 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgenuReasoning: A Reasoning-Centric Dataset and Benchmark for Long-Tail Autonomous Driving
May 29, 2026Reasoning is essential for autonomous driving (AD) in long-tail scenarios, where vehicles must apply commonsense knowledge, understand spatial relations, infer agent interactions, and make safe decisions. However, existing AD datasets and benchmarks mainly target perception, prediction, or planning, and provide limited supervision for reasoning over realistic long-tail driving scenes. We introduce nuReasoning, a large-scale real-world dataset and benchmark for reasoning-centric AD. Following the lineage of nuScenes and nuPlan, nuReasoning advances real-world AD datasets and benchmarks toward reasoning in long-tail driving scenarios. The dataset contains 20,000 clips, each 20 seconds long, collected across multiple cities, with synchronized multi-camera images, LiDAR data, HD maps, object annotations, and human-verified reasoning annotations spanning Spatial Reasoning, Decision Reasoning, and Counterfactual Reasoning. Unlike prior datasets that focus primarily on visual question answering, nuReasoning supports both reasoning evaluation and planning evaluation, enabling a direct study of how reasoning supervision affects driving performance. Experiments show that fine-tuning VLMs on nuReasoning substantially improves driving-specific question answering, while incorporating reasoning supervision into VLA training improves planning performance even when textual reasoning outputs are disabled at inference time. These results establish nuReasoning as a foundation for evaluating and improving robust, interpretable, reasoning-driven AD systems in realistic long-tail settings.
SpanVLA: Efficient Action Bridging and Learning from Negative-Recovery Samples for Vision-Language-Action Model
Apr 21, 2026Vision-Language-Action (VLA) models offer a promising autonomous driving paradigm for leveraging world knowledge and reasoning capabilities, especially in long-tail scenarios. However, existing VLA models often struggle with the high latency in action generation using an autoregressive generation framework and exhibit limited robustness. In this paper, we propose SpanVLA, a novel end-to-end autonomous driving framework, integrating an autoregressive reasoning and a flow-matching action expert. First, SpanVLA introduces an efficient bridge to leverage the vision and reasoning guidance of VLM to efficiently plan future trajectories using a flow-matching policy conditioned on historical trajectory initialization, which significantly reduces inference time. Second, to further improve the performance and robustness of the SpanVLA model, we propose a GRPO-based post-training method to enable the VLA model not only to learn from positive driving samples but also to learn how to avoid the typical negative behaviors and learn recovery behaviors. We further introduce mReasoning, a new real-world driving reasoning dataset, focusing on complex, reasoning-demanding scenarios and negative-recovery samples. Extensive experiments on the NAVSIM (v1 and v2) demonstrate the competitive performance of the SpanVLA model. Additionally, the qualitative results across diverse scenarios highlight the planning performance and robustness of our model.
Bipartite Mode Matching for Vision Training Set Search from a Hierarchical Data Server
Jan 14, 2026We explore a situation in which the target domain is accessible, but real-time data annotation is not feasible. Instead, we would like to construct an alternative training set from a large-scale data server so that a competitive model can be obtained. For this problem, because the target domain usually exhibits distinct modes (i.e., semantic clusters representing data distribution), if the training set does not contain these target modes, the model performance would be compromised. While prior existing works improve algorithms iteratively, our research explores the often-overlooked potential of optimizing the structure of the data server. Inspired by the hierarchical nature of web search engines, we introduce a hierarchical data server, together with a bipartite mode matching algorithm (BMM) to align source and target modes. For each target mode, we look in the server data tree for the best mode match, which might be large or small in size. Through bipartite matching, we aim for all target modes to be optimally matched with source modes in a one-on-one fashion. Compared with existing training set search algorithms, we show that the matched server modes constitute training sets that have consistently smaller domain gaps with the target domain across object re-identification (re-ID) and detection tasks. Consequently, models trained on our searched training sets have higher accuracy than those trained otherwise. BMM allows data-centric unsupervised domain adaptation (UDA) orthogonal to existing model-centric UDA methods. By combining the BMM with existing UDA methods like pseudo-labeling, further improvement is observed.
Unsupervised Search for Ethnic Minorities' Medical Segmentation Training Set
Jan 05, 2025



This article investigates the critical issue of dataset bias in medical imaging, with a particular emphasis on racial disparities caused by uneven population distribution in dataset collection. Our analysis reveals that medical segmentation datasets are significantly biased, primarily influenced by the demographic composition of their collection sites. For instance, Scanning Laser Ophthalmoscopy (SLO) fundus datasets collected in the United States predominantly feature images of White individuals, with minority racial groups underrepresented. This imbalance can result in biased model performance and inequitable clinical outcomes, particularly for minority populations. To address this challenge, we propose a novel training set search strategy aimed at reducing these biases by focusing on underrepresented racial groups. Our approach utilizes existing datasets and employs a simple greedy algorithm to identify source images that closely match the target domain distribution. By selecting training data that aligns more closely with the characteristics of minority populations, our strategy improves the accuracy of medical segmentation models on specific minorities, i.e., Black. Our experimental results demonstrate the effectiveness of this approach in mitigating bias. We also discuss the broader societal implications, highlighting how addressing these disparities can contribute to more equitable healthcare outcomes.
Data-efficient Trajectory Prediction via Coreset Selection
Sep 25, 2024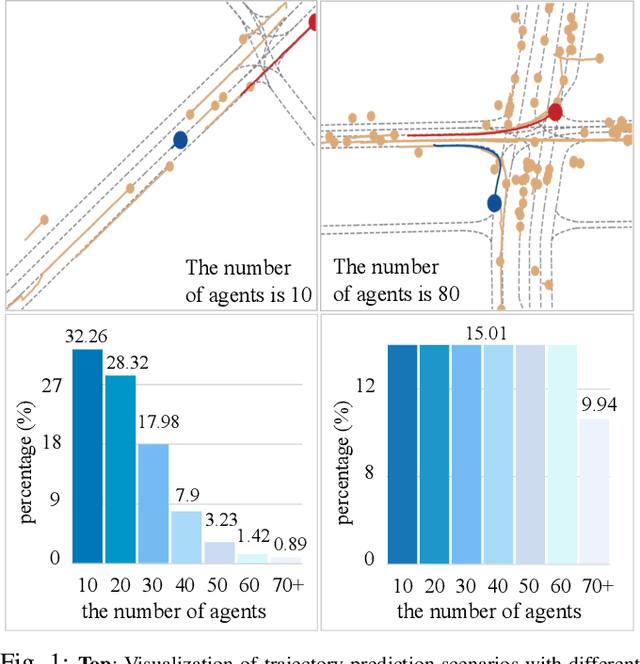
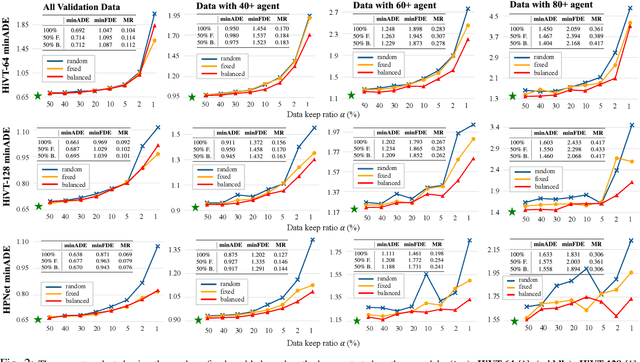
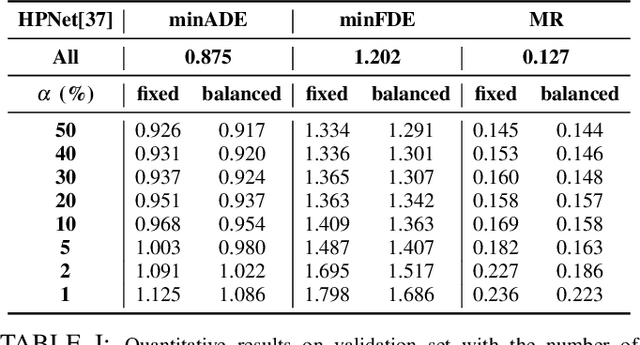
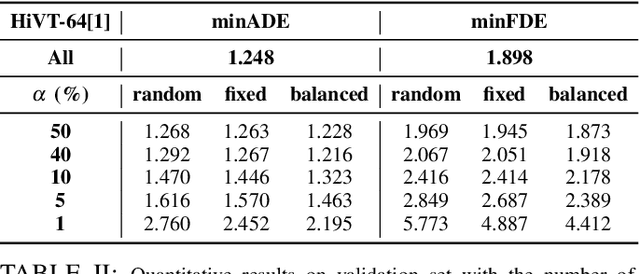
Modern vehicles are equipped with multiple information-collection devices such as sensors and cameras, continuously generating a large volume of raw data. Accurately predicting the trajectories of neighboring vehicles is a vital component in understanding the complex driving environment. Yet, training trajectory prediction models is challenging in two ways. Processing the large-scale data is computation-intensive. Moreover, easy-medium driving scenarios often overwhelmingly dominate the dataset, leaving challenging driving scenarios such as dense traffic under-represented. For example, in the Argoverse motion prediction dataset, there are very few instances with $\ge 50$ agents, while scenarios with $10 \thicksim 20$ agents are far more common. In this paper, to mitigate data redundancy in the over-represented driving scenarios and to reduce the bias rooted in the data scarcity of complex ones, we propose a novel data-efficient training method based on coreset selection. This method strategically selects a small but representative subset of data while balancing the proportions of different scenario difficulties. To the best of our knowledge, we are the first to introduce a method capable of effectively condensing large-scale trajectory dataset, while achieving a state-of-the-art compression ratio. Notably, even when using only 50% of the Argoverse dataset, the model can be trained with little to no decline in performance. Moreover, the selected coreset maintains excellent generalization ability.
PLoc: A New Evaluation Criterion Based on Physical Location for Autonomous Driving Datasets
Mar 29, 2024Autonomous driving has garnered significant attention as a key research area within artificial intelligence. In the context of autonomous driving scenarios, the varying physical locations of objects correspond to different levels of danger. However, conventional evaluation criteria for automatic driving object detection often overlook the crucial aspect of an object's physical location, leading to evaluation results that may not accurately reflect the genuine threat posed by the object to the autonomous driving vehicle. To enhance the safety of autonomous driving, this paper introduces a novel evaluation criterion based on physical location information, termed PLoc. This criterion transcends the limitations of traditional criteria by acknowledging that the physical location of pedestrians in autonomous driving scenarios can provide valuable safety-related information. Furthermore, this paper presents a newly re-annotated dataset (ApolloScape-R) derived from ApolloScape. ApolloScape-R involves the relabeling of pedestrians based on the significance of their physical location. The dataset is utilized to assess the performance of various object detection models under the proposed PLoc criterion. Experimental results demonstrate that the average accuracy of all object detection models in identifying a person situated in the travel lane of an autonomous vehicle is lower than that for a person on a sidewalk. The dataset is publicly available at https://github.com/lnyrlyed/ApolloScape-R.git