 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRISM: Product Retrieval In Shopping Carts using Hybrid Matching
Sep 18, 2025



Compared to traditional image retrieval tasks, product retrieval in retail settings is even more challenging. Products of the same type from different brands may have highly similar visual appearances, and the query image may be taken from an angle that differs significantly from view angles of the stored catalog images. Foundational models, such as CLIP and SigLIP, often struggle to distinguish these subtle but important local differences. Pixel-wise matching methods, on the other hand, are computationally expensive and incur prohibitively high matching times. In this paper, we propose a new, hybrid method, called PRISM, for product retrieval in retail settings by leveraging the advantages of both vision-language model-based and pixel-wise matching approaches. To provide both efficiency/speed and finegrained retrieval accuracy, PRISM consists of three stages: 1) A vision-language model (SigLIP) is employed first to retrieve the top 35 most semantically similar products from a fixed gallery, thereby narrowing the search space significantly; 2) a segmentation model (YOLO-E) is applied to eliminate background clutter; 3) fine-grained pixel-level matching is performed using LightGlue across the filtered candidates. This framework enables more accurate discrimination between products with high inter-class similarity by focusing on subtle visual cues often missed by global models. Experiments performed on the ABV dataset show that our proposed PRISM outperforms the state-of-the-art image retrieval methods by 4.21% in top-1 accuracy while still remaining within the bounds of real-time processing for practical retail deployments.
DG-MVP: 3D Domain Generalization via Multiple Views of Point Clouds for Classification
Apr 16, 2025



Deep neural networks have achieved significant success in 3D point cloud classification while relying on large-scale, annotated point cloud datasets, which are labor-intensive to build. Compared to capturing data with LiDAR sensors and then performing annotation, it is relatively easier to sample point clouds from CAD models. Yet, data sampled from CAD models is regular, and does not suffer from occlusion and missing points, which are very common for LiDAR data, creating a large domain shift. Therefore, it is critical to develop methods that can generalize well across different point cloud domains. %In this paper, we focus on the 3D point cloud domain generalization problem. Existing 3D domain generalization methods employ point-based backbones to extract point cloud features. Yet, by analyzing point utilization of point-based methods and observing the geometry of point clouds from different domains, we have found that a large number of point features are discarded by point-based methods through the max-pooling operation. This is a significant waste especially considering the fact that domain generalization is more challenging than supervised learning, and point clouds are already affected by missing points and occlusion to begin with. To address these issues, we propose a novel method for 3D point cloud domain generalization, which can generalize to unseen domains of point clouds. Our proposed method employs multiple 2D projections of a 3D point cloud to alleviate the issue of missing points and involves a simple yet effective convolution-based model to extract features. The experiments, performed on the PointDA-10 and Sim-to-Real benchmarks, demonstrate the effectiveness of our proposed method, which outperforms different baselines, and can transfer well from synthetic domain to real-world domain.
3D-PointZshotS: Geometry-Aware 3D Point Cloud Zero-Shot Semantic Segmentation Narrowing the Visual-Semantic Gap
Apr 16, 2025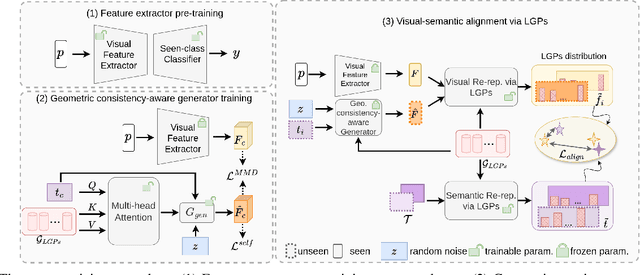
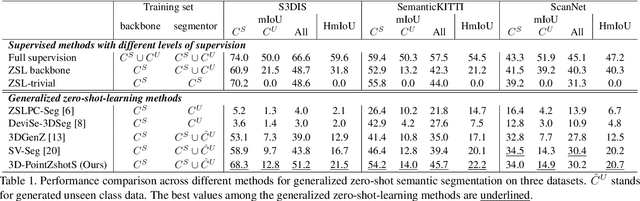
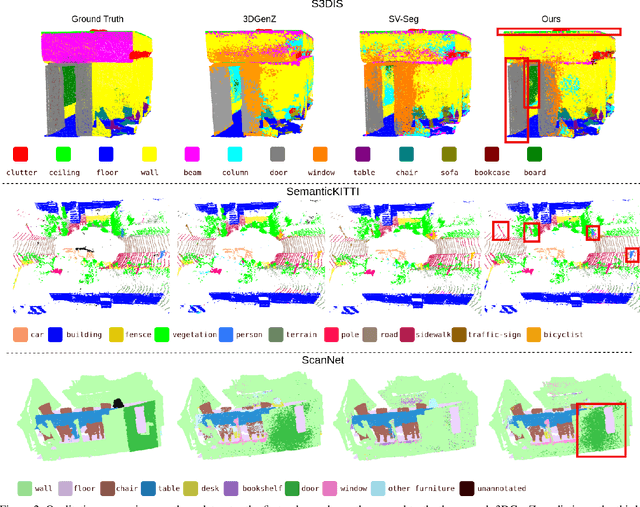

Existing zero-shot 3D point cloud segmentation methods often struggle with limited transferability from seen classes to unseen classes and from semantic to visual space. To alleviate this, we introduce 3D-PointZshotS, a geometry-aware zero-shot segmentation framework that enhances both feature generation and alignment using latent geometric prototypes (LGPs). Specifically, we integrate LGPs into a generator via a cross-attention mechanism, enriching semantic features with fine-grained geometric details. To further enhance stability and generalization, we introduce a self-consistency loss, which enforces feature robustness against point-wise perturbations. Additionally, we re-represent visual and semantic features in a shared space, bridging the semantic-visual gap and facilitating knowledge transfer to unseen classes. Experiments on three real-world datasets, namely ScanNet, SemanticKITTI, and S3DIS, demonstrate that our method achieves superior performance over four baselines in terms of harmonic mIoU. The code is available at \href{https://github.com/LexieYang/3D-PointZshotS}{Github}.
LVP-CLIP:Revisiting CLIP for Continual Learning with Label Vector Pool
Dec 08, 2024



Continual learning aims to update a model so that it can sequentially learn new tasks without forgetting previously acquired knowledge. Recent continual learning approaches often leverage the vision-language model CLIP for its high-dimensional feature space and cross-modality feature matching. Traditional CLIP-based classification methods identify the most similar text label for a test image by comparing their embeddings. However, these methods are sensitive to the quality of text phrases and less effective for classes lacking meaningful text labels. In this work, we rethink CLIP-based continual learning and introduce the concept of Label Vector Pool (LVP). LVP replaces text labels with training images as similarity references, eliminating the need for ideal text descriptions. We present three variations of LVP and evaluate their performance on class and domain incremental learning tasks. Leveraging CLIP's high dimensional feature space, LVP learning algorithms are task-order invariant. The new knowledge does not modify the old knowledge, hence, there is minimum forgetting. Different tasks can be learned independently and in parallel with low computational and memory demands. Experimental results show that proposed LVP-based methods outperform the current state-of-the-art baseline by a significant margin of 40.7%.
Feature-based Federated Transfer Learning: Communication Efficiency, Robustness and Privacy
May 15, 2024



In this paper, we propose feature-based federated transfer learning as a novel approach to improve communication efficiency by reducing the uplink payload by multiple orders of magnitude compared to that of existing approaches in federated learning and federated transfer learning. Specifically, in the proposed feature-based federated learning, we design the extracted features and outputs to be uploaded instead of parameter updates. For this distributed learning model, we determine the required payload and provide comparisons with the existing schemes. Subsequently, we analyze the robustness of feature-based federated transfer learning against packet loss, data insufficiency, and quantization. Finally, we address privacy considerations by defining and analyzing label privacy leakage and feature privacy leakage, and investigating mitigating approaches. For all aforementioned analyses, we evaluate the performance of the proposed learning scheme via experiments on an image classification task and a natural language processing task to demonstrate its effectiveness.
Block-As-Domain Adaptation for Workload Prediction from fNIRS Data
Apr 30, 2024



Functional near-infrared spectroscopy (fNIRS) is a non-intrusive way to measure cortical hemodynamic activity. Predicting cognitive workload from fNIRS data has taken on a diffuse set of methods. To be applicable in real-world settings, models are needed, which can perform well across different sessions as well as different subjects. However, most existing works assume that training and testing data come from the same subjects and/or cannot generalize well across never-before-seen subjects. Additional challenges imposed by fNIRS data include the high variations in inter-subject fNIRS data and also in intra-subject data collected across different blocks of sessions. To address these issues, we propose an effective method, referred to as the class-aware-block-aware domain adaptation (CABA-DA) which explicitly minimize intra-session variance by viewing different blocks from the same subject same session as different domains. We minimize the intra-class domain discrepancy and maximize the inter-class domain discrepancy accordingly. In addition, we propose an MLPMixer-based model for cognitive load classification. Experimental results demonstrate the proposed model has better performance compared with three different baseline models on three public-available datasets of cognitive workload. Two of them are collected from n-back tasks and one of them is from finger tapping. From our experiments, we also show the proposed contrastive learning method can also improve baseline models we compared with.
GaitPoint+: A Gait Recognition Network Incorporating Point Cloud Analysis and Recycling
Apr 16, 2024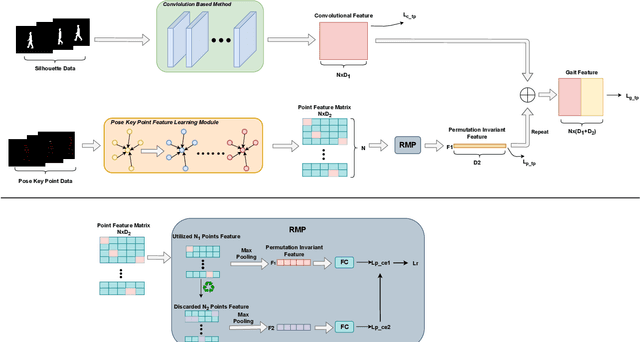
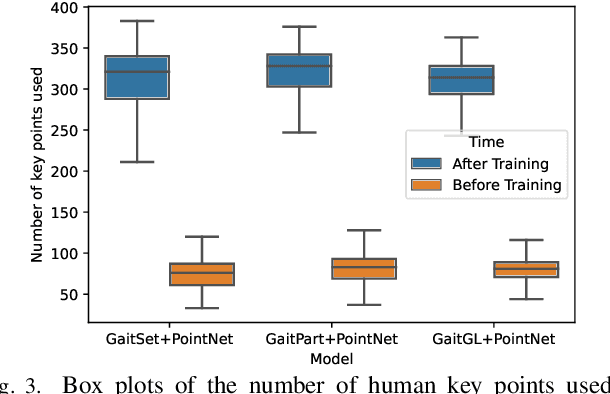
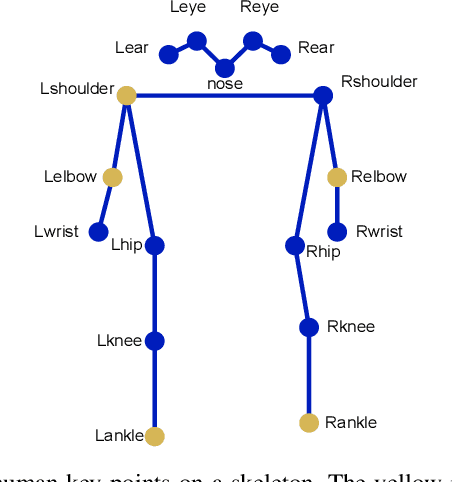
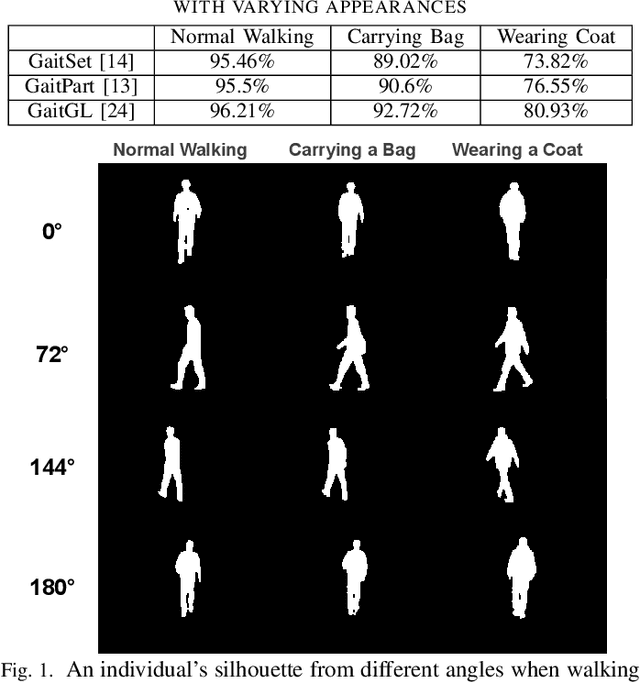
Gait is a behavioral biometric modality that can be used to recognize individuals by the way they walk from a far distance. Most existing gait recognition approaches rely on either silhouettes or skeletons, while their joint use is underexplored. Features from silhouettes and skeletons can provide complementary information for more robust recognition against appearance changes or pose estimation errors. To exploit the benefits of both silhouette and skeleton features, we propose a new gait recognition network, referred to as the GaitPoint+. Our approach models skeleton key points as a 3D point cloud, and employs a computational complexity-conscious 3D point processing approach to extract skeleton features, which are then combined with silhouette features for improved accuracy. Since silhouette- or CNN-based methods already require considerable amount of computational resources, it is preferable that the key point learning module is faster and more lightweight. We present a detailed analysis of the utilization of every human key point after the use of traditional max-pooling, and show that while elbow and ankle points are used most commonly, many useful points are discarded by max-pooling. Thus, we present a method to recycle some of the discarded points by a Recycling Max-Pooling module, during processing of skeleton point clouds, and achieve further performance improvement. We provide a comprehensive set of experimental results showing that (i) incorporating skeleton features obtained by a point-based 3D point cloud processing approach boosts the performance of three different state-of-the-art silhouette- and CNN-based baselines; (ii) recycling the discarded points increases the accuracy further. Ablation studies are also provided to show the effectiveness and contribution of different components of our approach.
CLIP-BEVFormer: Enhancing Multi-View Image-Based BEV Detector with Ground Truth Flow
Mar 13, 2024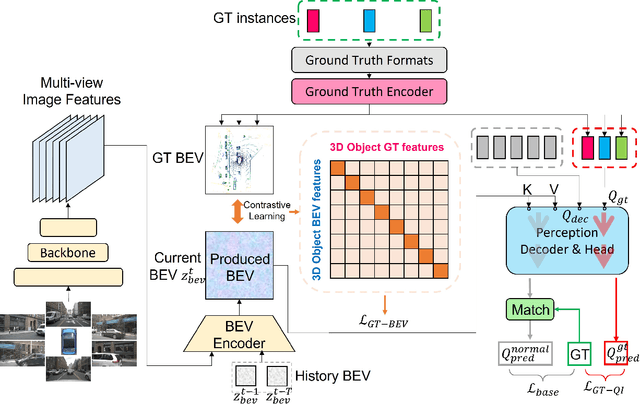
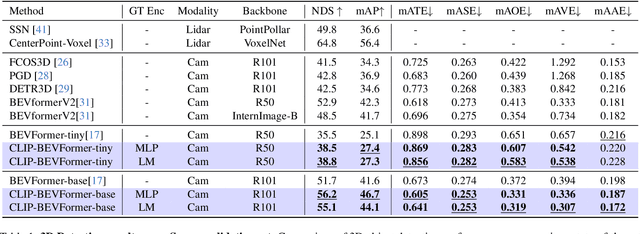
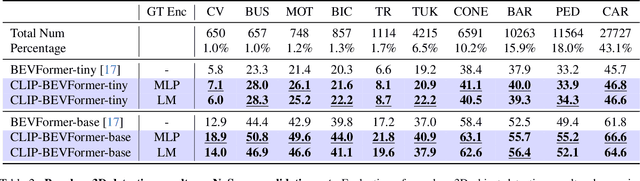

Autonomous driving stands as a pivotal domain in computer vision, shaping the future of transportation. Within this paradigm, the backbone of the system plays a crucial role in interpreting the complex environment. However, a notable challenge has been the loss of clear supervision when it comes to Bird's Eye View elements. To address this limitation, we introduce CLIP-BEVFormer, a novel approach that leverages the power of contrastive learning techniques to enhance the multi-view image-derived BEV backbones with ground truth information flow. We conduct extensive experiments on the challenging nuScenes dataset and showcase significant and consistent improvements over the SOTA. Specifically, CLIP-BEVFormer achieves an impressive 8.5\% and 9.2\% enhancement in terms of NDS and mAP, respectively, over the previous best BEV model on the 3D object detection task.
* CVPR 2024
Only My Model On My Data: A Privacy Preserving Approach Protecting one Model and Deceiving Unauthorized Black-Box Models
Feb 14, 2024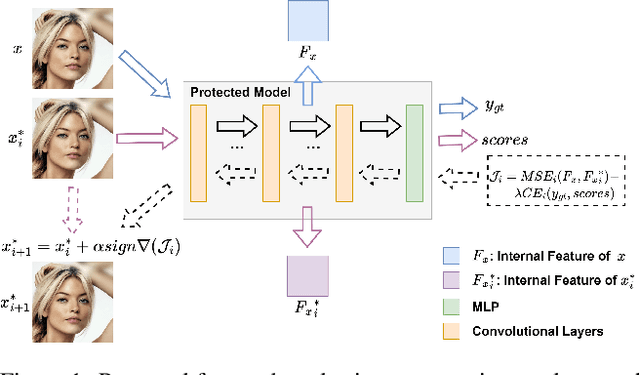
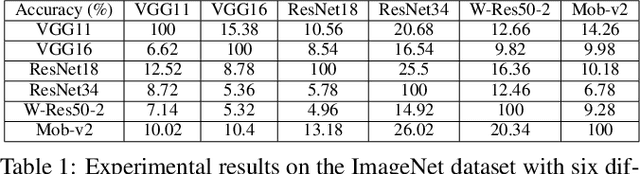
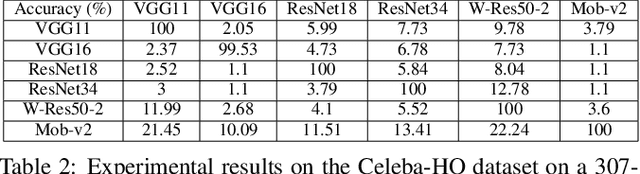

Deep neural networks are extensively applied to real-world tasks, such as face recognition and medical image classification, where privacy and data protection are critical. Image data, if not protected, can be exploited to infer personal or contextual information. Existing privacy preservation methods, like encryption, generate perturbed images that are unrecognizable to even humans. Adversarial attack approaches prohibit automated inference even for authorized stakeholders, limiting practical incentives for commercial and widespread adaptation. This pioneering study tackles an unexplored practical privacy preservation use case by generating human-perceivable images that maintain accurate inference by an authorized model while evading other unauthorized black-box models of similar or dissimilar objectives, and addresses the previous research gaps. The datasets employed are ImageNet, for image classification, Celeba-HQ dataset, for identity classification, and AffectNet, for emotion classification. Our results show that the generated images can successfully maintain the accuracy of a protected model and degrade the average accuracy of the unauthorized black-box models to 11.97%, 6.63%, and 55.51% on ImageNet, Celeba-HQ, and AffectNet datasets, respectively.
VLP: Vision Language Planning for Autonomous Driving
Jan 14, 2024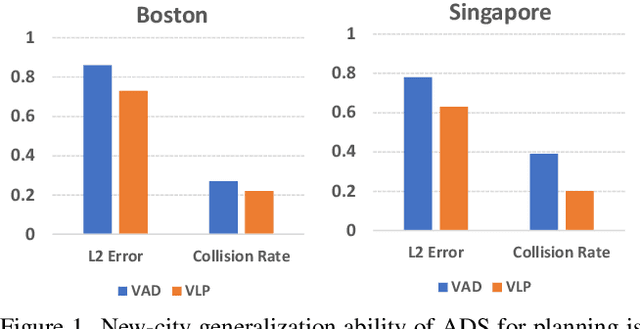
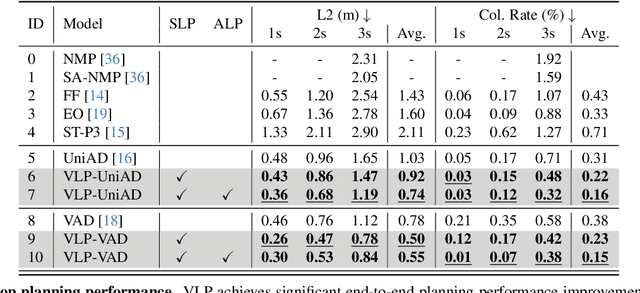


Autonomous driving is a complex and challenging task that aims at safe motion planning through scene understanding and reasoning. While vision-only autonomous driving methods have recently achieved notable performance, through enhanced scene understanding, several key issues, including lack of reasoning, low generalization performance and long-tail scenarios, still need to be addressed. In this paper, we present VLP, a novel Vision-Language-Planning framework that exploits language models to bridge the gap between linguistic understanding and autonomous driving. VLP enhances autonomous driving systems by strengthening both the source memory foundation and the self-driving car's contextual understanding. VLP achieves state-of-the-art end-to-end planning performance on the challenging NuScenes dataset by achieving 35.9\% and 60.5\% reduction in terms of average L2 error and collision rates, respectively, compared to the previous best method. Moreover, VLP shows improved performance in challenging long-tail scenarios and strong generalization capabilities when faced with new urban environments.