 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCRoP: Context-wise Robust Static Human-Sensing Personalization
Sep 26, 2024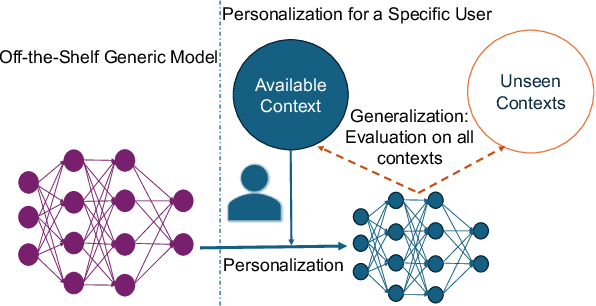
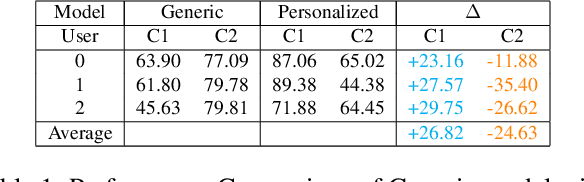
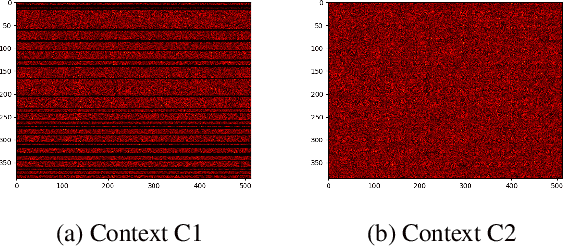

The advancement in deep learning and internet-of-things have led to diverse human sensing applications. However, distinct patterns in human sensing, influenced by various factors or contexts, challenge generic neural network model's performance due to natural distribution shifts. To address this, personalization tailors models to individual users. Yet most personalization studies overlook intra-user heterogeneity across contexts in sensory data, limiting intra-user generalizability. This limitation is especially critical in clinical applications, where limited data availability hampers both generalizability and personalization. Notably, intra-user sensing attributes are expected to change due to external factors such as treatment progression, further complicating the challenges.This work introduces CRoP, a novel static personalization approach using an off-the-shelf pre-trained model and pruning to optimize personalization and generalization. CRoP shows superior personalization effectiveness and intra-user robustness across four human-sensing datasets, including two from real-world health domains, highlighting its practical and social impact. Additionally, to support CRoP's generalization ability and design choices, we provide empirical justification through gradient inner product analysis, ablation studies, and comparisons against state-of-the-art baselines.
Privacy against Real-Time Speech Emotion Detection via Acoustic Adversarial Evasion of Machine Learning
Nov 17, 2022Emotional Surveillance is an emerging area with wide-reaching privacy concerns. These concerns are exacerbated by ubiquitous IoT devices with multiple sensors that can support these surveillance use cases. The work presented here considers one such use case: the use of a speech emotion recognition (SER) classifier tied to a smart speaker. This work demonstrates the ability to evade black-box SER classifiers tied to a smart speaker without compromising the utility of the smart speaker. This privacy concern is considered through the lens of adversarial evasion of machine learning. Our solution, Defeating Acoustic Recognition of Emotion via Genetic Programming (DARE-GP), uses genetic programming to generate non-invasive additive audio perturbations (AAPs). By constraining the evolution of these AAPs, transcription accuracy can be protected while simultaneously degrading SER classifier performance. The additive nature of these AAPs, along with an approach that generates these AAPs for a fixed set of users in an utterance and user location-independent manner, supports real-time, real-world evasion of SER classifiers. DARE-GP's use of spectral features, which underlay the emotional content of speech, allows the transferability of AAPs to previously unseen black-box SER classifiers. Further, DARE-GP outperforms state-of-the-art SER evasion techniques and is robust against defenses employed by a knowledgeable adversary. The evaluations in this work culminate with acoustic evaluations against two off-the-shelf commercial smart speakers, where a single AAP could evade a black box classifier over 70% of the time. The final evaluation deployed AAP playback on a small-form-factor system (raspberry pi) integrated with a wake-word system to evaluate the efficacy of a real-world, real-time deployment where DARE-GP is automatically invoked with the smart speaker's wake word.