 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCertificate-Guided Pruning for Stochastic Lipschitz Optimization
Jan 28, 2026We study black-box optimization of Lipschitz functions under noisy evaluations. Existing adaptive discretization methods implicitly avoid suboptimal regions but do not provide explicit certificates of optimality or measurable progress guarantees. We introduce \textbf{Certificate-Guided Pruning (CGP)}, which maintains an explicit \emph{active set} $A_t$ of potentially optimal points via confidence-adjusted Lipschitz envelopes. Any point outside $A_t$ is certifiably suboptimal with high probability, and under a margin condition with near-optimality dimension $α$, we prove $\Vol(A_t)$ shrinks at a controlled rate yielding sample complexity $\tildeO(\varepsilon^{-(2+α)})$. We develop three extensions: CGP-Adaptive learns $L$ online with $O(\log T)$ overhead; CGP-TR scales to $d > 50$ via trust regions with local certificates; and CGP-Hybrid switches to GP refinement when local smoothness is detected. Experiments on 12 benchmarks ($d \in [2, 100]$) show CGP variants match or exceed strong baselines while providing principled stopping criteria via certificate volume.
Beyond Variance: Knowledge-Aware LLM Compression via Fisher-Aligned Subspace Diagnostics
Jan 12, 2026Post-training activation compression is essential for deploying Large Language Models (LLMs) on resource-constrained hardware. However, standard methods like Singular Value Decomposition (SVD) are gradient-blind: they preserve high-variance dimensions regardless of their impact on factual knowledge preservation. We introduce Fisher-Aligned Subspace Compression (FASC), a knowledge-aware compression framework that selects subspaces by directly modeling activation-gradient coupling, minimizing a second-order surrogate of the loss function. FASC leverages the Fisher Information Matrix to identify dimensions critical for factual knowledge, which often reside in low-variance but high-gradient-sensitivity subspaces. We propose the Dependence Violation Score (\r{ho}) as a general-purpose diagnostic metric that quantifies activation-gradient coupling, revealing where factual knowledge is stored within transformer architectures. Extensive experiments on Mistral-7B and Llama-3-8B demonstrate that FASC preserves 6-8% more accuracy on knowledge-intensive benchmarks (MMLU, LAMA) compared to variance-based methods at 50% rank reduction, effectively enabling a 7B model to match the factual recall of a 13B uncompressed model. Our analysis reveals that \r{ho} serves as a fundamental signal of stored knowledge, with high-\r{ho} layers emerging only when models internalize factual associations during training.
CalPro: Prior-Aware Evidential--Conformal Prediction with Structure-Aware Guarantees for Protein Structures
Jan 12, 2026Deep protein structure predictors such as AlphaFold provide confidence estimates (e.g., pLDDT) that are often miscalibrated and degrade under distribution shifts across experimental modalities, temporal changes, and intrinsically disordered regions. We introduce CalPro, a prior-aware evidential-conformal framework for shift-robust uncertainty quantification. CalPro combines (i) a geometric evidential head that outputs Normal-Inverse-Gamma predictive distributions via a graph-based architecture; (ii) a differentiable conformal layer that enables end-to-end training with finite-sample coverage guarantees; and (iii) domain priors (disorder, flexibility) encoded as soft constraints. We derive structure-aware coverage guarantees under distribution shift using PAC-Bayesian bounds over ambiguity sets, and show that CalPro maintains near-nominal coverage while producing tighter intervals than standard conformal methods in regions where priors are informative. Empirically, CalPro exhibits at most 5% coverage degradation across modalities (vs. 15-25% for baselines), reduces calibration error by 30-50%, and improves downstream ligand-docking success by 25%. Beyond proteins, CalPro applies to structured regression tasks in which priors encode local reliability, validated on non-biological benchmarks.
Adaptive Constraint Propagation: Scaling Structured Inference for Large Language Models via Meta-Reinforcement Learning
Jan 06, 2026Large language models increasingly require structured inference, from JSON schema enforcement to multi-lingual parsing, where outputs must satisfy complex constraints. We introduce MetaJuLS, a meta-reinforcement learning approach that learns universal constraint propagation policies applicable across languages and tasks without task-specific retraining. By formulating structured inference as adaptive constraint propagation and training a Graph Attention Network with meta-learning, MetaJuLS achieves 1.5--2.0$\times$ speedups over GPU-optimized baselines while maintaining within 0.2\% accuracy of state-of-the-art parsers. On Universal Dependencies across 10 languages and LLM-constrained generation (LogicBench, GSM8K-Constrained), MetaJuLS demonstrates rapid cross-domain adaptation: a policy trained on English parsing adapts to new languages and tasks with 5--10 gradient steps (5--15 seconds) rather than requiring hours of task-specific training. Mechanistic analysis reveals the policy discovers human-like parsing strategies (easy-first) and novel non-intuitive heuristics. By reducing propagation steps in LLM deployments, MetaJuLS contributes to Green AI by directly reducing inference carbon footprint.
Temporal Zoom Networks: Distance Regression and Continuous Depth for Efficient Action Localization
Nov 13, 2025Temporal action localization requires both precise boundary detection and computational efficiency. Current methods apply uniform computation across all temporal positions, wasting resources on easy boundaries while struggling with ambiguous ones. We address this through two complementary innovations: Boundary Distance Regression (BDR), which replaces classification-based boundary detection with signed-distance regression achieving 3.3--16.7$\times$ lower variance; and Adaptive Temporal Refinement (ATR), which allocates transformer depth continuously ($τ\in[0,1]$) to concentrate computation near difficult boundaries. On THUMOS14, our method achieves 56.5\% mAP@0.7 and 58.2\% average mAP@[0.3:0.7] with 151G FLOPs, using 36\% fewer FLOPs than ActionFormer++ (55.7\% mAP@0.7 at 235G). Compared to uniform baselines, we achieve +2.9\% mAP@0.7 (+1.8\% avg mAP, 5.4\% relative) with 24\% fewer FLOPs and 29\% lower latency, with particularly strong gains on short actions (+4.2\%, 8.6\% relative). Training requires 1.29$\times$ baseline FLOPs, but this one-time cost is amortized over many inference runs; knowledge distillation further reduces this to 1.1$\times$ while retaining 99.5\% accuracy. Our contributions include: (i) a theoretically-grounded distance formulation with information-theoretic analysis showing optimal variance scaling; (ii) a continuous depth allocation mechanism avoiding discrete routing complexity; and (iii) consistent improvements across four datasets with gains correlating with boundary heterogeneity.
LLM-Guided Probabilistic Fusion for Label-Efficient Document Layout Analysis
Nov 13, 2025



Document layout understanding remains data-intensive despite advances in semi-supervised learning. We present a framework that enhances semi-supervised detection by fusing visual predictions with structural priors from text-pretrained LLMs via principled probabilistic weighting. Given unlabeled documents, an OCR-LLM pipeline infers hierarchical regions which are combined with teacher detector outputs through inverse-variance fusion to generate refined pseudo-labels.Our method demonstrates consistent gains across model scales. With a lightweight SwiftFormer backbone (26M params), we achieve 88.2$\pm$0.3 AP using only 5\% labels on PubLayNet. When applied to document-pretrained LayoutLMv3 (133M params), our fusion framework reaches 89.7$\pm$0.4 AP, surpassing both LayoutLMv3 with standard semi-supervised learning (89.1$\pm$0.4 AP, p=0.02) and matching UDOP~\cite{udop} (89.8 AP) which requires 100M+ pages of multimodal pretraining. This demonstrates that LLM structural priors are complementary to both lightweight and pretrained architectures. Key findings include: (1) learned instance-adaptive gating improves over fixed weights by +0.9 AP with data-dependent PAC bounds correctly predicting convergence; (2) open-source LLMs enable privacy-preserving deployment with minimal loss (Llama-3-70B: 87.1 AP lightweight, 89.4 AP with LayoutLMv3); (3) LLMs provide targeted semantic disambiguation (18.7\% of cases, +3.8 AP gain) beyond simple text heuristics.Total system cost includes \$12 for GPT-4o-mini API or 17 GPU-hours for local Llama-3-70B per 50K pages, amortized across training runs.
Selective Risk Certification for LLM Outputs via Information-Lift Statistics: PAC-Bayes, Robustness, and Skeleton Design
Sep 16, 2025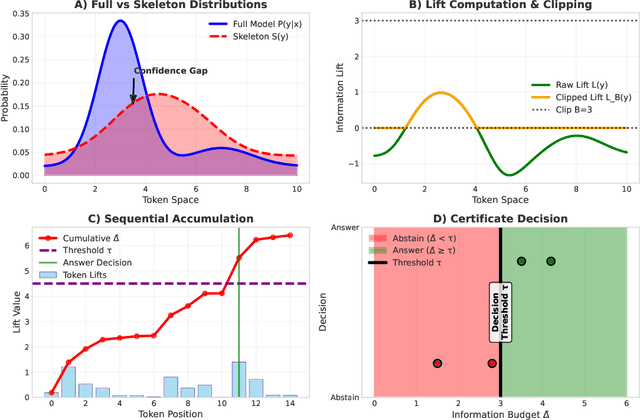
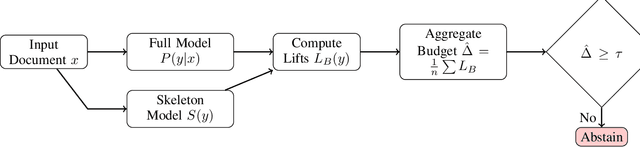
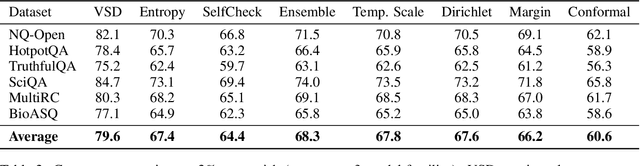
Large language models often produce plausible but incorrect outputs. Existing heuristics such as HallBayes lack formal guarantees. We develop the first comprehensive theory of \emph{information-lift certificates} under selective classification. Our contributions are: (i) a PAC-Bayes \emph{sub-gamma} analysis extending beyond standard Bernstein bounds; (ii) explicit skeleton sensitivity theorems quantifying robustness to misspecification; (iii) failure-mode guarantees under assumption violations; and (iv) a principled variational method for skeleton construction. Across six datasets and multiple model families, we validate assumptions empirically, reduce abstention by 12--15\% at the same risk, and maintain runtime overhead below 20\% (further reduced via batching).
What Fundamental Structure in Reward Functions Enables Efficient Sparse-Reward Learning?
Sep 04, 2025What fundamental properties of reward functions enable efficient sparse-reward reinforcement learning? We address this question through the lens of low-rank structure in reward matrices, showing that such structure induces a sharp transition from exponential to polynomial sample complexity, the first result of this kind for sparse-reward RL. We introduce Policy-Aware Matrix Completion (PAMC), which connects matrix completion theory with reinforcement learning via a new analysis of policy-dependent sampling. Our framework provides: (i) impossibility results for general sparse reward observation, (ii) reward-free representation learning from dynamics, (iii) distribution-free confidence sets via conformal prediction, and (iv) robust completion guarantees that degrade gracefully when low-rank structure is only approximate. Empirically, we conduct a pre-registered evaluation across 100 systematically sampled domains, finding exploitable structure in over half. PAMC improves sample efficiency by factors between 1.6 and 2.1 compared to strong exploration, structured, and representation-learning baselines, while adding only about 20 percent computational overhead.These results establish structural reward learning as a promising new paradigm, with immediate implications for robotics, healthcare, and other safety-critical, sample-expensive applications.
Differentiable Entropy Regularization for Geometry and Neural Networks
Sep 03, 2025We introduce a differentiable estimator of range-partition entropy, a recent concept from computational geometry that enables algorithms to adapt to the "sortedness" of their input. While range-partition entropy provides strong guarantees in algorithm design, it has not yet been made accessible to deep learning. In this work, we (i) propose the first differentiable approximation of range-partition entropy, enabling its use as a trainable loss or regularizer; (ii) design EntropyNet, a neural module that restructures data into low-entropy forms to accelerate downstream instance-optimal algorithms; and (iii) extend this principle beyond geometry by applying entropy regularization directly to Transformer attention. Across tasks, we demonstrate that differentiable entropy improves efficiency without degrading correctness: in geometry, our method achieves up to $4.1\times$ runtime speedups with negligible error ($<0.2%$); in deep learning, it induces structured attention patterns that yield 6% higher accuracy at 80% sparsity compared to L1 baselines. Our theoretical analysis provides approximation bounds for the estimator, and extensive ablations validate design choices. These results suggest that entropy-bounded computation is not only theoretically elegant but also a practical mechanism for adaptive learning, efficiency, and structured representation.
Large Language Models for Crash Detection in Video: A Survey of Methods, Datasets, and Challenges
Jul 02, 2025Crash detection from video feeds is a critical problem in intelligent transportation systems. Recent developments in large language models (LLMs) and vision-language models (VLMs) have transformed how we process, reason about, and summarize multimodal information. This paper surveys recent methods leveraging LLMs for crash detection from video data. We present a structured taxonomy of fusion strategies, summarize key datasets, analyze model architectures, compare performance benchmarks, and discuss ongoing challenges and opportunities. Our review provides a foundation for future research in this fast-growing intersection of video understanding and foundation models.