 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFull-Atom Peptide Design based on Multi-modal Flow Matching
Jun 02, 2024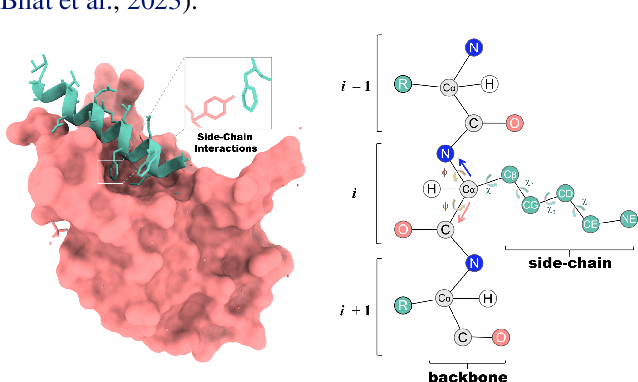
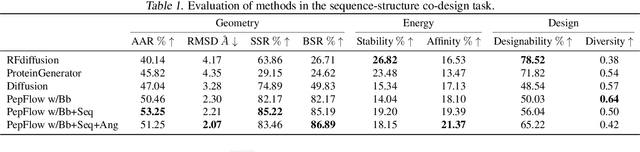
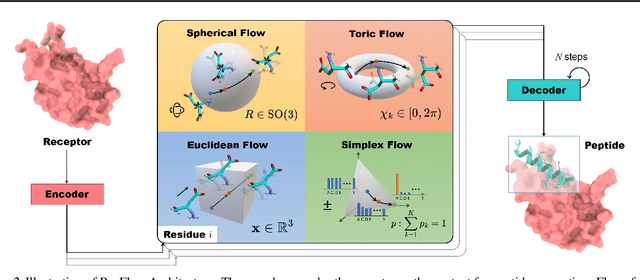
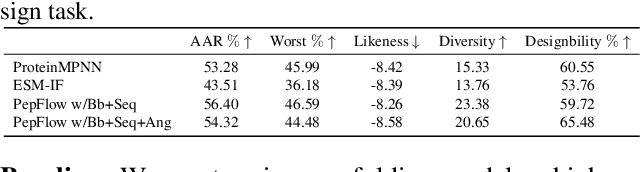
Peptides, short chains of amino acid residues, play a vital role in numerous biological processes by interacting with other target molecules, offering substantial potential in drug discovery. In this work, we present PepFlow, the first multi-modal deep generative model grounded in the flow-matching framework for the design of full-atom peptides that target specific protein receptors. Drawing inspiration from the crucial roles of residue backbone orientations and side-chain dynamics in protein-peptide interactions, we characterize the peptide structure using rigid backbone frames within the $\mathrm{SE}(3)$ manifold and side-chain angles on high-dimensional tori. Furthermore, we represent discrete residue types in the peptide sequence as categorical distributions on the probability simplex. By learning the joint distributions of each modality using derived flows and vector fields on corresponding manifolds, our method excels in the fine-grained design of full-atom peptides. Harnessing the multi-modal paradigm, our approach adeptly tackles various tasks such as fix-backbone sequence design and side-chain packing through partial sampling. Through meticulously crafted experiments, we demonstrate that PepFlow exhibits superior performance in comprehensive benchmarks, highlighting its significant potential in computational peptide design and analysis.
DeepSeek-Prover: Advancing Theorem Proving in LLMs through Large-Scale Synthetic Data
May 23, 2024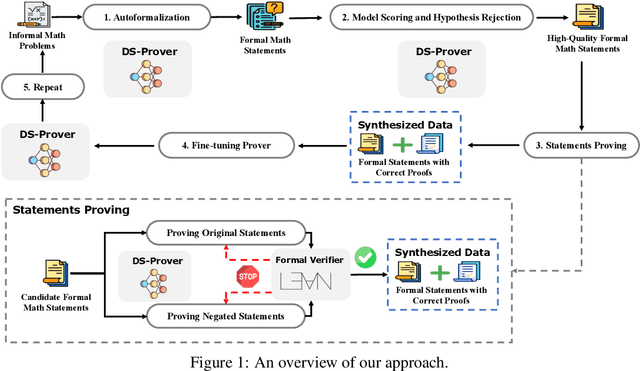



Proof assistants like Lean have revolutionized mathematical proof verification, ensuring high accuracy and reliability. Although large language models (LLMs) show promise in mathematical reasoning, their advancement in formal theorem proving is hindered by a lack of training data. To address this issue, we introduce an approach to generate extensive Lean 4 proof data derived from high-school and undergraduate-level mathematical competition problems. This approach involves translating natural language problems into formal statements, filtering out low-quality statements, and generating proofs to create synthetic data. After fine-tuning the DeepSeekMath 7B model on this synthetic dataset, which comprises 8 million formal statements with proofs, our model achieved whole-proof generation accuracies of 46.3% with 64 samples and 52% cumulatively on the Lean 4 miniF2F test, surpassing the baseline GPT-4 at 23.0% with 64 samples and a tree search reinforcement learning method at 41.0%. Additionally, our model successfully proved 5 out of 148 problems in the Lean 4 Formalized International Mathematical Olympiad (FIMO) benchmark, while GPT-4 failed to prove any. These results demonstrate the potential of leveraging large-scale synthetic data to enhance theorem-proving capabilities in LLMs. Both the synthetic dataset and the model will be made available to facilitate further research in this promising field.
Efficient Meta Reinforcement Learning for Preference-based Fast Adaptation
Nov 20, 2022


Learning new task-specific skills from a few trials is a fundamental challenge for artificial intelligence. Meta reinforcement learning (meta-RL) tackles this problem by learning transferable policies that support few-shot adaptation to unseen tasks. Despite recent advances in meta-RL, most existing methods require the access to the environmental reward function of new tasks to infer the task objective, which is not realistic in many practical applications. To bridge this gap, we study the problem of few-shot adaptation in the context of human-in-the-loop reinforcement learning. We develop a meta-RL algorithm that enables fast policy adaptation with preference-based feedback. The agent can adapt to new tasks by querying human's preference between behavior trajectories instead of using per-step numeric rewards. By extending techniques from information theory, our approach can design query sequences to maximize the information gain from human interactions while tolerating the inherent error of non-expert human oracle. In experiments, we extensively evaluate our method, Adaptation with Noisy OracLE (ANOLE), on a variety of meta-RL benchmark tasks and demonstrate substantial improvement over baseline algorithms in terms of both feedback efficiency and error tolerance.
Self-Organized Polynomial-Time Coordination Graphs
Dec 07, 2021
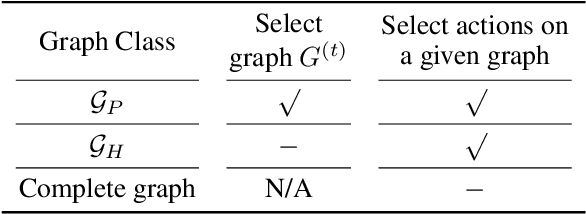
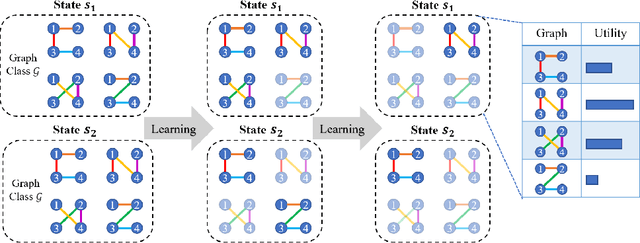

Coordination graph is a promising approach to model agent collaboration in multi-agent reinforcement learning. It factorizes a large multi-agent system into a suite of overlapping groups that represent the underlying coordination dependencies. One critical challenge in this paradigm is the complexity of computing maximum-value actions for a graph-based value factorization. It refers to the decentralized constraint optimization problem (DCOP), which and whose constant-ratio approximation are NP-hard problems. To bypass this fundamental hardness, this paper proposes a novel method, named Self-Organized Polynomial-time Coordination Graphs (SOP-CG), which uses structured graph classes to guarantee the optimality of the induced DCOPs with sufficient function expressiveness. We extend the graph topology to be state-dependent, formulate the graph selection as an imaginary agent, and finally derive an end-to-end learning paradigm from the unified Bellman optimality equation. In experiments, we show that our approach learns interpretable graph topologies, induces effective coordination, and improves performance across a variety of cooperative multi-agent tasks.
Learning Long-Term Reward Redistribution via Randomized Return Decomposition
Nov 26, 2021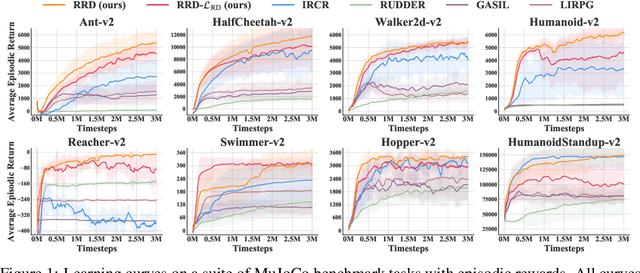
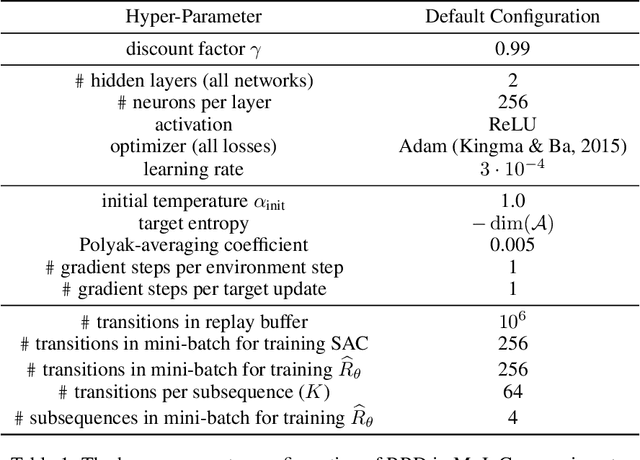
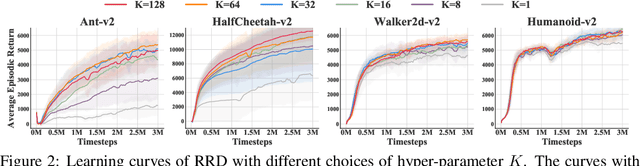
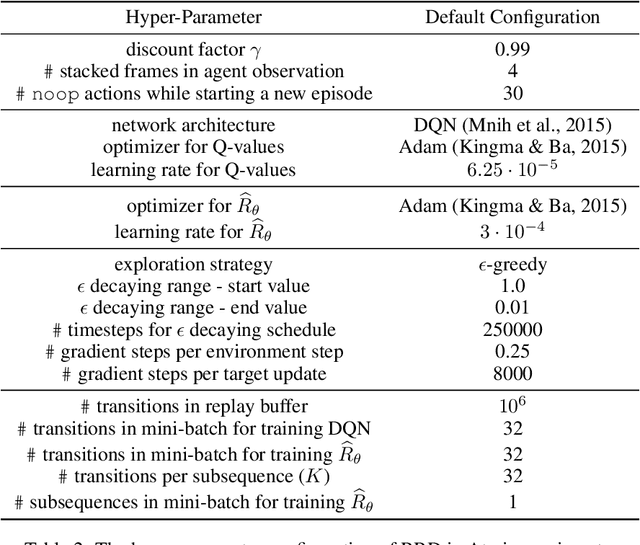
Many practical applications of reinforcement learning require agents to learn from sparse and delayed rewards. It challenges the ability of agents to attribute their actions to future outcomes. In this paper, we consider the problem formulation of episodic reinforcement learning with trajectory feedback. It refers to an extreme delay of reward signals, in which the agent can only obtain one reward signal at the end of each trajectory. A popular paradigm for this problem setting is learning with a designed auxiliary dense reward function, namely proxy reward, instead of sparse environmental signals. Based on this framework, this paper proposes a novel reward redistribution algorithm, randomized return decomposition (RRD), to learn a proxy reward function for episodic reinforcement learning. We establish a surrogate problem by Monte-Carlo sampling that scales up least-squares-based reward redistribution to long-horizon problems. We analyze our surrogate loss function by connection with existing methods in the literature, which illustrates the algorithmic properties of our approach. In experiments, we extensively evaluate our proposed method on a variety of benchmark tasks with episodic rewards and demonstrate substantial improvement over baseline algorithms.
On the Estimation Bias in Double Q-Learning
Sep 29, 2021

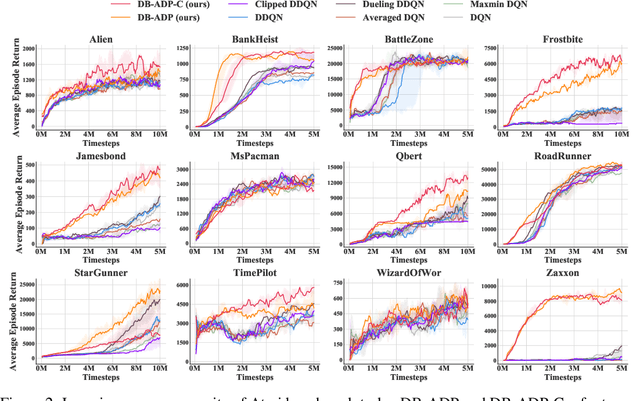

Double Q-learning is a classical method for reducing overestimation bias, which is caused by taking maximum estimated values in the Bellman operation. Its variants in the deep Q-learning paradigm have shown great promise in producing reliable value prediction and improving learning performance. However, as shown by prior work, double Q-learning is not fully unbiased and suffers from underestimation bias. In this paper, we show that such underestimation bias may lead to multiple non-optimal fixed points under an approximated Bellman operator. To address the concerns of converging to non-optimal stationary solutions, we propose a simple but effective approach as a partial fix for the underestimation bias in double Q-learning. This approach leverages an approximate dynamic programming to bound the target value. We extensively evaluate our proposed method in the Atari benchmark tasks and demonstrate its significant improvement over baseline algorithms.
Off-Policy Reinforcement Learning with Delayed Rewards
Jun 22, 2021
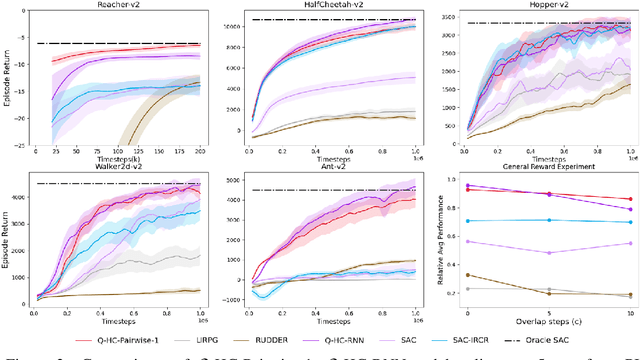
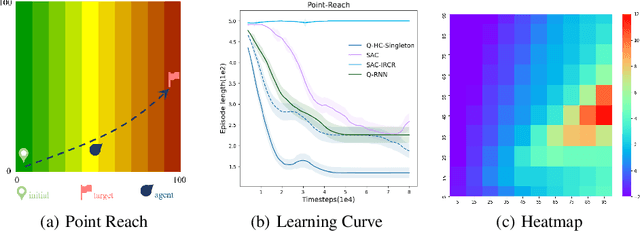
We study deep reinforcement learning (RL) algorithms with delayed rewards. In many real-world tasks, instant rewards are often not readily accessible or even defined immediately after the agent performs actions. In this work, we first formally define the environment with delayed rewards and discuss the challenges raised due to the non-Markovian nature of such environments. Then, we introduce a general off-policy RL framework with a new Q-function formulation that can handle the delayed rewards with theoretical convergence guarantees. For practical tasks with high dimensional state spaces, we further introduce the HC-decomposition rule of the Q-function in our framework which naturally leads to an approximation scheme that helps boost the training efficiency and stability. We finally conduct extensive experiments to demonstrate the superior performance of our algorithms over the existing work and their variants.
Generalizable Episodic Memory for Deep Reinforcement Learning
Mar 11, 2021


Episodic memory-based methods can rapidly latch onto past successful strategies by a non-parametric memory and improve sample efficiency of traditional reinforcement learning. However, little effort is put into the continuous domain, where a state is never visited twice and previous episodic methods fail to efficiently aggregate experience across trajectories. To address this problem, we propose Generalizable Episodic Memory (GEM), which effectively organizes the state-action values of episodic memory in a generalizable manner and supports implicit planning on memorized trajectories. GEM utilizes a double estimator to reduce the overestimation bias induced by value propagation in the planning process. Empirical evaluation shows that our method significantly outperforms existing trajectory-based methods on various MuJoCo continuous control tasks. To further show the general applicability, we evaluate our method on Atari games with discrete action space, which also shows significant improvement over baseline algorithms.
QPLEX: Duplex Dueling Multi-Agent Q-Learning
Aug 03, 2020



We explore value-based multi-agent reinforcement learning (MARL) in the popular paradigm of centralized training with decentralized execution (CTDE). CTDE requires the consistency of the optimal joint action selection with optimal individual action selections, which is called the IGM (Individual-Global-Max) principle. However, in order to achieve scalability, existing MARL methods either limit representation expressiveness of their value function classes or relax the IGM consistency, which may lead to poor policies or even divergence. This paper presents a novel MARL approach, called duPLEX dueling multi-agent Q-learning (QPLEX), that takes a duplex dueling network architecture to factorize the joint value function. This duplex dueling architecture transforms the IGM principle to easily realized constraints on advantage functions and thus enables efficient value function learning. Theoretical analysis shows that QPLEX solves a rich class of tasks. Empirical experiments on StarCraft II unit micromanagement tasks demonstrate that QPLEX significantly outperforms state-of-the-art baselines in both online and offline task settings, and also reveal that QPLEX achieves high sample efficiency and can benefit from offline datasets without additional exploration.
Towards Understanding Linear Value Decomposition in Cooperative Multi-Agent Q-Learning
Jun 23, 2020
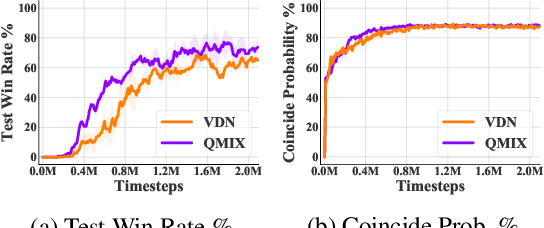

Value decomposition is a popular and promising approach to scaling up multi-agent reinforcement learning in cooperative settings. However, the theoretical understanding of such methods is limited. In this paper, we introduce a variant of the fitted Q-iteration framework for analyzing multi-agent Q-learning with value decomposition. Based on this framework, we derive a closed-form solution to the Bellman error minimization with linear value decomposition. With this novel solution, we further reveal two interesting insights: 1) linear value decomposition implicitly implements a classical multi-agent credit assignment called counterfactual difference rewards; and 2) multi-agent Q-learning with linear value decomposition requires on-policy data distribution to achieve numerical stability. In the empirical study, our experiments demonstrate the realizability of our theoretical implications in a broad set of complicated tasks. They show that most state-of-the-art deep multi-agent Q-learning algorithms using linear value decomposition cannot efficiently utilize off-policy samples, which may even lead to an unbounded divergence.