 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnly My Model On My Data: A Privacy Preserving Approach Protecting one Model and Deceiving Unauthorized Black-Box Models
Feb 14, 2024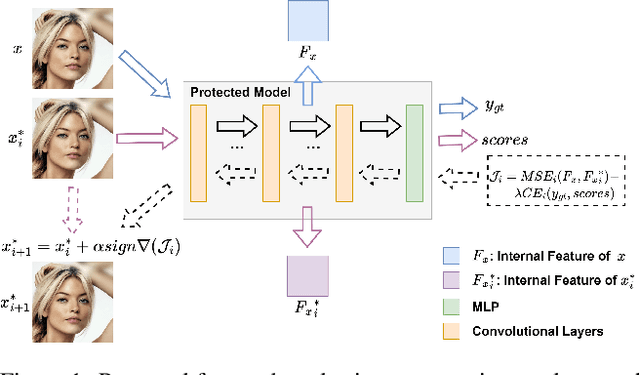
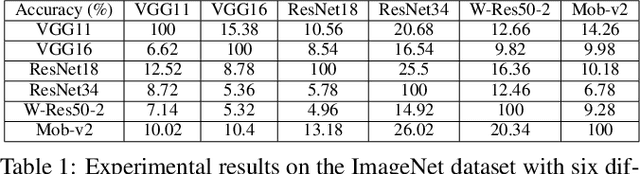
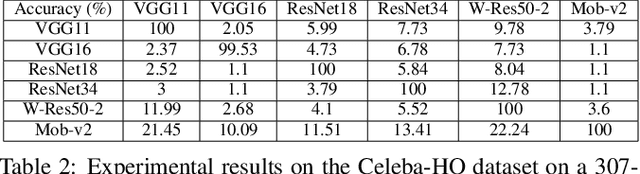

Deep neural networks are extensively applied to real-world tasks, such as face recognition and medical image classification, where privacy and data protection are critical. Image data, if not protected, can be exploited to infer personal or contextual information. Existing privacy preservation methods, like encryption, generate perturbed images that are unrecognizable to even humans. Adversarial attack approaches prohibit automated inference even for authorized stakeholders, limiting practical incentives for commercial and widespread adaptation. This pioneering study tackles an unexplored practical privacy preservation use case by generating human-perceivable images that maintain accurate inference by an authorized model while evading other unauthorized black-box models of similar or dissimilar objectives, and addresses the previous research gaps. The datasets employed are ImageNet, for image classification, Celeba-HQ dataset, for identity classification, and AffectNet, for emotion classification. Our results show that the generated images can successfully maintain the accuracy of a protected model and degrade the average accuracy of the unauthorized black-box models to 11.97%, 6.63%, and 55.51% on ImageNet, Celeba-HQ, and AffectNet datasets, respectively.
Probing the Transition to Dataset-Level Privacy in ML Models Using an Output-Specific and Data-Resolved Privacy Profile
Jun 27, 2023Differential privacy (DP) is the prevailing technique for protecting user data in machine learning models. However, deficits to this framework include a lack of clarity for selecting the privacy budget $\epsilon$ and a lack of quantification for the privacy leakage for a particular data row by a particular trained model. We make progress toward these limitations and a new perspective by which to visualize DP results by studying a privacy metric that quantifies the extent to which a model trained on a dataset using a DP mechanism is ``covered" by each of the distributions resulting from training on neighboring datasets. We connect this coverage metric to what has been established in the literature and use it to rank the privacy of individual samples from the training set in what we call a privacy profile. We additionally show that the privacy profile can be used to probe an observed transition to indistinguishability that takes place in the neighboring distributions as $\epsilon$ decreases, which we suggest is a tool that can enable the selection of $\epsilon$ by the ML practitioner wishing to make use of DP.
Sparse Private LASSO Logistic Regression
Apr 29, 2023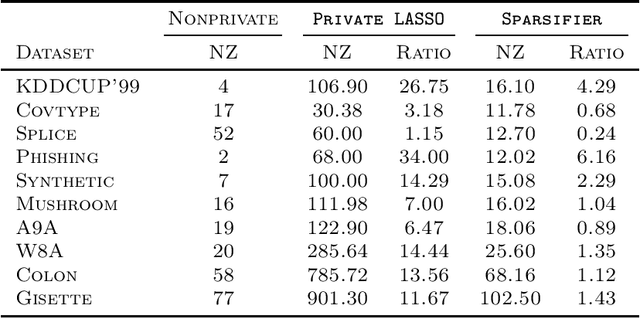
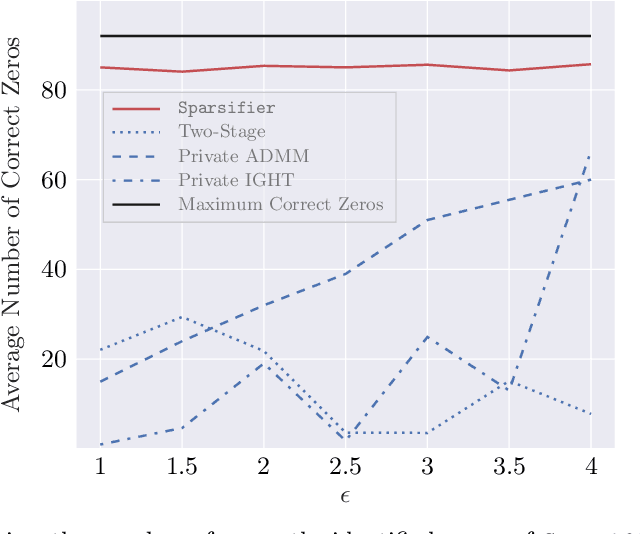
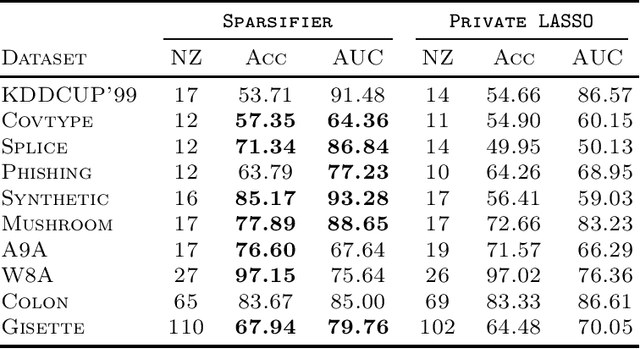
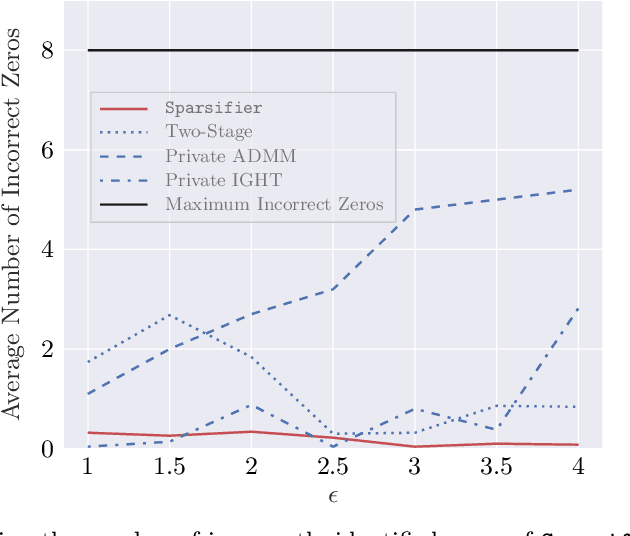
LASSO regularized logistic regression is particularly useful for its built-in feature selection, allowing coefficients to be removed from deployment and producing sparse solutions. Differentially private versions of LASSO logistic regression have been developed, but generally produce dense solutions, reducing the intrinsic utility of the LASSO penalty. In this paper, we present a differentially private method for sparse logistic regression that maintains hard zeros. Our key insight is to first train a non-private LASSO logistic regression model to determine an appropriate privatized number of non-zero coefficients to use in final model selection. To demonstrate our method's performance, we run experiments on synthetic and real-world datasets.
Privacy against Real-Time Speech Emotion Detection via Acoustic Adversarial Evasion of Machine Learning
Nov 17, 2022Emotional Surveillance is an emerging area with wide-reaching privacy concerns. These concerns are exacerbated by ubiquitous IoT devices with multiple sensors that can support these surveillance use cases. The work presented here considers one such use case: the use of a speech emotion recognition (SER) classifier tied to a smart speaker. This work demonstrates the ability to evade black-box SER classifiers tied to a smart speaker without compromising the utility of the smart speaker. This privacy concern is considered through the lens of adversarial evasion of machine learning. Our solution, Defeating Acoustic Recognition of Emotion via Genetic Programming (DARE-GP), uses genetic programming to generate non-invasive additive audio perturbations (AAPs). By constraining the evolution of these AAPs, transcription accuracy can be protected while simultaneously degrading SER classifier performance. The additive nature of these AAPs, along with an approach that generates these AAPs for a fixed set of users in an utterance and user location-independent manner, supports real-time, real-world evasion of SER classifiers. DARE-GP's use of spectral features, which underlay the emotional content of speech, allows the transferability of AAPs to previously unseen black-box SER classifiers. Further, DARE-GP outperforms state-of-the-art SER evasion techniques and is robust against defenses employed by a knowledgeable adversary. The evaluations in this work culminate with acoustic evaluations against two off-the-shelf commercial smart speakers, where a single AAP could evade a black box classifier over 70% of the time. The final evaluation deployed AAP playback on a small-form-factor system (raspberry pi) integrated with a wake-word system to evaluate the efficacy of a real-world, real-time deployment where DARE-GP is automatically invoked with the smart speaker's wake word.
A General Framework for Auditing Differentially Private Machine Learning
Oct 16, 2022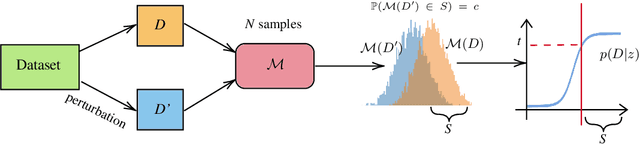

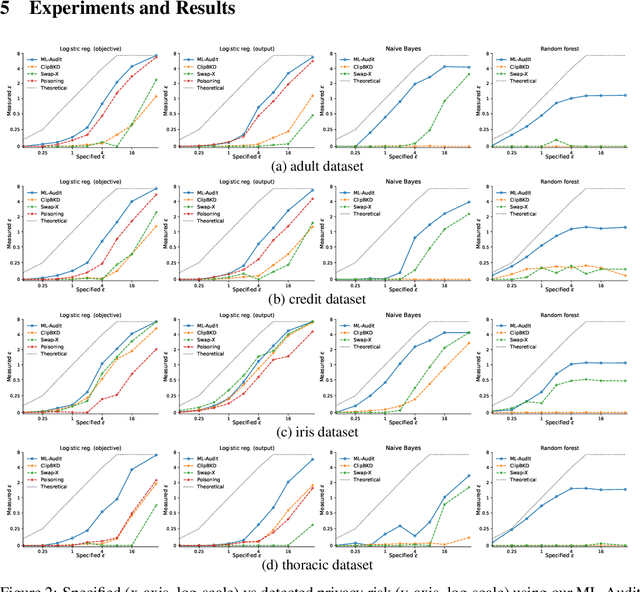
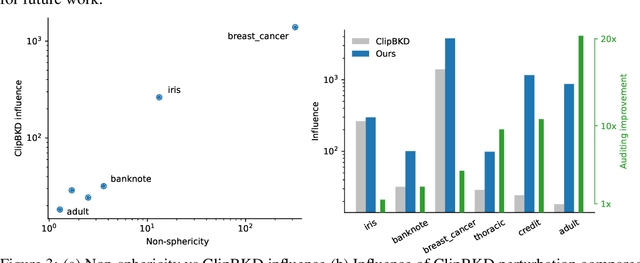
We present a framework to statistically audit the privacy guarantee conferred by a differentially private machine learner in practice. While previous works have taken steps toward evaluating privacy loss through poisoning attacks or membership inference, they have been tailored to specific models or have demonstrated low statistical power. Our work develops a general methodology to empirically evaluate the privacy of differentially private machine learning implementations, combining improved privacy search and verification methods with a toolkit of influence-based poisoning attacks. We demonstrate significantly improved auditing power over previous approaches on a variety of models including logistic regression, Naive Bayes, and random forest. Our method can be used to detect privacy violations due to implementation errors or misuse. When violations are not present, it can aid in understanding the amount of information that can be leaked from a given dataset, algorithm, and privacy specification.