 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMBU: A Massive Multi-modal Biomedical Understanding Benchmark to Probe the Perception Capabilities of Vision-Language Models
Jun 04, 2026Vision and language models (VLMs) hold immense promise to transform biomedical imaging workflows, from detecting lesions in chest X-rays to profiling cellular features in microscopy. Realizing this potential, however, requires robust and fine-grained visual perception. Models need to correctly interpret subtle features in images, and they must do so across diverse biomedical modalities, scales, and contexts. Nevertheless, current benchmarks remain limited. To address these gaps, we introduce the Massive Multimodal Biomedical Understanding (MMBU) benchmark. It is the largest biomedical vision and language benchmark to date, covering 35 submodalities with rich structured metadata. It includes both open and closed versions of ungrounded classification, grounded classification, and object detection, enabling systematic evaluation of model performance across biological scales, clinical settings, and imaging modalities. Evaluating 15 open-weight and 2 frontier VLMs, we find that while medical adaptation provides measurable gains for some models, the high accuracy often reported on established benchmarks can mask deficiencies in visual perception and domain generalization.
Mobile GUI Agent Privacy Personalization with Trajectory Induced Preference Optimization
Apr 13, 2026Mobile GUI agents powered by Multimodal Large Language Models (MLLMs) can execute complex tasks on mobile devices. Despite this progress, most existing systems still optimize task success or efficiency, neglecting users' privacy personalization. In this paper, we study the often-overlooked problem of agent personalization. We observe that personalization can induce systematic structural heterogeneity in execution trajectories. For example, privacy-first users often prefer protective actions, e.g., refusing permissions, logging out, and minimizing exposure, leading to logically different execution trajectories from utility-first users. Such variable-length and structurally different trajectories make standard preference optimization unstable and less informative. To address this issue, we propose Trajectory Induced Preference Optimization (TIPO), which uses preference-intensity weighting to emphasize key privacy-related steps and padding gating to suppress alignment noise. Results on our Privacy Preference Dataset show that TIPO improves persona alignment and distinction while preserving strong task executability, achieving 65.60% SR, 46.22 Compliance, and 66.67% PD, outperforming existing optimization methods across various GUI tasks. The code and dataset will be publicly released at https://github.com/Zhixin-L/TIPO.
A Utility-preserving De-identification Pipeline for Cross-hospital Radiology Data Sharing
Apr 08, 2026Large-scale radiology data are critical for developing robust medical AI systems. However, sharing such data across hospitals remains heavily constrained by privacy concerns. Existing de-identification research in radiology mainly focus on removing identifiable information to enable compliant data release. Yet whether de-identified radiology data can still preserve sufficient utility for large-scale vision-language model training and cross-hospital transfer remains underexplored. In this paper, we introduce a utility-preserving de-identification pipeline (UPDP) for cross-hospital radiology data sharing. Specifically, we compile a blacklist of privacy-sensitive terms and a whitelist of pathology-related terms. For radiology images, we use a generative filtering mechanism that synthesis a privacy-filtered and pathology-reserved counterparts of the original images. These synthetic image counterparts, together with ID-filtered reports, can then be securely shared across hospitals for downstream model development and evaluation. Experiments on public chest X-ray benchmarks demonstrate that our method effectively removes privacy-sensitive information while preserving diagnostically relevant pathology cues. Models trained on the de-identified data maintain competitive diagnostic accuracy compared with those trained on the original data, while exhibiting a marked decline in identity-related accuracy, confirming effective privacy protection. In the cross-hospital setting, we further show that de-identified data can be combined with local data to yield better performance.
SonoSelect: Efficient Ultrasound Perception via Active Probe Exploration
Apr 07, 2026Ultrasound perception typically requires multiple scan views through probe movement to reduce diagnostic ambiguity, mitigate acoustic occlusions, and improve anatomical coverage. However, not all probe views are equally informative. Exhaustively acquiring a large number of views can introduce substantial redundancy, increase scanning and processing costs. To address this, we define an active view exploration task for ultrasound and propose SonoSelect, an ultrasound-specific method that adaptively guides probe movement based on current observations. Specifically, we cast ultrasound active view exploration as a sequential decision-making problem. Each new 2D ultrasound view is fused into a 3D spatial memory of the observed anatomy, which guides the next probe position. On top of this formulation, we propose an ultrasound-specific objective that favors probe movements with greater organ coverage, lower reconstruction uncertainty, and less redundant scanning. Experiments on the ultrasound simulator show that SonoSelect achieves promising multi-view organ classification accuracy using only 2 out of N views. Furthermore, for a more difficult kidney cyst detection task, it reaches 54.56% kidney coverage and 35.13% cyst coverage, with short trajectories consistently centered on the target cyst.
Project Imaging-X: A Survey of 1000+ Open-Access Medical Imaging Datasets for Foundation Model Development
Mar 29, 2026Foundation models have demonstrated remarkable success across diverse domains and tasks, primarily due to the thrive of large-scale, diverse, and high-quality datasets. However, in the field of medical imaging, the curation and assembling of such medical datasets are highly challenging due to the reliance on clinical expertise and strict ethical and privacy constraints, resulting in a scarcity of large-scale unified medical datasets and hindering the development of powerful medical foundation models. In this work, we present the largest survey to date of medical image datasets, covering over 1,000 open-access datasets with a systematic catalog of their modalities, tasks, anatomies, annotations, limitations, and potential for integration. Our analysis exposes a landscape that is modest in scale, fragmented across narrowly scoped tasks, and unevenly distributed across organs and modalities, which in turn limits the utility of existing medical image datasets for developing versatile and robust medical foundation models. To turn fragmentation into scale, we propose a metadata-driven fusion paradigm (MDFP) that integrates public datasets with shared modalities or tasks, thereby transforming multiple small data silos into larger, more coherent resources. Building on MDFP, we release an interactive discovery portal that enables end-to-end, automated medical image dataset integration, and compile all surveyed datasets into a unified, structured table that clearly summarizes their key characteristics and provides reference links, offering the community an accessible and comprehensive repository. By charting the current terrain and offering a principled path to dataset consolidation, our survey provides a practical roadmap for scaling medical imaging corpora, supporting faster data discovery, more principled dataset creation, and more capable medical foundation models.
Mind the Rarities: Can Rare Skin Diseases Be Reliably Diagnosed via Diagnostic Reasoning?
Mar 19, 2026Large vision-language models (LVLMs) demonstrate strong performance in dermatology; however, evaluating diagnostic reasoning for rare conditions remains largely unexplored. Existing benchmarks focus on common diseases and assess only final accuracy, overlooking the clinical reasoning process, which is critical for complex cases. We address this gap by constructing DermCase, a long-context benchmark derived from peer-reviewed case reports. Our dataset contains 26,030 multi-modal image-text pairs and 6,354 clinically challenging cases, each annotated with comprehensive clinical information and step-by-step reasoning chains. To enable reliable evaluation, we establish DermLIP-based similarity metrics that achieve stronger alignment with dermatologists for assessing differential diagnosis quality. Benchmarking 22 leading LVLMs exposes significant deficiencies across diagnosis accuracy, differential diagnosis, and clinical reasoning. Fine-tuning experiments demonstrate that instruction tuning substantially improves performance while Direct Preference Optimization (DPO) yields minimal gains. Systematic error analysis further reveals critical limitations in current models' reasoning capabilities.
ReTracing: An Archaeological Approach Through Body, Machine, and Generative Systems
Feb 11, 2026We present ReTracing, a multi-agent embodied performance art that adopts an archaeological approach to examine how artificial intelligence shapes, constrains, and produces bodily movement. Drawing from science-fiction novels, the project extracts sentences that describe human-machine interaction. We use large language models (LLMs) to generate paired prompts "what to do" and "what not to do" for each excerpt. A diffusion-based text-to-video model transforms these prompts into choreographic guides for a human performer and motor commands for a quadruped robot. Both agents enact the actions on a mirrored floor, captured by multi-camera motion tracking and reconstructed into 3D point clouds and motion trails, forming a digital archive of motion traces. Through this process, ReTracing serves as a novel approach to reveal how generative systems encode socio-cultural biases through choreographed movements. Through an immersive interplay of AI, human, and robot, ReTracing confronts a critical question of our time: What does it mean to be human among AIs that also move, think, and leave traces behind?
Bipartite Mode Matching for Vision Training Set Search from a Hierarchical Data Server
Jan 14, 2026We explore a situation in which the target domain is accessible, but real-time data annotation is not feasible. Instead, we would like to construct an alternative training set from a large-scale data server so that a competitive model can be obtained. For this problem, because the target domain usually exhibits distinct modes (i.e., semantic clusters representing data distribution), if the training set does not contain these target modes, the model performance would be compromised. While prior existing works improve algorithms iteratively, our research explores the often-overlooked potential of optimizing the structure of the data server. Inspired by the hierarchical nature of web search engines, we introduce a hierarchical data server, together with a bipartite mode matching algorithm (BMM) to align source and target modes. For each target mode, we look in the server data tree for the best mode match, which might be large or small in size. Through bipartite matching, we aim for all target modes to be optimally matched with source modes in a one-on-one fashion. Compared with existing training set search algorithms, we show that the matched server modes constitute training sets that have consistently smaller domain gaps with the target domain across object re-identification (re-ID) and detection tasks. Consequently, models trained on our searched training sets have higher accuracy than those trained otherwise. BMM allows data-centric unsupervised domain adaptation (UDA) orthogonal to existing model-centric UDA methods. By combining the BMM with existing UDA methods like pseudo-labeling, further improvement is observed.
Mind the Third Eye! Benchmarking Privacy Awareness in MLLM-powered Smartphone Agents
Aug 27, 2025



Smartphones bring significant convenience to users but also enable devices to extensively record various types of personal information. Existing smartphone agents powered by Multimodal Large Language Models (MLLMs) have achieved remarkable performance in automating different tasks. However, as the cost, these agents are granted substantial access to sensitive users' personal information during this operation. To gain a thorough understanding of the privacy awareness of these agents, we present the first large-scale benchmark encompassing 7,138 scenarios to the best of our knowledge. In addition, for privacy context in scenarios, we annotate its type (e.g., Account Credentials), sensitivity level, and location. We then carefully benchmark seven available mainstream smartphone agents. Our results demonstrate that almost all benchmarked agents show unsatisfying privacy awareness (RA), with performance remaining below 60% even with explicit hints. Overall, closed-source agents show better privacy ability than open-source ones, and Gemini 2.0-flash achieves the best, achieving an RA of 67%. We also find that the agents' privacy detection capability is highly related to scenario sensitivity level, i.e., the scenario with a higher sensitivity level is typically more identifiable. We hope the findings enlighten the research community to rethink the unbalanced utility-privacy tradeoff about smartphone agents. Our code and benchmark are available at https://zhixin-l.github.io/SAPA-Bench.
Simple Radiology VLLM Test-time Scaling with Thought Graph Traversal
Jun 13, 2025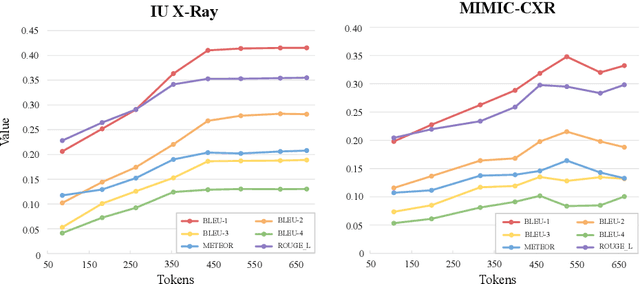
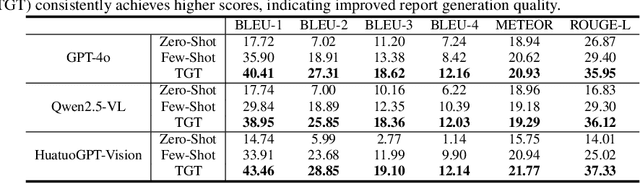
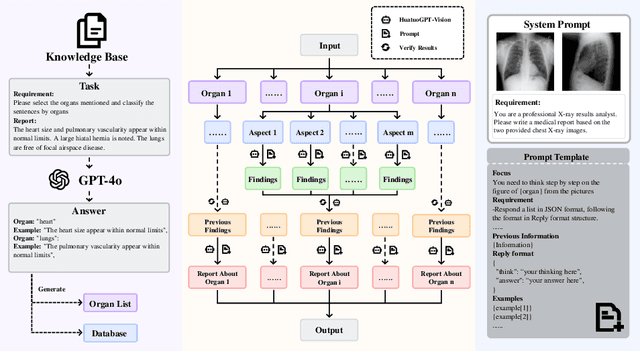
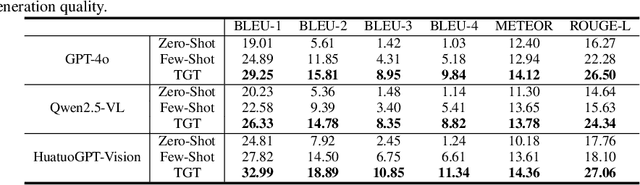
Test-time scaling offers a promising way to improve the reasoning performance of vision-language large models (VLLMs) without additional training. In this paper, we explore a simple but effective approach for applying test-time scaling to radiology report generation. Specifically, we introduce a lightweight Thought Graph Traversal (TGT) framework that guides the model to reason through organ-specific findings in a medically coherent order. This framework integrates structured medical priors into the prompt, enabling deeper and more logical analysis with no changes to the underlying model. To further enhance reasoning depth, we apply a reasoning budget forcing strategy that adjusts the model's inference depth at test time by dynamically extending its generation process. This simple yet powerful combination allows a frozen radiology VLLM to self-correct and generate more accurate, consistent chest X-ray reports. Our method outperforms baseline prompting approaches on standard benchmarks, and also reveals dataset biases through traceable reasoning paths. Code and prompts are open-sourced for reproducibility at https://github.com/glerium/Thought-Graph-Traversal.