 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmoothing Dark Areas in Molecular Latent Diffusion
Jun 11, 2026Latent diffusion is a promising framework for scalable 3D molecular generation, but it requires a latent space that remains smooth, valid, and navigable beyond posterior samples. Existing molecular VAEs, however, are typically learned through reconstruction-based objectives, which do not guarantee such a latent space. We show that this leads to dark areas: regions of latent space that are reachable during diffusion sampling but decode to disconnected or chemically invalid molecules. Unlike in image generation, molecular decoding requires strict structural and chemical precision, so even small latent perturbations can produce catastrophic failures. We therefore propose TopVAE, a topology-optimized VAE that reduces dark areas by making the decoder internalize structural and chemical constraints during training, eliminating the need for test-time chemical correction. TopVAE greatly improves off-posterior robustness, and when paired with a standard DiT, achieves $77\%$ lower FCD-3D on QM9, the highest V&C, $52\%$ lower FCD-3D on GEOM-Drugs, and $1.29{\times}$ more stable and connected molecules on zero-shot scaffold inpainting.
DFPO: Scaling Value Modeling via Distributional Flow towards Robust and Generalizable LLM Post-Training
Feb 05, 2026Training reinforcement learning (RL) systems in real-world environments remains challenging due to noisy supervision and poor out-of-domain (OOD) generalization, especially in LLM post-training. Recent distributional RL methods improve robustness by modeling values with multiple quantile points, but they still learn each quantile independently as a scalar. This results in rough-grained value representations that lack fine-grained conditioning on state information, struggling under complex and OOD conditions. We propose DFPO (Distributional Value Flow Policy Optimization with Conditional Risk and Consistency Control), a robust distributional RL framework that models values as continuous flows across time steps. By scaling value modeling through learning of a value flow field instead of isolated quantile predictions, DFPO captures richer state information for more accurate advantage estimation. To stabilize training under noisy feedback, DFPO further integrates conditional risk control and consistency constraints along value flow trajectories. Experiments on dialogue, math reasoning, and scientific tasks show that DFPO outperforms PPO, FlowRL, and other robust baselines under noisy supervision, achieving improved training stability and generalization.
AHDMIL: Asymmetric Hierarchical Distillation Multi-Instance Learning for Fast and Accurate Whole-Slide Image Classification
Aug 07, 2025Although multi-instance learning (MIL) has succeeded in pathological image classification, it faces the challenge of high inference costs due to the need to process thousands of patches from each gigapixel whole slide image (WSI). To address this, we propose AHDMIL, an Asymmetric Hierarchical Distillation Multi-Instance Learning framework that enables fast and accurate classification by eliminating irrelevant patches through a two-step training process. AHDMIL comprises two key components: the Dynamic Multi-Instance Network (DMIN), which operates on high-resolution WSIs, and the Dual-Branch Lightweight Instance Pre-screening Network (DB-LIPN), which analyzes corresponding low-resolution counterparts. In the first step, self-distillation (SD), DMIN is trained for WSI classification while generating per-instance attention scores to identify irrelevant patches. These scores guide the second step, asymmetric distillation (AD), where DB-LIPN learns to predict the relevance of each low-resolution patch. The relevant patches predicted by DB-LIPN have spatial correspondence with patches in high-resolution WSIs, which are used for fine-tuning and efficient inference of DMIN. In addition, we design the first Chebyshev-polynomial-based Kolmogorov-Arnold (CKA) classifier in computational pathology, which improves classification performance through learnable activation layers. Extensive experiments on four public datasets demonstrate that AHDMIL consistently outperforms previous state-of-the-art methods in both classification performance and inference speed. For example, on the Camelyon16 dataset, it achieves a relative improvement of 5.3% in accuracy and accelerates inference by 1.2.times. Across all datasets, area under the curve (AUC), accuracy, f1 score, and brier score show consistent gains, with average inference speedups ranging from 1.2 to 2.1 times. The code is available.
Designing Cyclic Peptides via Harmonic SDE with Atom-Bond Modeling
May 27, 2025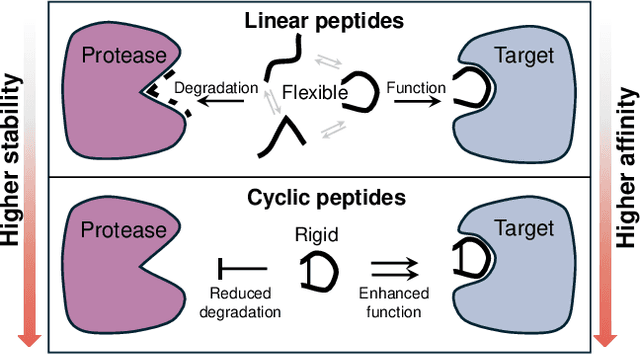
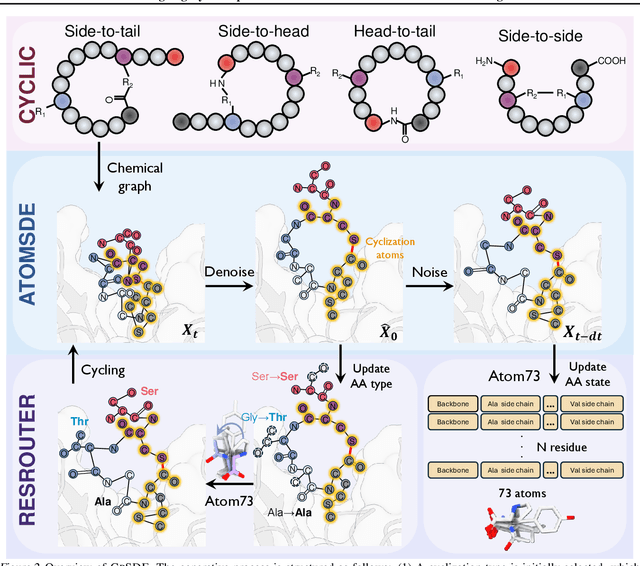
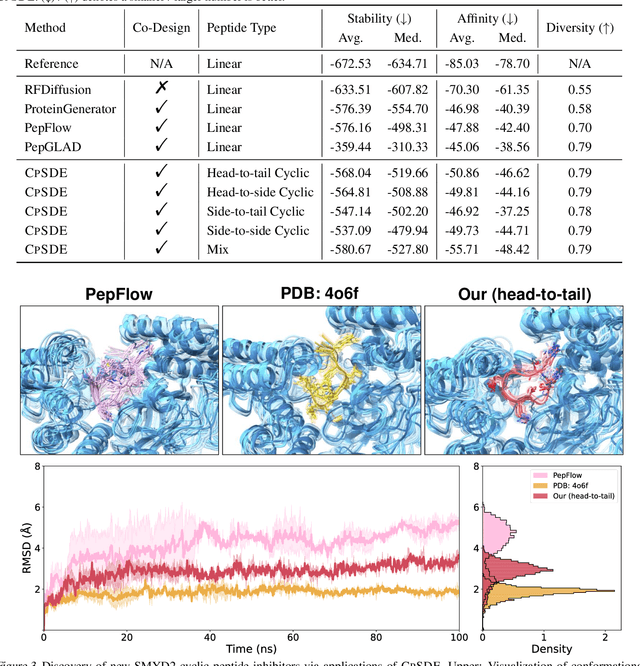
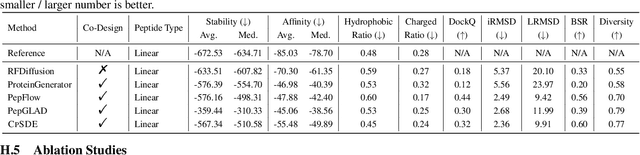
Cyclic peptides offer inherent advantages in pharmaceuticals. For example, cyclic peptides are more resistant to enzymatic hydrolysis compared to linear peptides and usually exhibit excellent stability and affinity. Although deep generative models have achieved great success in linear peptide design, several challenges prevent the development of computational methods for designing diverse types of cyclic peptides. These challenges include the scarcity of 3D structural data on target proteins and associated cyclic peptide ligands, the geometric constraints that cyclization imposes, and the involvement of non-canonical amino acids in cyclization. To address the above challenges, we introduce CpSDE, which consists of two key components: AtomSDE, a generative structure prediction model based on harmonic SDE, and ResRouter, a residue type predictor. Utilizing a routed sampling algorithm that alternates between these two models to iteratively update sequences and structures, CpSDE facilitates the generation of cyclic peptides. By employing explicit all-atom and bond modeling, CpSDE overcomes existing data limitations and is proficient in designing a wide variety of cyclic peptides. Our experimental results demonstrate that the cyclic peptides designed by our method exhibit reliable stability and affinity.
$α$-Flow: A Unified Framework for Continuous-State Discrete Flow Matching Models
Apr 14, 2025Recent efforts have extended the flow-matching framework to discrete generative modeling. One strand of models directly works with the continuous probabilities instead of discrete tokens, which we colloquially refer to as Continuous-State Discrete Flow Matching (CS-DFM). Existing CS-DFM models differ significantly in their representations and geometric assumptions. This work presents a unified framework for CS-DFM models, under which the existing variants can be understood as operating on different $\alpha$-representations of probabilities. Building upon the theory of information geometry, we introduce $\alpha$-Flow, a family of CS-DFM models that adheres to the canonical $\alpha$-geometry of the statistical manifold, and demonstrate its optimality in minimizing the generalized kinetic energy. Theoretically, we show that the flow matching loss for $\alpha$-flow establishes a unified variational bound for the discrete negative log-likelihood. We comprehensively evaluate different instantiations of $\alpha$-flow on various discrete generation domains to demonstrate their effectiveness in discrete generative modeling, including intermediate values whose geometries have never been explored before. $\alpha$-flow significantly outperforms its discrete-state counterpart in image and protein sequence generation and better captures the entropy in language modeling.
Fast and Accurate Gigapixel Pathological Image Classification with Hierarchical Distillation Multi-Instance Learning
Feb 28, 2025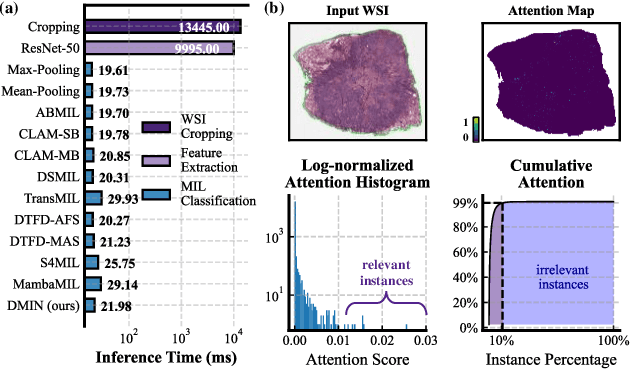
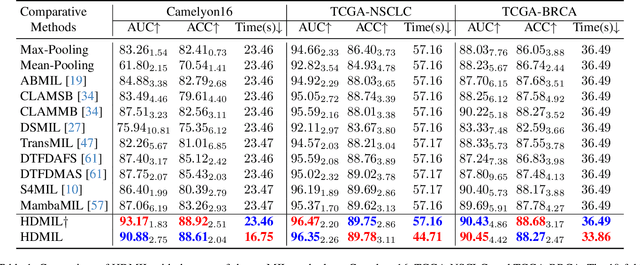
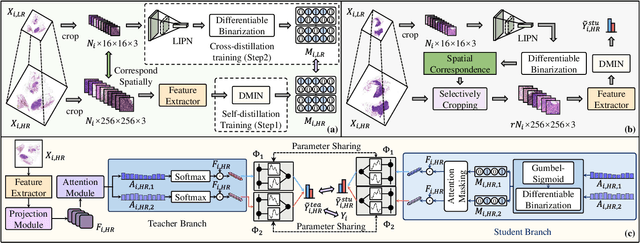
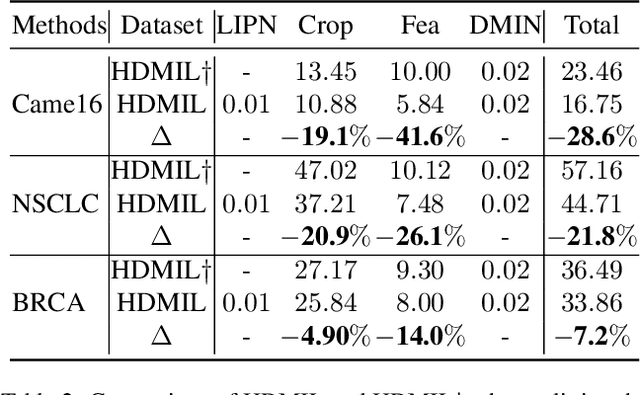
Although multi-instance learning (MIL) has succeeded in pathological image classification, it faces the challenge of high inference costs due to processing numerous patches from gigapixel whole slide images (WSIs). To address this, we propose HDMIL, a hierarchical distillation multi-instance learning framework that achieves fast and accurate classification by eliminating irrelevant patches. HDMIL consists of two key components: the dynamic multi-instance network (DMIN) and the lightweight instance pre-screening network (LIPN). DMIN operates on high-resolution WSIs, while LIPN operates on the corresponding low-resolution counterparts. During training, DMIN are trained for WSI classification while generating attention-score-based masks that indicate irrelevant patches. These masks then guide the training of LIPN to predict the relevance of each low-resolution patch. During testing, LIPN first determines the useful regions within low-resolution WSIs, which indirectly enables us to eliminate irrelevant regions in high-resolution WSIs, thereby reducing inference time without causing performance degradation. In addition, we further design the first Chebyshev-polynomials-based Kolmogorov-Arnold classifier in computational pathology, which enhances the performance of HDMIL through learnable activation layers. Extensive experiments on three public datasets demonstrate that HDMIL outperforms previous state-of-the-art methods, e.g., achieving improvements of 3.13% in AUC while reducing inference time by 28.6% on the Camelyon16 dataset.
Group Ligands Docking to Protein Pockets
Jan 25, 2025



Molecular docking is a key task in computational biology that has attracted increasing interest from the machine learning community. While existing methods have achieved success, they generally treat each protein-ligand pair in isolation. Inspired by the biochemical observation that ligands binding to the same target protein tend to adopt similar poses, we propose \textsc{GroupBind}, a novel molecular docking framework that simultaneously considers multiple ligands docking to a protein. This is achieved by introducing an interaction layer for the group of ligands and a triangle attention module for embedding protein-ligand and group-ligand pairs. By integrating our approach with diffusion-based docking model, we set a new S performance on the PDBBind blind docking benchmark, demonstrating the effectiveness of our proposed molecular docking paradigm.
Driving with InternVL: Oustanding Champion in the Track on Driving with Language of the Autonomous Grand Challenge at CVPR 2024
Dec 10, 2024This technical report describes the methods we employed for the Driving with Language track of the CVPR 2024 Autonomous Grand Challenge. We utilized a powerful open-source multimodal model, InternVL-1.5, and conducted a full-parameter fine-tuning on the competition dataset, DriveLM-nuScenes. To effectively handle the multi-view images of nuScenes and seamlessly inherit InternVL's outstanding multimodal understanding capabilities, we formatted and concatenated the multi-view images in a specific manner. This ensured that the final model could meet the specific requirements of the competition task while leveraging InternVL's powerful image understanding capabilities. Meanwhile, we designed a simple automatic annotation strategy that converts the center points of objects in DriveLM-nuScenes into corresponding bounding boxes. As a result, our single model achieved a score of 0.6002 on the final leadboard.
Hotspot-Driven Peptide Design via Multi-Fragment Autoregressive Extension
Nov 26, 2024



Peptides, short chains of amino acids, interact with target proteins, making them a unique class of protein-based therapeutics for treating human diseases. Recently, deep generative models have shown great promise in peptide generation. However, several challenges remain in designing effective peptide binders. First, not all residues contribute equally to peptide-target interactions. Second, the generated peptides must adopt valid geometries due to the constraints of peptide bonds. Third, realistic tasks for peptide drug development are still lacking. To address these challenges, we introduce PepHAR, a hot-spot-driven autoregressive generative model for designing peptides targeting specific proteins. Building on the observation that certain hot spot residues have higher interaction potentials, we first use an energy-based density model to fit and sample these key residues. Next, to ensure proper peptide geometry, we autoregressively extend peptide fragments by estimating dihedral angles between residue frames. Finally, we apply an optimization process to iteratively refine fragment assembly, ensuring correct peptide structures. By combining hot spot sampling with fragment-based extension, our approach enables de novo peptide design tailored to a target protein and allows the incorporation of key hot spot residues into peptide scaffolds. Extensive experiments, including peptide design and peptide scaffold generation, demonstrate the strong potential of PepHAR in computational peptide binder design.
Geometric Point Attention Transformer for 3D Shape Reassembly
Nov 26, 2024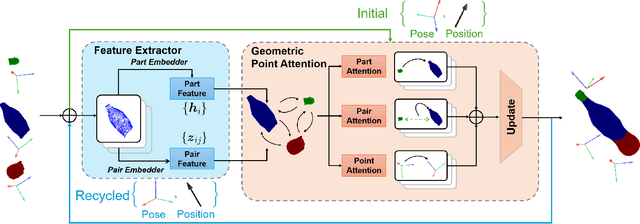

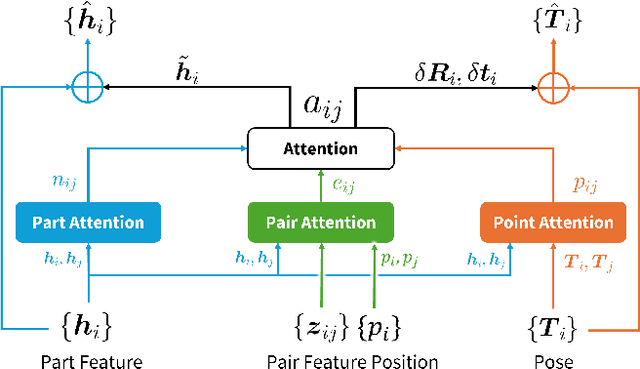

Shape assembly, which aims to reassemble separate parts into a complete object, has gained significant interest in recent years. Existing methods primarily rely on networks to predict the poses of individual parts, but often fail to effectively capture the geometric interactions between the parts and their poses. In this paper, we present the Geometric Point Attention Transformer (GPAT), a network specifically designed to address the challenges of reasoning about geometric relationships. In the geometric point attention module, we integrate both global shape information and local pairwise geometric features, along with poses represented as rotation and translation vectors for each part. To enable iterative updates and dynamic reasoning, we introduce a geometric recycling scheme, where each prediction is fed into the next iteration for refinement. We evaluate our model on both the semantic and geometric assembly tasks, showing that it outperforms previous methods in absolute pose estimation, achieving accurate pose predictions and high alignment accuracy.