 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProposer-Agent-Evaluator(PAE): Autonomous Skill Discovery For Foundation Model Internet Agents
Dec 17, 2024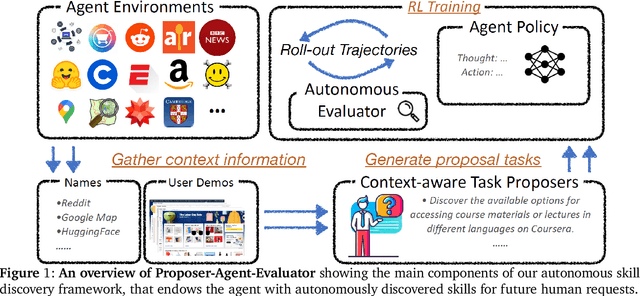
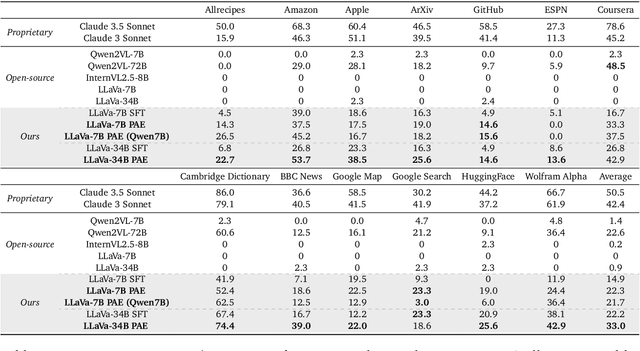
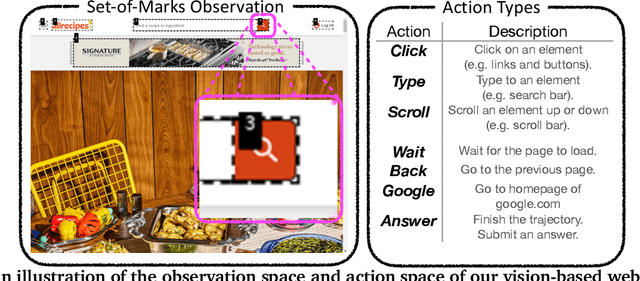
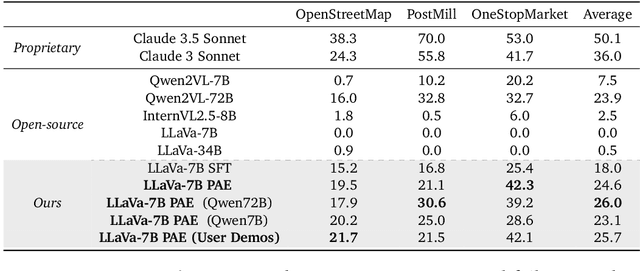
The vision of a broadly capable and goal-directed agent, such as an Internet-browsing agent in the digital world and a household humanoid in the physical world, has rapidly advanced, thanks to the generalization capability of foundation models. Such a generalist agent needs to have a large and diverse skill repertoire, such as finding directions between two travel locations and buying specific items from the Internet. If each skill needs to be specified manually through a fixed set of human-annotated instructions, the agent's skill repertoire will necessarily be limited due to the quantity and diversity of human-annotated instructions. In this work, we address this challenge by proposing Proposer-Agent-Evaluator, an effective learning system that enables foundation model agents to autonomously discover and practice skills in the wild. At the heart of PAE is a context-aware task proposer that autonomously proposes tasks for the agent to practice with context information of the environment such as user demos or even just the name of the website itself for Internet-browsing agents. Then, the agent policy attempts those tasks with thoughts and actual grounded operations in the real world with resulting trajectories evaluated by an autonomous VLM-based success evaluator. The success evaluation serves as the reward signal for the agent to refine its policies through RL. We validate PAE on challenging vision-based web navigation, using both real-world and self-hosted websites from WebVoyager and WebArena.To the best of our knowledge, this work represents the first effective learning system to apply autonomous task proposal with RL for agents that generalizes real-world human-annotated benchmarks with SOTA performances. Our open-source checkpoints and code can be found in https://yanqval.github.io/PAE/
PA-LLaVA: A Large Language-Vision Assistant for Human Pathology Image Understanding
Aug 18, 2024The previous advancements in pathology image understanding primarily involved developing models tailored to specific tasks. Recent studies has demonstrated that the large vision-language model can enhance the performance of various downstream tasks in medical image understanding. In this study, we developed a domain-specific large language-vision assistant (PA-LLaVA) for pathology image understanding. Specifically, (1) we first construct a human pathology image-text dataset by cleaning the public medical image-text data for domain-specific alignment; (2) Using the proposed image-text data, we first train a pathology language-image pretraining (PLIP) model as the specialized visual encoder for pathology image, and then we developed scale-invariant connector to avoid the information loss caused by image scaling; (3) We adopt two-stage learning to train PA-LLaVA, first stage for domain alignment, and second stage for end to end visual question \& answering (VQA) task. In experiments, we evaluate our PA-LLaVA on both supervised and zero-shot VQA datasets, our model achieved the best overall performance among multimodal models of similar scale. The ablation experiments also confirmed the effectiveness of our design. We posit that our PA-LLaVA model and the datasets presented in this work can promote research in field of computational pathology. All codes are available at: https://github.com/ddw2AIGROUP2CQUPT/PA-LLaVA}{https://github.com/ddw2AIGROUP2CQUPT/PA-LLaVA
ATraDiff: Accelerating Online Reinforcement Learning with Imaginary Trajectories
Jun 06, 2024
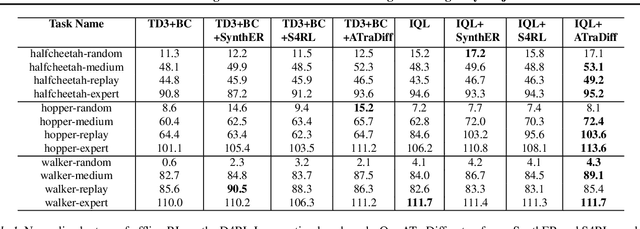
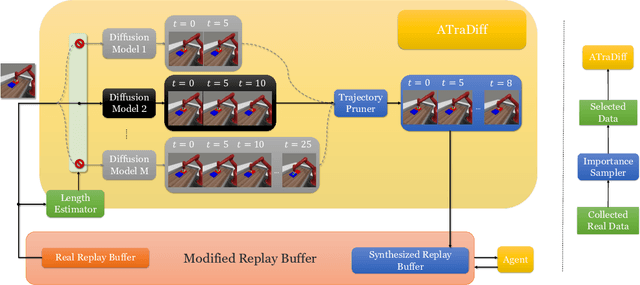

Training autonomous agents with sparse rewards is a long-standing problem in online reinforcement learning (RL), due to low data efficiency. Prior work overcomes this challenge by extracting useful knowledge from offline data, often accomplished through the learning of action distribution from offline data and utilizing the learned distribution to facilitate online RL. However, since the offline data are given and fixed, the extracted knowledge is inherently limited, making it difficult to generalize to new tasks. We propose a novel approach that leverages offline data to learn a generative diffusion model, coined as Adaptive Trajectory Diffuser (ATraDiff). This model generates synthetic trajectories, serving as a form of data augmentation and consequently enhancing the performance of online RL methods. The key strength of our diffuser lies in its adaptability, allowing it to effectively handle varying trajectory lengths and mitigate distribution shifts between online and offline data. Because of its simplicity, ATraDiff seamlessly integrates with a wide spectrum of RL methods. Empirical evaluation shows that ATraDiff consistently achieves state-of-the-art performance across a variety of environments, with particularly pronounced improvements in complicated settings. Our code and demo video are available at https://atradiff.github.io .
Non-Linear Coordination Graphs
Oct 26, 2022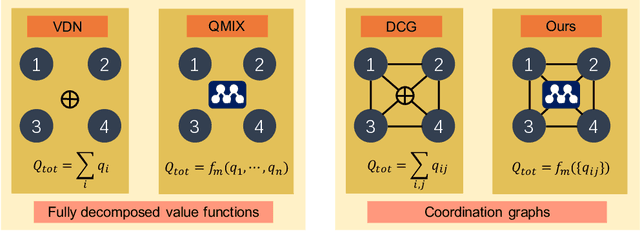

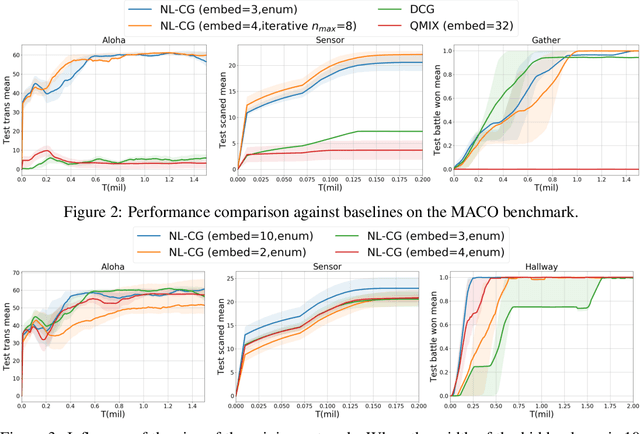
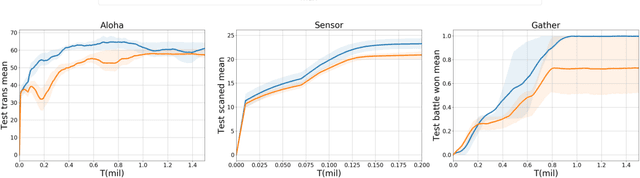
Value decomposition multi-agent reinforcement learning methods learn the global value function as a mixing of each agent's individual utility functions. Coordination graphs (CGs) represent a higher-order decomposition by incorporating pairwise payoff functions and thus is supposed to have a more powerful representational capacity. However, CGs decompose the global value function linearly over local value functions, severely limiting the complexity of the value function class that can be represented. In this paper, we propose the first non-linear coordination graph by extending CG value decomposition beyond the linear case. One major challenge is to conduct greedy action selections in this new function class to which commonly adopted DCOP algorithms are no longer applicable. We study how to solve this problem when mixing networks with LeakyReLU activation are used. An enumeration method with a global optimality guarantee is proposed and motivates an efficient iterative optimization method with a local optimality guarantee. We find that our method can achieve superior performance on challenging multi-agent coordination tasks like MACO.
* Authors are listed in alphabetical order
Self-Organized Polynomial-Time Coordination Graphs
Dec 07, 2021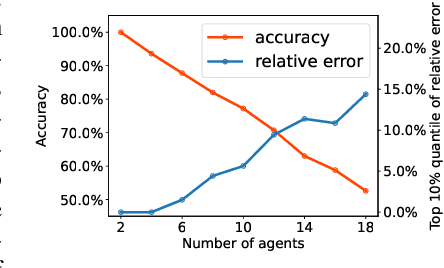
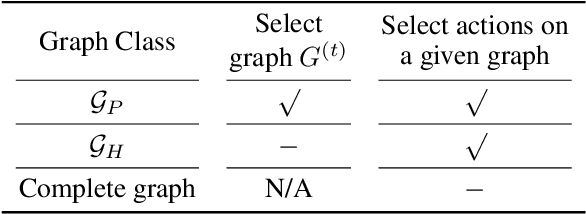
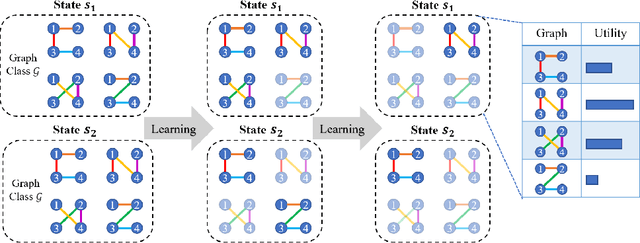

Coordination graph is a promising approach to model agent collaboration in multi-agent reinforcement learning. It factorizes a large multi-agent system into a suite of overlapping groups that represent the underlying coordination dependencies. One critical challenge in this paradigm is the complexity of computing maximum-value actions for a graph-based value factorization. It refers to the decentralized constraint optimization problem (DCOP), which and whose constant-ratio approximation are NP-hard problems. To bypass this fundamental hardness, this paper proposes a novel method, named Self-Organized Polynomial-time Coordination Graphs (SOP-CG), which uses structured graph classes to guarantee the optimality of the induced DCOPs with sufficient function expressiveness. We extend the graph topology to be state-dependent, formulate the graph selection as an imaginary agent, and finally derive an end-to-end learning paradigm from the unified Bellman optimality equation. In experiments, we show that our approach learns interpretable graph topologies, induces effective coordination, and improves performance across a variety of cooperative multi-agent tasks.
Context-Aware Sparse Deep Coordination Graphs
Jun 05, 2021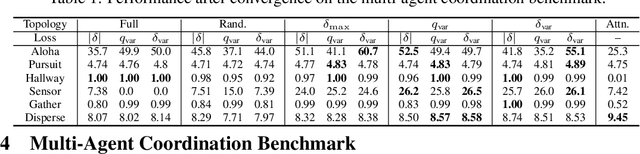
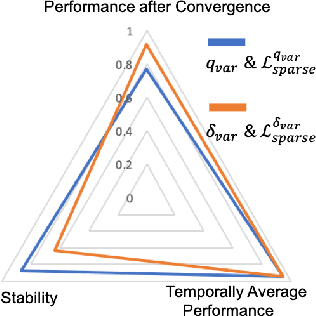
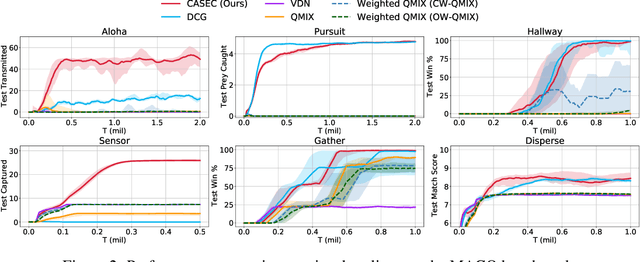
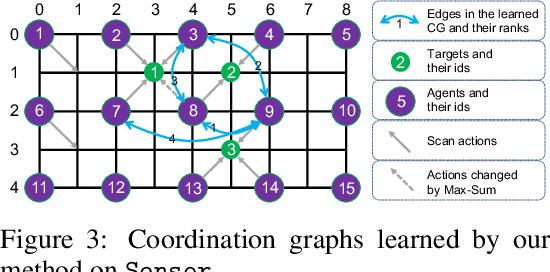
Learning sparse coordination graphs adaptive to the coordination dynamics among agents is a long-standing problem in cooperative multi-agent learning. This paper studies this problem by proposing several value-based and observation-based schemes for learning dynamic topologies and evaluating them on a new Multi-Agent COordination (MACO) benchmark. The benchmark collects classic coordination problems in the literature, increases their difficulty, and classifies them into different types. By analyzing the individual advantages of each learning scheme on each type of problem and their overall performance, we propose a novel method using the variance of utility difference functions to learn context-aware sparse coordination topologies. Moreover, our method learns action representations that effectively reduce the influence of utility functions' estimation errors on graph construction. Experiments show that our method significantly outperforms dense and static topologies across the MACO and StarCraft II micromanagement benchmark.