 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVTAM: Video-Tactile-Action Models for Complex Physical Interaction Beyond VLAs
Mar 24, 2026Video-Action Models (VAMs) have emerged as a promising framework for embodied intelligence, learning implicit world dynamics from raw video streams to produce temporally consistent action predictions. Although such models demonstrate strong performance on long-horizon tasks through visual reasoning, they remain limited in contact-rich scenarios where critical interaction states are only partially observable from vision alone. In particular, fine-grained force modulation and contact transitions are not reliably encoded in visual tokens, leading to unstable or imprecise behaviors. To bridge this gap, we introduce the Video-Tactile Action Model (VTAM), a multimodal world modeling framework that incorporates tactile perception as a complementary grounding signal. VTAM augments a pretrained video transformer with tactile streams via a lightweight modality transfer finetuning, enabling efficient cross-modal representation learning without tactile-language paired data or independent tactile pretraining. To stabilize multimodal fusion, we introduce a tactile regularization loss that enforces balanced cross-modal attention, preventing visual latent dominance in the action model. VTAM demonstrates superior performance in contact-rich manipulation, maintaining a robust success rate of 90 percent on average. In challenging scenarios such as potato chip pick-and-place requiring high-fidelity force awareness, VTAM outperforms the pi 0.5 baseline by 80 percent. Our findings demonstrate that integrating tactile feedback is essential for correcting visual estimation errors in world action models, providing a scalable approach to physically grounded embodied foundation models.
RoboPocket: Improve Robot Policies Instantly with Your Phone
Mar 05, 2026Scaling imitation learning is fundamentally constrained by the efficiency of data collection. While handheld interfaces have emerged as a scalable solution for in-the-wild data acquisition, they predominantly operate in an open-loop manner: operators blindly collect demonstrations without knowing the underlying policy's weaknesses, leading to inefficient coverage of critical state distributions. Conversely, interactive methods like DAgger effectively address covariate shift but rely on physical robot execution, which is costly and difficult to scale. To reconcile this trade-off, we introduce RoboPocket, a portable system that enables Robot-Free Instant Policy Iteration using single consumer smartphones. Its core innovation is a Remote Inference framework that visualizes the policy's predicted trajectory via Augmented Reality (AR) Visual Foresight. This immersive feedback allows collectors to proactively identify potential failures and focus data collection on the policy's weak regions without requiring a physical robot. Furthermore, we implement an asynchronous Online Finetuning pipeline that continuously updates the policy with incoming data, effectively closing the learning loop in minutes. Extensive experiments demonstrate that RoboPocket adheres to data scaling laws and doubles the data efficiency compared to offline scaling strategies, overcoming their long-standing efficiency bottleneck. Moreover, our instant iteration loop also boosts sample efficiency by up to 2$\times$ in distributed environments a small number of interactive corrections per person. Project page and videos: https://robo-pocket.github.io.
Rethinking Camera Choice: An Empirical Study on Fisheye Camera Properties in Robotic Manipulation
Mar 02, 2026The adoption of fisheye cameras in robotic manipulation, driven by their exceptionally wide Field of View (FoV), is rapidly outpacing a systematic understanding of their downstream effects on policy learning. This paper presents the first comprehensive empirical study to bridge this gap, rigorously analyzing the properties of wrist-mounted fisheye cameras for imitation learning. Through extensive experiments in both simulation and the real world, we investigate three critical research questions: spatial localization, scene generalization, and hardware generalization. Our investigation reveals that: (1) The wide FoV significantly enhances spatial localization, but this benefit is critically contingent on the visual complexity of the environment. (2) Fisheye-trained policies, while prone to overfitting in simple scenes, unlock superior scene generalization when trained with sufficient environmental diversity. (3) While naive cross-camera transfer leads to failures, we identify the root cause as scale overfitting and demonstrate that hardware generalization performance can be improved with a simple Random Scale Augmentation (RSA) strategy. Collectively, our findings provide concrete, actionable guidance for the large-scale collection and effective use of fisheye datasets in robotic learning. More results and videos are available on https://robo-fisheye.github.io/
Humanoid Manipulation Interface: Humanoid Whole-Body Manipulation from Robot-Free Demonstrations
Feb 06, 2026Current approaches for humanoid whole-body manipulation, primarily relying on teleoperation or visual sim-to-real reinforcement learning, are hindered by hardware logistics and complex reward engineering. Consequently, demonstrated autonomous skills remain limited and are typically restricted to controlled environments. In this paper, we present the Humanoid Manipulation Interface (HuMI), a portable and efficient framework for learning diverse whole-body manipulation tasks across various environments. HuMI enables robot-free data collection by capturing rich whole-body motion using portable hardware. This data drives a hierarchical learning pipeline that translates human motions into dexterous and feasible humanoid skills. Extensive experiments across five whole-body tasks--including kneeling, squatting, tossing, walking, and bimanual manipulation--demonstrate that HuMI achieves a 3x increase in data collection efficiency compared to teleoperation and attains a 70% success rate in unseen environments.
Kimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
EmboCoach-Bench: Benchmarking AI Agents on Developing Embodied Robots
Jan 29, 2026The field of Embodied AI is witnessing a rapid evolution toward general-purpose robotic systems, fueled by high-fidelity simulation and large-scale data collection. However, this scaling capability remains severely bottlenecked by a reliance on labor-intensive manual oversight from intricate reward shaping to hyperparameter tuning across heterogeneous backends. Inspired by LLMs' success in software automation and science discovery, we introduce \textsc{EmboCoach-Bench}, a benchmark evaluating the capacity of LLM agents to autonomously engineer embodied policies. Spanning 32 expert-curated RL and IL tasks, our framework posits executable code as the universal interface. We move beyond static generation to assess a dynamic closed-loop workflow, where agents leverage environment feedback to iteratively draft, debug, and optimize solutions, spanning improvements from physics-informed reward design to policy architectures such as diffusion policies. Extensive evaluations yield three critical insights: (1) autonomous agents can qualitatively surpass human-engineered baselines by 26.5\% in average success rate; (2) agentic workflow with environment feedback effectively strengthens policy development and substantially narrows the performance gap between open-source and proprietary models; and (3) agents exhibit self-correction capabilities for pathological engineering cases, successfully resurrecting task performance from near-total failures through iterative simulation-in-the-loop debugging. Ultimately, this work establishes a foundation for self-evolving embodied intelligence, accelerating the paradigm shift from labor-intensive manual tuning to scalable, autonomous engineering in embodied AI field.
Translating Flow to Policy via Hindsight Online Imitation
Dec 22, 2025Recent advances in hierarchical robot systems leverage a high-level planner to propose task plans and a low-level policy to generate robot actions. This design allows training the planner on action-free or even non-robot data sources (e.g., videos), providing transferable high-level guidance. Nevertheless, grounding these high-level plans into executable actions remains challenging, especially with the limited availability of high-quality robot data. To this end, we propose to improve the low-level policy through online interactions. Specifically, our approach collects online rollouts, retrospectively annotates the corresponding high-level goals from achieved outcomes, and aggregates these hindsight-relabeled experiences to update a goal-conditioned imitation policy. Our method, Hindsight Flow-conditioned Online Imitation (HinFlow), instantiates this idea with 2D point flows as the high-level planner. Across diverse manipulation tasks in both simulation and physical world, our method achieves more than $2\times$ performance improvement over the base policy, significantly outperforming the existing methods. Moreover, our framework enables policy acquisition from planners trained on cross-embodiment video data, demonstrating its potential for scalable and transferable robot learning.
ImplicitRDP: An End-to-End Visual-Force Diffusion Policy with Structural Slow-Fast Learning
Dec 11, 2025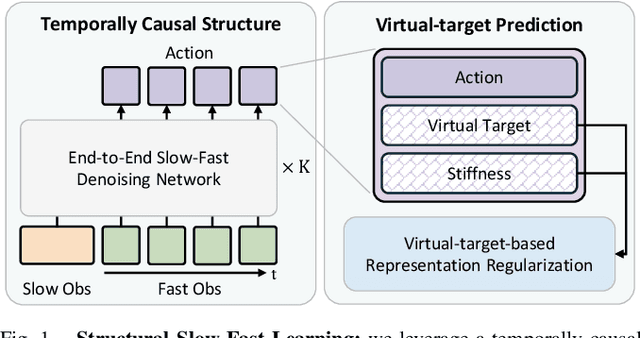
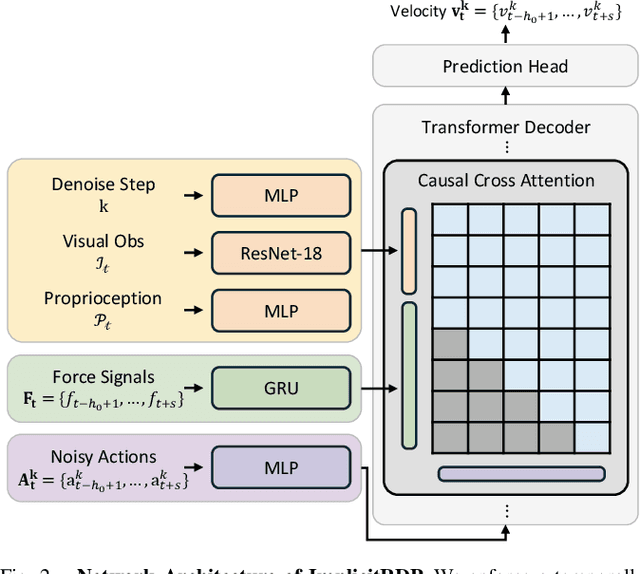


Human-level contact-rich manipulation relies on the distinct roles of two key modalities: vision provides spatially rich but temporally slow global context, while force sensing captures rapid, high-frequency local contact dynamics. Integrating these signals is challenging due to their fundamental frequency and informational disparities. In this work, we propose ImplicitRDP, a unified end-to-end visual-force diffusion policy that integrates visual planning and reactive force control within a single network. We introduce Structural Slow-Fast Learning, a mechanism utilizing causal attention to simultaneously process asynchronous visual and force tokens, allowing the policy to perform closed-loop adjustments at the force frequency while maintaining the temporal coherence of action chunks. Furthermore, to mitigate modality collapse where end-to-end models fail to adjust the weights across different modalities, we propose Virtual-target-based Representation Regularization. This auxiliary objective maps force feedback into the same space as the action, providing a stronger, physics-grounded learning signal than raw force prediction. Extensive experiments on contact-rich tasks demonstrate that ImplicitRDP significantly outperforms both vision-only and hierarchical baselines, achieving superior reactivity and success rates with a streamlined training pipeline. Code and videos will be publicly available at https://implicit-rdp.github.io.
ARMADA: Autonomous Online Failure Detection and Human Shared Control Empower Scalable Real-world Deployment and Adaptation
Oct 02, 2025Imitation learning has shown promise in learning from large-scale real-world datasets. However, pretrained policies usually perform poorly without sufficient in-domain data. Besides, human-collected demonstrations entail substantial labour and tend to encompass mixed-quality data and redundant information. As a workaround, human-in-the-loop systems gather domain-specific data for policy post-training, and exploit closed-loop policy feedback to offer informative guidance, but usually require full-time human surveillance during policy rollout. In this work, we devise ARMADA, a multi-robot deployment and adaptation system with human-in-the-loop shared control, featuring an autonomous online failure detection method named FLOAT. Thanks to FLOAT, ARMADA enables paralleled policy rollout and requests human intervention only when necessary, significantly reducing reliance on human supervision. Hence, ARMADA enables efficient acquisition of in-domain data, and leads to more scalable deployment and faster adaptation to new scenarios. We evaluate the performance of ARMADA on four real-world tasks. FLOAT achieves nearly 95% accuracy on average, surpassing prior state-of-the-art failure detection approaches by over 20%. Besides, ARMADA manifests more than 4$\times$ increase in success rate and greater than 2$\times$ reduction in human intervention rate over multiple rounds of policy rollout and post-training, compared to previous human-in-the-loop learning methods.
TimeRewarder: Learning Dense Reward from Passive Videos via Frame-wise Temporal Distance
Sep 30, 2025Designing dense rewards is crucial for reinforcement learning (RL), yet in robotics it often demands extensive manual effort and lacks scalability. One promising solution is to view task progress as a dense reward signal, as it quantifies the degree to which actions advance the system toward task completion over time. We present TimeRewarder, a simple yet effective reward learning method that derives progress estimation signals from passive videos, including robot demonstrations and human videos, by modeling temporal distances between frame pairs. We then demonstrate how TimeRewarder can supply step-wise proxy rewards to guide reinforcement learning. In our comprehensive experiments on ten challenging Meta-World tasks, we show that TimeRewarder dramatically improves RL for sparse-reward tasks, achieving nearly perfect success in 9/10 tasks with only 200,000 interactions per task with the environment. This approach outperformed previous methods and even the manually designed environment dense reward on both the final success rate and sample efficiency. Moreover, we show that TimeRewarder pretraining can exploit real-world human videos, highlighting its potential as a scalable approach path to rich reward signals from diverse video sources.