 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepLocalization: Using change point detection for Temporal Action Localization
Apr 18, 2024



In this study, we introduce DeepLocalization, an innovative framework devised for the real-time localization of actions tailored explicitly for monitoring driver behavior. Utilizing the power of advanced deep learning methodologies, our objective is to tackle the critical issue of distracted driving-a significant factor contributing to road accidents. Our strategy employs a dual approach: leveraging Graph-Based Change-Point Detection for pinpointing actions in time alongside a Video Large Language Model (Video-LLM) for precisely categorizing activities. Through careful prompt engineering, we customize the Video-LLM to adeptly handle driving activities' nuances, ensuring its classification efficacy even with sparse data. Engineered to be lightweight, our framework is optimized for consumer-grade GPUs, making it vastly applicable in practical scenarios. We subjected our method to rigorous testing on the SynDD2 dataset, a complex benchmark for distracted driving behaviors, where it demonstrated commendable performance-achieving 57.5% accuracy in event classification and 51% in event detection. These outcomes underscore the substantial promise of DeepLocalization in accurately identifying diverse driver behaviors and their temporal occurrences, all within the bounds of limited computational resources.
The 8th AI City Challenge
Apr 15, 2024
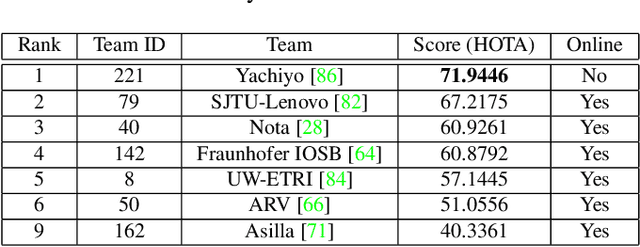

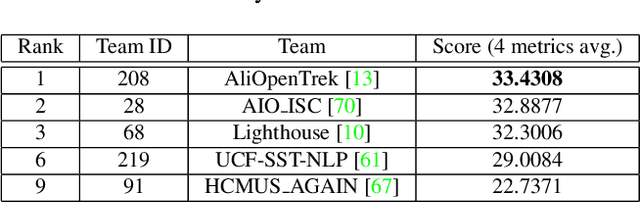
The eighth AI City Challenge highlighted the convergence of computer vision and artificial intelligence in areas like retail, warehouse settings, and Intelligent Traffic Systems (ITS), presenting significant research opportunities. The 2024 edition featured five tracks, attracting unprecedented interest from 726 teams in 47 countries and regions. Track 1 dealt with multi-target multi-camera (MTMC) people tracking, highlighting significant enhancements in camera count, character number, 3D annotation, and camera matrices, alongside new rules for 3D tracking and online tracking algorithm encouragement. Track 2 introduced dense video captioning for traffic safety, focusing on pedestrian accidents using multi-camera feeds to improve insights for insurance and prevention. Track 3 required teams to classify driver actions in a naturalistic driving analysis. Track 4 explored fish-eye camera analytics using the FishEye8K dataset. Track 5 focused on motorcycle helmet rule violation detection. The challenge utilized two leaderboards to showcase methods, with participants setting new benchmarks, some surpassing existing state-of-the-art achievements.
Vision-Language Models can Identify Distracted Driver Behavior from Naturalistic Videos
Jun 22, 2023Recognizing the activities, causing distraction, in real-world driving scenarios is critical for ensuring the safety and reliability of both drivers and pedestrians on the roadways. Conventional computer vision techniques are typically data-intensive and require a large volume of annotated training data to detect and classify various distracted driving behaviors, thereby limiting their efficiency and scalability. We aim to develop a generalized framework that showcases robust performance with access to limited or no annotated training data. Recently, vision-language models have offered large-scale visual-textual pretraining that can be adapted to task-specific learning like distracted driving activity recognition. Vision-language pretraining models, such as CLIP, have shown significant promise in learning natural language-guided visual representations. This paper proposes a CLIP-based driver activity recognition approach that identifies driver distraction from naturalistic driving images and videos. CLIP's vision embedding offers zero-shot transfer and task-based finetuning, which can classify distracted activities from driving video data. Our results show that this framework offers state-of-the-art performance on zero-shot transfer and video-based CLIP for predicting the driver's state on two public datasets. We propose both frame-based and video-based frameworks developed on top of the CLIP's visual representation for distracted driving detection and classification task and report the results.
The 7th AI City Challenge
Apr 15, 2023
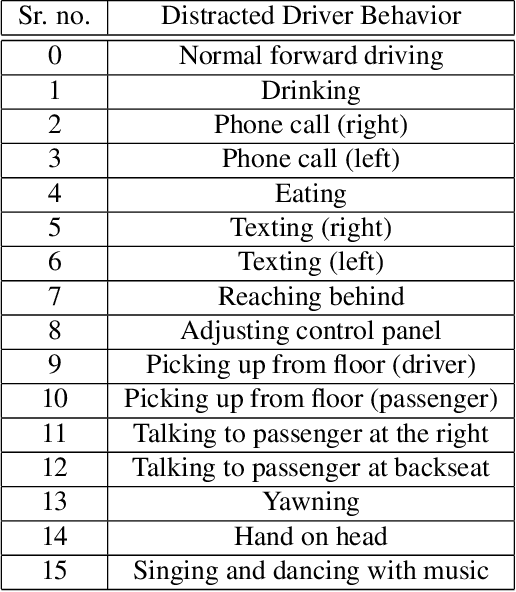

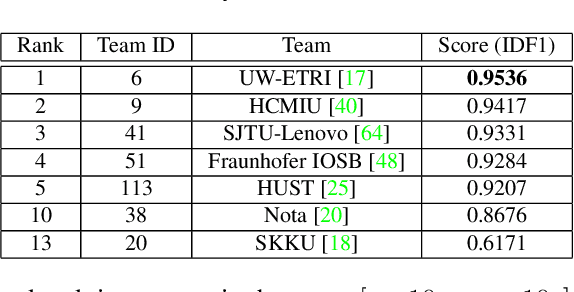
The AI City Challenge's seventh edition emphasizes two domains at the intersection of computer vision and artificial intelligence - retail business and Intelligent Traffic Systems (ITS) - that have considerable untapped potential. The 2023 challenge had five tracks, which drew a record-breaking number of participation requests from 508 teams across 46 countries. Track 1 was a brand new track that focused on multi-target multi-camera (MTMC) people tracking, where teams trained and evaluated using both real and highly realistic synthetic data. Track 2 centered around natural-language-based vehicle track retrieval. Track 3 required teams to classify driver actions in naturalistic driving analysis. Track 4 aimed to develop an automated checkout system for retail stores using a single view camera. Track 5, another new addition, tasked teams with detecting violations of the helmet rule for motorcyclists. Two leader boards were released for submissions based on different methods: a public leader board for the contest where external private data wasn't allowed and a general leader board for all results submitted. The participating teams' top performances established strong baselines and even outperformed the state-of-the-art in the proposed challenge tracks.
The 6th AI City Challenge
Apr 21, 2022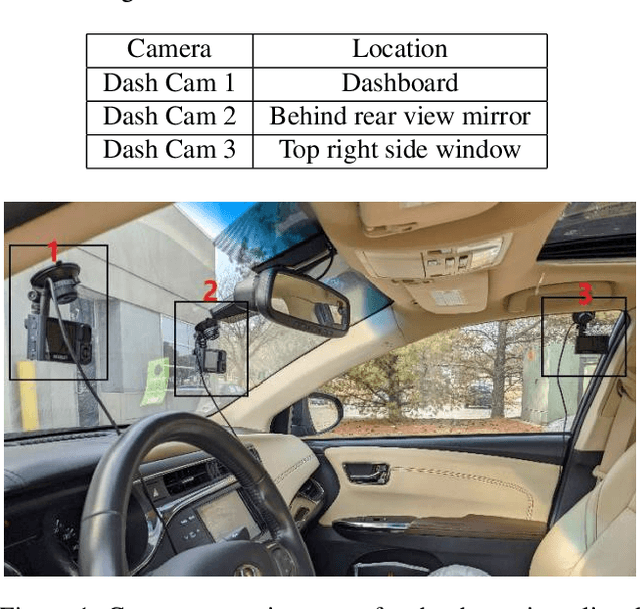
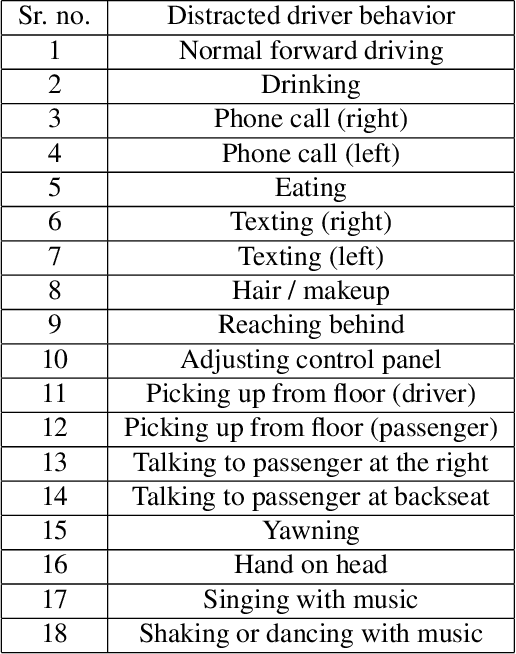
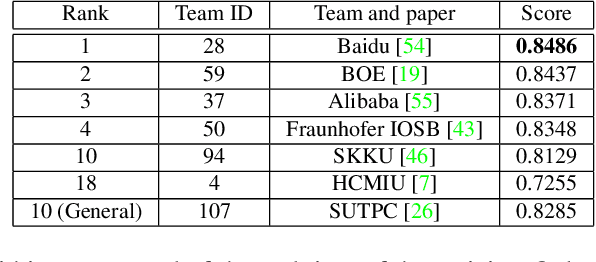
The 6th edition of the AI City Challenge specifically focuses on problems in two domains where there is tremendous unlocked potential at the intersection of computer vision and artificial intelligence: Intelligent Traffic Systems (ITS), and brick and mortar retail businesses. The four challenge tracks of the 2022 AI City Challenge received participation requests from 254 teams across 27 countries. Track 1 addressed city-scale multi-target multi-camera (MTMC) vehicle tracking. Track 2 addressed natural-language-based vehicle track retrieval. Track 3 was a brand new track for naturalistic driving analysis, where the data were captured by several cameras mounted inside the vehicle focusing on driver safety, and the task was to classify driver actions. Track 4 was another new track aiming to achieve retail store automated checkout using only a single view camera. We released two leader boards for submissions based on different methods, including a public leader board for the contest, where no use of external data is allowed, and a general leader board for all submitted results. The top performance of participating teams established strong baselines and even outperformed the state-of-the-art in the proposed challenge tracks.
Synthetic Distracted Driving (SynDD1) dataset for analyzing distracted behaviors and various gaze zones of a driver
Apr 19, 2022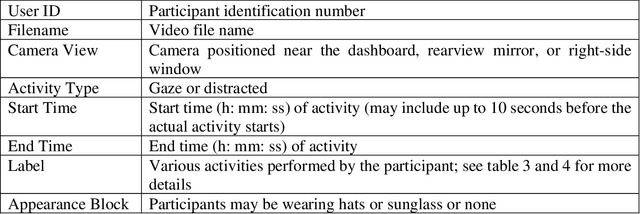



This article presents a synthetic distracted driving (SynDD1) dataset for machine learning models to detect and analyze drivers' various distracted behavior and different gaze zones. We collected the data in a stationary vehicle using three in-vehicle cameras positioned at locations: on the dashboard, near the rearview mirror, and on the top right-side window corner. The dataset contains two activity types: distracted activities, and gaze zones for each participant and each activity type has two sets: without appearance blocks and with appearance blocks such as wearing a hat or sunglasses. The order and duration of each activity for each participant are random. In addition, the dataset contains manual annotations for each activity, having its start and end time annotated. Researchers could use this dataset to evaluate the performance of machine learning algorithms for the classification of various distracting activities and gaze zones of drivers.