 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWindINR: Latent-State INR for Fast Local Wind Query and Correction in Complex Terrain
May 10, 2026Many downstream decisions in complex terrain require fast wind estimates at a small number of user-specified locations and heights for a given forecast valid time, rather than another dense forecast field on a fixed grid. We present WindINR, a latent-state implicit neural representation framework for continuous high-resolution local wind query and sparse-observation correction. WindINR maps static terrain descriptors, a low-resolution background field, and continuous query coordinates to a high-resolution wind state through a latent-conditioned decoder. To enable rapid inference-time correction, WindINR separates reusable representation learning from sample-specific latent-state correction. During training, a privileged encoder infers a reference latent state from high-resolution supervision, a deployable latent predictor estimates an initial latent state from inference-time inputs alone, and their discrepancies are summarized into a dataset-adaptive Gaussian prior over latent corrections. At inference time, within the WindINR module, network weights remain fixed and only the latent state is updated by minimizing a regularized correction objective using sparse observations and their uncertainty. In controlled OSSEs over the Senja region, including a UAV-aided approach scenario and random-observation robustness tests, WindINR improves local high-resolution wind estimates by updating only a compact latent state rather than the full network. The corrected representation remains continuously queryable at arbitrary coordinates and, in our CPU benchmark, yields about a $2.6\times$ online-correction speedup over full-network fine-tuning, suggesting a practical interface between kilometer-scale background products, sparse local observations, and wind queries in complex terrain.
Earth-o1: A Grid-free Observation-native Atmospheric World Model
May 07, 2026Despite the unprecedented volume of multimodal data provided by modern Earth observation systems, our ability to model atmospheric dynamics remains constrained. Traditional modeling frameworks force heterogeneous measurements into predefined spatial grids, inherently limiting the full exploitation of raw sensor data and creating severe computational bottlenecks. Here we present Earth-o1, an observation-native atmospheric world model that overcomes these structural limitations. Rather than relying on conventional atmospheric dynamical modeling systems or traditional data assimilation, Earth-o1 directly learns the continuous, three-dimensional physical evolution of the Earth system from ungridded observational data. By integrating diverse sensor inputs into a unified, grid-free dynamical field, the model autonomously advances the atmospheric state in space and time. We show that this fundamentally distinct paradigm enables direct, real-time forecasting and cross-sensor inference without the overhead of explicit numerical solvers. In hindcast evaluations, Earth-o1 achieves surface forecast skill comparable to the operational Integrated Forecasting System (IFS). These results establish that continuous, observation-driven world models -- a new class of fully observation-native geophysical simulators -- can match the fidelity of established physical frameworks, providing a scalable data-driven foundation for a digital twin of the Earth.
SkCC: Portable and Secure Skill Compilation for Cross-Framework LLM Agents
May 05, 2026LLM-Agents have evolved into autonomous systems for complex task execution, with the SKILL.md specification emerging as a de facto standard for encapsulating agent capabilities. However, a critical bottleneck remains: different agent frameworks exhibit starkly different sensitivities to prompt formatting, causing up to 40% performance variation, yet nearly all skills exist as a single, format-agnostic Markdown version. Manual per-platform rewriting creates an unsustainable maintenance burden, while prior audits have found that over one third of community skills contain security vulnerabilities. To address this, we present SkCC, a compilation framework that introduces classical compiler design into agent skill development. At its core, SkIR - a strongly-typed intermediate representation - decouples skill semantics from platform-specific formatting, enabling portable deployment across heterogeneous agent frameworks. Around this IR, a compile-time Analyzer enforces security constraints via Anti-Skill Injection before deployment. Through a four-phase pipeline, SkCC reduces adaptation complexity from $O(m \times n)$ to $O(m + n)$. Experiments on SkillsBench demonstrate that compiled skills consistently outperform their original counterparts, improving pass rates from 21.1% to 33.3% on Claude Code and from 35.1% to 48.7% on Kimi CLI, while achieving sub-10ms compilation latency, a 94.8% proactive security trigger rate, and 10-46% runtime token savings across platforms.
Accurate and Efficient Hybrid-Ensemble Atmospheric Data Assimilation in Latent Space with Uncertainty Quantification
Mar 04, 2026Data assimilation (DA) combines model forecasts and observations to estimate the optimal state of the atmosphere with its uncertainty, providing initial conditions for weather prediction and reanalyses for climate research. Yet, existing traditional and machine-learning DA methods struggle to achieve accuracy, efficiency and uncertainty quantification simultaneously. Here, we propose HLOBA (Hybrid-Ensemble Latent Observation-Background Assimilation), a three-dimensional hybrid-ensemble DA method that operates in an atmospheric latent space learned via an autoencoder (AE). HLOBA maps both model forecasts and observations into a shared latent space via the AE encoder and an end-to-end Observation-to-Latent-space mapping network (O2Lnet), respectively, and fuses them through a Bayesian update with weights inferred from time-lagged ensemble forecasts. Both idealized and real-observation experiments demonstrate that HLOBA matches dynamically constrained four-dimensional DA methods in both analysis and forecast skill, while achieving end-to-end inference-level efficiency and theoretical flexibility applies to any forecasting model. Moreover, by exploiting the error decorrelation property of latent variables, HLOBA enables element-wise uncertainty estimates for its latent analysis and propagates them to model space via the decoder. Idealized experiments show that this uncertainty highlights large-error regions and captures their seasonal variability.
AppleVLM: End-to-end Autonomous Driving with Advanced Perception and Planning-Enhanced Vision-Language Models
Feb 04, 2026End-to-end autonomous driving has emerged as a promising paradigm integrating perception, decision-making, and control within a unified learning framework. Recently, Vision-Language Models (VLMs) have gained significant attention for their potential to enhance the robustness and generalization of end-to-end driving models in diverse and unseen scenarios. However, existing VLM-based approaches still face challenges, including suboptimal lane perception, language understanding biases, and difficulties in handling corner cases. To address these issues, we propose AppleVLM, an advanced perception and planning-enhanced VLM model for robust end-to-end driving. AppleVLM introduces a novel vision encoder and a planning strategy encoder to improve perception and decision-making. Firstly, the vision encoder fuses spatial-temporal information from multi-view images across multiple timesteps using a deformable transformer mechanism, enhancing robustness to camera variations and facilitating scalable deployment across different vehicle platforms. Secondly, unlike traditional VLM-based approaches, AppleVLM introduces a dedicated planning modality that encodes explicit Bird's-Eye-View spatial information, mitigating language biases in navigation instructions. Finally, a VLM decoder fine-tuned by a hierarchical Chain-of-Thought integrates vision, language, and planning features to output robust driving waypoints. We evaluate AppleVLM in closed-loop experiments on two CARLA benchmarks, achieving state-of-the-art driving performance. Furthermore, we deploy AppleVLM on an AGV platform and successfully showcase real-world end-to-end autonomous driving in complex outdoor environments.
Semantics and Content Matter: Towards Multi-Prior Hierarchical Mamba for Image Deraining
Nov 17, 2025Rain significantly degrades the performance of computer vision systems, particularly in applications like autonomous driving and video surveillance. While existing deraining methods have made considerable progress, they often struggle with fidelity of semantic and spatial details. To address these limitations, we propose the Multi-Prior Hierarchical Mamba (MPHM) network for image deraining. This novel architecture synergistically integrates macro-semantic textual priors (CLIP) for task-level semantic guidance and micro-structural visual priors (DINOv2) for scene-aware structural information. To alleviate potential conflicts between heterogeneous priors, we devise a progressive Priors Fusion Injection (PFI) that strategically injects complementary cues at different decoder levels. Meanwhile, we equip the backbone network with an elaborate Hierarchical Mamba Module (HMM) to facilitate robust feature representation, featuring a Fourier-enhanced dual-path design that concurrently addresses global context modeling and local detail recovery. Comprehensive experiments demonstrate MPHM's state-of-the-art performance, achieving a 0.57 dB PSNR gain on the Rain200H dataset while delivering superior generalization on real-world rainy scenarios.
Designing Cyclic Peptides via Harmonic SDE with Atom-Bond Modeling
May 27, 2025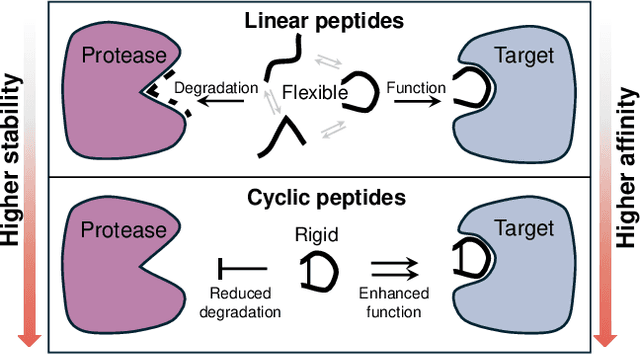
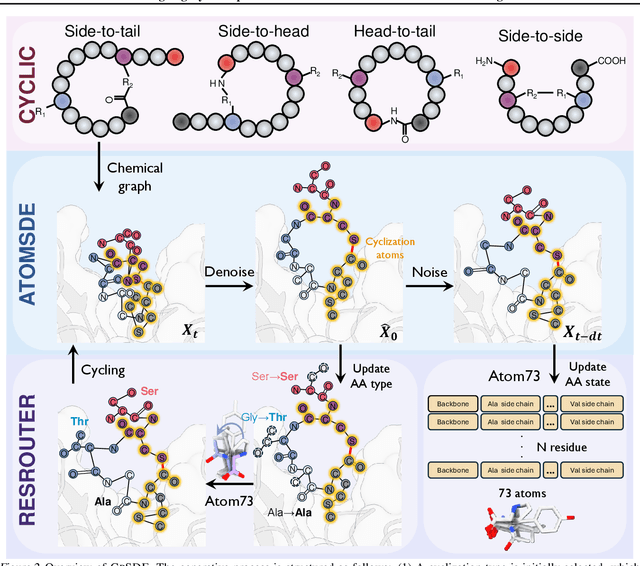
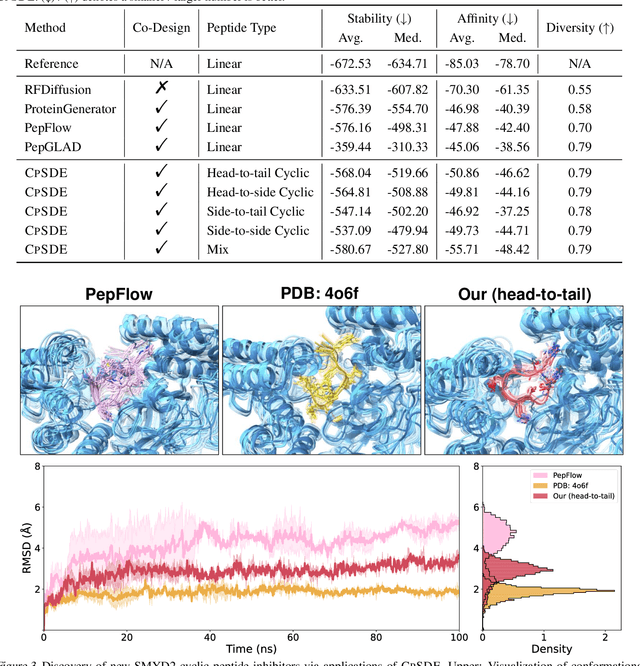
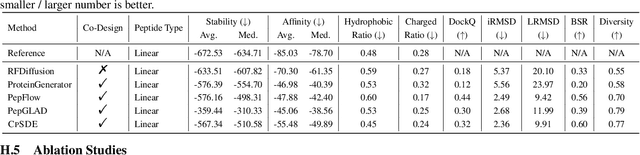
Cyclic peptides offer inherent advantages in pharmaceuticals. For example, cyclic peptides are more resistant to enzymatic hydrolysis compared to linear peptides and usually exhibit excellent stability and affinity. Although deep generative models have achieved great success in linear peptide design, several challenges prevent the development of computational methods for designing diverse types of cyclic peptides. These challenges include the scarcity of 3D structural data on target proteins and associated cyclic peptide ligands, the geometric constraints that cyclization imposes, and the involvement of non-canonical amino acids in cyclization. To address the above challenges, we introduce CpSDE, which consists of two key components: AtomSDE, a generative structure prediction model based on harmonic SDE, and ResRouter, a residue type predictor. Utilizing a routed sampling algorithm that alternates between these two models to iteratively update sequences and structures, CpSDE facilitates the generation of cyclic peptides. By employing explicit all-atom and bond modeling, CpSDE overcomes existing data limitations and is proficient in designing a wide variety of cyclic peptides. Our experimental results demonstrate that the cyclic peptides designed by our method exhibit reliable stability and affinity.
PAD: Phase-Amplitude Decoupling Fusion for Multi-Modal Land Cover Classification
Apr 27, 2025The fusion of Synthetic Aperture Radar (SAR) and RGB imagery for land cover classification remains challenging due to modality heterogeneity and the underutilization of spectral complementarity. Existing methods often fail to decouple shared structural features from modality-specific radiometric attributes, leading to feature conflicts and information loss. To address this issue, we propose Phase-Amplitude Decoupling (PAD), a frequency-aware framework that separates phase (modality-shared) and amplitude (modality-specific) components in the Fourier domain. Specifically, PAD consists of two key components: 1) Phase Spectrum Correction (PSC), which aligns cross-modal phase features through convolution-guided scaling to enhance geometric consistency, and 2) Amplitude Spectrum Fusion (ASF), which dynamically integrates high-frequency details and low-frequency structures using frequency-adaptive multilayer perceptrons. This approach leverages SAR's sensitivity to morphological features and RGB's spectral richness. Extensive experiments on WHU-OPT-SAR and DDHR-SK datasets demonstrate state-of-the-art performance. Our work establishes a new paradigm for physics-aware multi-modal fusion in remote sensing. The code will be available at https://github.com/RanFeng2/PAD.
R$^2$: A LLM Based Novel-to-Screenplay Generation Framework with Causal Plot Graphs
Mar 19, 2025



Automatically adapting novels into screenplays is important for the TV, film, or opera industries to promote products with low costs. The strong performances of large language models (LLMs) in long-text generation call us to propose a LLM based framework Reader-Rewriter (R$^2$) for this task. However, there are two fundamental challenges here. First, the LLM hallucinations may cause inconsistent plot extraction and screenplay generation. Second, the causality-embedded plot lines should be effectively extracted for coherent rewriting. Therefore, two corresponding tactics are proposed: 1) A hallucination-aware refinement method (HAR) to iteratively discover and eliminate the affections of hallucinations; and 2) a causal plot-graph construction method (CPC) based on a greedy cycle-breaking algorithm to efficiently construct plot lines with event causalities. Recruiting those efficient techniques, R$^2$ utilizes two modules to mimic the human screenplay rewriting process: The Reader module adopts a sliding window and CPC to build the causal plot graphs, while the Rewriter module generates first the scene outlines based on the graphs and then the screenplays. HAR is integrated into both modules for accurate inferences of LLMs. Experimental results demonstrate the superiority of R$^2$, which substantially outperforms three existing approaches (51.3%, 22.6%, and 57.1% absolute increases) in pairwise comparison at the overall win rate for GPT-4o.
Multimodal Feature-Driven Deep Learning for the Prediction of Duck Body Dimensions and Weight
Mar 19, 2025Accurate body dimension and weight measurements are critical for optimizing poultry management, health assessment, and economic efficiency. This study introduces an innovative deep learning-based model leveraging multimodal data-2D RGB images from different views, depth images, and 3D point clouds-for the non-invasive estimation of duck body dimensions and weight. A dataset of 1,023 Linwu ducks, comprising over 5,000 samples with diverse postures and conditions, was collected to support model training. The proposed method innovatively employs PointNet++ to extract key feature points from point clouds, extracts and computes corresponding 3D geometric features, and fuses them with multi-view convolutional 2D features. A Transformer encoder is then utilized to capture long-range dependencies and refine feature interactions, thereby enhancing prediction robustness. The model achieved a mean absolute percentage error (MAPE) of 6.33% and an R2 of 0.953 across eight morphometric parameters, demonstrating strong predictive capability. Unlike conventional manual measurements, the proposed model enables high-precision estimation while eliminating the necessity for physical handling, thereby reducing animal stress and broadening its application scope. This study marks the first application of deep learning techniques to poultry body dimension and weight estimation, providing a valuable reference for the intelligent and precise management of the livestock industry with far-reaching practical significance.