 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranslating Flow to Policy via Hindsight Online Imitation
Dec 22, 2025Recent advances in hierarchical robot systems leverage a high-level planner to propose task plans and a low-level policy to generate robot actions. This design allows training the planner on action-free or even non-robot data sources (e.g., videos), providing transferable high-level guidance. Nevertheless, grounding these high-level plans into executable actions remains challenging, especially with the limited availability of high-quality robot data. To this end, we propose to improve the low-level policy through online interactions. Specifically, our approach collects online rollouts, retrospectively annotates the corresponding high-level goals from achieved outcomes, and aggregates these hindsight-relabeled experiences to update a goal-conditioned imitation policy. Our method, Hindsight Flow-conditioned Online Imitation (HinFlow), instantiates this idea with 2D point flows as the high-level planner. Across diverse manipulation tasks in both simulation and physical world, our method achieves more than $2\times$ performance improvement over the base policy, significantly outperforming the existing methods. Moreover, our framework enables policy acquisition from planners trained on cross-embodiment video data, demonstrating its potential for scalable and transferable robot learning.
Imitation Learning from Observation with Automatic Discount Scheduling
Oct 12, 2023Humans often acquire new skills through observation and imitation. For robotic agents, learning from the plethora of unlabeled video demonstration data available on the Internet necessitates imitating the expert without access to its action, presenting a challenge known as Imitation Learning from Observations (ILfO). A common approach to tackle ILfO problems is to convert them into inverse reinforcement learning problems, utilizing a proxy reward computed from the agent's and the expert's observations. Nonetheless, we identify that tasks characterized by a progress dependency property pose significant challenges for such approaches; in these tasks, the agent needs to initially learn the expert's preceding behaviors before mastering the subsequent ones. Our investigation reveals that the main cause is that the reward signals assigned to later steps hinder the learning of initial behaviors. To address this challenge, we present a novel ILfO framework that enables the agent to master earlier behaviors before advancing to later ones. We introduce an Automatic Discount Scheduling (ADS) mechanism that adaptively alters the discount factor in reinforcement learning during the training phase, prioritizing earlier rewards initially and gradually engaging later rewards only when the earlier behaviors have been mastered. Our experiments, conducted on nine Meta-World tasks, demonstrate that our method significantly outperforms state-of-the-art methods across all tasks, including those that are unsolvable by them.
Self-Organized Polynomial-Time Coordination Graphs
Dec 07, 2021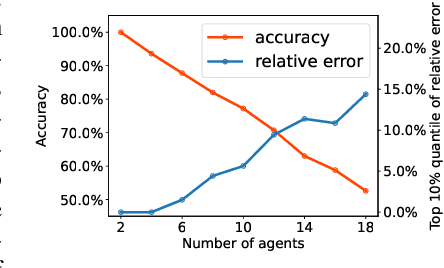
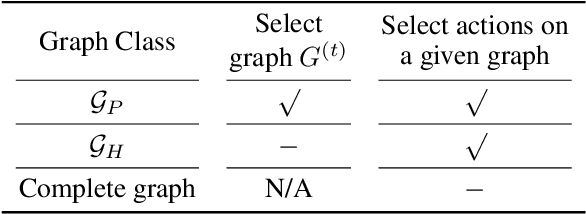
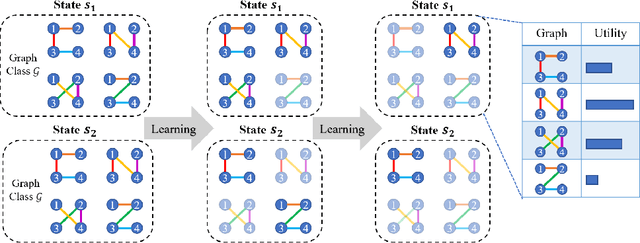

Coordination graph is a promising approach to model agent collaboration in multi-agent reinforcement learning. It factorizes a large multi-agent system into a suite of overlapping groups that represent the underlying coordination dependencies. One critical challenge in this paradigm is the complexity of computing maximum-value actions for a graph-based value factorization. It refers to the decentralized constraint optimization problem (DCOP), which and whose constant-ratio approximation are NP-hard problems. To bypass this fundamental hardness, this paper proposes a novel method, named Self-Organized Polynomial-time Coordination Graphs (SOP-CG), which uses structured graph classes to guarantee the optimality of the induced DCOPs with sufficient function expressiveness. We extend the graph topology to be state-dependent, formulate the graph selection as an imaginary agent, and finally derive an end-to-end learning paradigm from the unified Bellman optimality equation. In experiments, we show that our approach learns interpretable graph topologies, induces effective coordination, and improves performance across a variety of cooperative multi-agent tasks.
Context-Aware Sparse Deep Coordination Graphs
Jun 05, 2021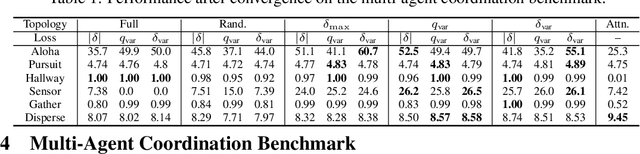
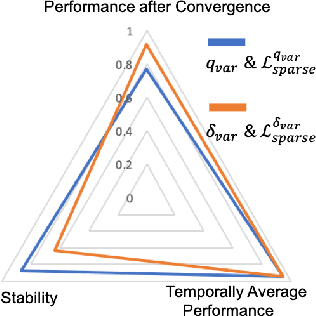
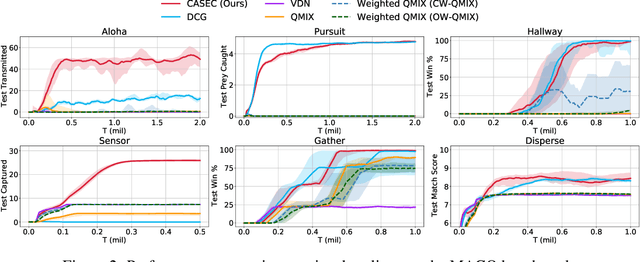
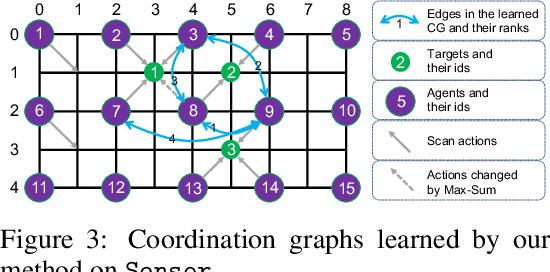
Learning sparse coordination graphs adaptive to the coordination dynamics among agents is a long-standing problem in cooperative multi-agent learning. This paper studies this problem by proposing several value-based and observation-based schemes for learning dynamic topologies and evaluating them on a new Multi-Agent COordination (MACO) benchmark. The benchmark collects classic coordination problems in the literature, increases their difficulty, and classifies them into different types. By analyzing the individual advantages of each learning scheme on each type of problem and their overall performance, we propose a novel method using the variance of utility difference functions to learn context-aware sparse coordination topologies. Moreover, our method learns action representations that effectively reduce the influence of utility functions' estimation errors on graph construction. Experiments show that our method significantly outperforms dense and static topologies across the MACO and StarCraft II micromanagement benchmark.