-of-distribution at any time during trajectory prediction inference. Experimental results on multiple real-world datasets using a benchmark trajectory prediction model demonstrate the effectiveness of our methods.