 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Peel with a Knife: Aligning Fine-Grained Manipulation with Human Preference
Mar 03, 2026Many essential manipulation tasks - such as food preparation, surgery, and craftsmanship - remain intractable for autonomous robots. These tasks are characterized not only by contact-rich, force-sensitive dynamics, but also by their "implicit" success criteria: unlike pick-and-place, task quality in these domains is continuous and subjective (e.g. how well a potato is peeled), making quantitative evaluation and reward engineering difficult. We present a learning framework for such tasks, using peeling with a knife as a representative example. Our approach follows a two-stage pipeline: first, we learn a robust initial policy via force-aware data collection and imitation learning, enabling generalization across object variations; second, we refine the policy through preference-based finetuning using a learned reward model that combines quantitative task metrics with qualitative human feedback, aligning policy behavior with human notions of task quality. Using only 50-200 peeling trajectories, our system achieves over 90% average success rates on challenging produce including cucumbers, apples, and potatoes, with performance improving by up to 40% through preference-based finetuning. Remarkably, policies trained on a single produce category exhibit strong zero-shot generalization to unseen in-category instances and to out-of-distribution produce from different categories while maintaining over 90% success rates.
Lightning Grasp: High Performance Procedural Grasp Synthesis with Contact Fields
Nov 10, 2025Despite years of research, real-time diverse grasp synthesis for dexterous hands remains an unsolved core challenge in robotics and computer graphics. We present Lightning Grasp, a novel high-performance procedural grasp synthesis algorithm that achieves orders-of-magnitude speedups over state-of-the-art approaches, while enabling unsupervised grasp generation for irregular, tool-like objects. The method avoids many limitations of prior approaches, such as the need for carefully tuned energy functions and sensitive initialization. This breakthrough is driven by a key insight: decoupling complex geometric computation from the search process via a simple, efficient data structure - the Contact Field. This abstraction collapses the problem complexity, enabling a procedural search at unprecedented speeds. We open-source our system to propel further innovation in robotic manipulation.
Object-centric 3D Motion Field for Robot Learning from Human Videos
Jun 04, 2025Learning robot control policies from human videos is a promising direction for scaling up robot learning. However, how to extract action knowledge (or action representations) from videos for policy learning remains a key challenge. Existing action representations such as video frames, pixelflow, and pointcloud flow have inherent limitations such as modeling complexity or loss of information. In this paper, we propose to use object-centric 3D motion field to represent actions for robot learning from human videos, and present a novel framework for extracting this representation from videos for zero-shot control. We introduce two novel components in its implementation. First, a novel training pipeline for training a ''denoising'' 3D motion field estimator to extract fine object 3D motions from human videos with noisy depth robustly. Second, a dense object-centric 3D motion field prediction architecture that favors both cross-embodiment transfer and policy generalization to background. We evaluate the system in real world setups. Experiments show that our method reduces 3D motion estimation error by over 50% compared to the latest method, achieve 55% average success rate in diverse tasks where prior approaches fail~($\lesssim 10$\%), and can even acquire fine-grained manipulation skills like insertion.
FastTD3: Simple, Fast, and Capable Reinforcement Learning for Humanoid Control
May 29, 2025Reinforcement learning (RL) has driven significant progress in robotics, but its complexity and long training times remain major bottlenecks. In this report, we introduce FastTD3, a simple, fast, and capable RL algorithm that significantly speeds up training for humanoid robots in popular suites such as HumanoidBench, IsaacLab, and MuJoCo Playground. Our recipe is remarkably simple: we train an off-policy TD3 agent with several modifications -- parallel simulation, large-batch updates, a distributional critic, and carefully tuned hyperparameters. FastTD3 solves a range of HumanoidBench tasks in under 3 hours on a single A100 GPU, while remaining stable during training. We also provide a lightweight and easy-to-use implementation of FastTD3 to accelerate RL research in robotics.
Geometric Retargeting: A Principled, Ultrafast Neural Hand Retargeting Algorithm
Mar 10, 2025We introduce Geometric Retargeting (GeoRT), an ultrafast, and principled neural hand retargeting algorithm for teleoperation, developed as part of our recent Dexterity Gen (DexGen) system. GeoRT converts human finger keypoints to robot hand keypoints at 1KHz, achieving state-of-the-art speed and accuracy with significantly fewer hyperparameters. This high-speed capability enables flexible postprocessing, such as leveraging a foundational controller for action correction like DexGen. GeoRT is trained in an unsupervised manner, eliminating the need for manual annotation of hand pairs. The core of GeoRT lies in novel geometric objective functions that capture the essence of retargeting: preserving motion fidelity, ensuring configuration space (C-space) coverage, maintaining uniform response through high flatness, pinch correspondence and preventing self-collisions. This approach is free from intensive test-time optimization, offering a more scalable and practical solution for real-time hand retargeting.
DexterityGen: Foundation Controller for Unprecedented Dexterity
Feb 06, 2025



Teaching robots dexterous manipulation skills, such as tool use, presents a significant challenge. Current approaches can be broadly categorized into two strategies: human teleoperation (for imitation learning) and sim-to-real reinforcement learning. The first approach is difficult as it is hard for humans to produce safe and dexterous motions on a different embodiment without touch feedback. The second RL-based approach struggles with the domain gap and involves highly task-specific reward engineering on complex tasks. Our key insight is that RL is effective at learning low-level motion primitives, while humans excel at providing coarse motion commands for complex, long-horizon tasks. Therefore, the optimal solution might be a combination of both approaches. In this paper, we introduce DexterityGen (DexGen), which uses RL to pretrain large-scale dexterous motion primitives, such as in-hand rotation or translation. We then leverage this learned dataset to train a dexterous foundational controller. In the real world, we use human teleoperation as a prompt to the controller to produce highly dexterous behavior. We evaluate the effectiveness of DexGen in both simulation and real world, demonstrating that it is a general-purpose controller that can realize input dexterous manipulation commands and significantly improves stability by 10-100x measured as duration of holding objects across diverse tasks. Notably, with DexGen we demonstrate unprecedented dexterous skills including diverse object reorientation and dexterous tool use such as pen, syringe, and screwdriver for the first time.
Offline Imitation Learning Through Graph Search and Retrieval
Jul 22, 2024



Imitation learning is a powerful machine learning algorithm for a robot to acquire manipulation skills. Nevertheless, many real-world manipulation tasks involve precise and dexterous robot-object interactions, which make it difficult for humans to collect high-quality expert demonstrations. As a result, a robot has to learn skills from suboptimal demonstrations and unstructured interactions, which remains a key challenge. Existing works typically use offline deep reinforcement learning (RL) to solve this challenge, but in practice these algorithms are unstable and fragile due to the deadly triad issue. To overcome this problem, we propose GSR, a simple yet effective algorithm that learns from suboptimal demonstrations through Graph Search and Retrieval. We first use pretrained representation to organize the interaction experience into a graph and perform a graph search to calculate the values of different behaviors. Then, we apply a retrieval-based procedure to identify the best behavior (actions) on each state and use behavior cloning to learn that behavior. We evaluate our method in both simulation and real-world robotic manipulation tasks with complex visual inputs, covering various precise and dexterous manipulation skills with objects of different physical properties. GSR can achieve a 10% to 30% higher success rate and over 30% higher proficiency compared to baselines. Our project page is at https://zhaohengyin.github.io/gsr.
Learning Manipulation Skills through Robot Chain-of-Thought with Sparse Failure Guidance
May 22, 2024



The acquisition of manipulation skills through language instruction remains an unresolved challenge. Recently, vision-language models have made significant progress in teaching robots these skills. However, their performance is restricted to a narrow range of simple tasks. In this paper, we propose that vision-language models can provide a superior source of rewards for agents. Our method decomposes complex tasks into simpler sub-goals, enabling better task comprehension and avoiding potential failures with sparse failure guidance. Empirical evidence demonstrates that our algorithm consistently outperforms baselines such as CLIP, LIV, and RoboCLIP. Specifically, our algorithm achieves a $5.4\times$ higher average success rate compared to the best baseline, RoboCLIP, across a series of manipulation tasks. It has shown a comprehensive understanding of a wide range of robotic manipulation tasks.
Twisting Lids Off with Two Hands
Mar 04, 2024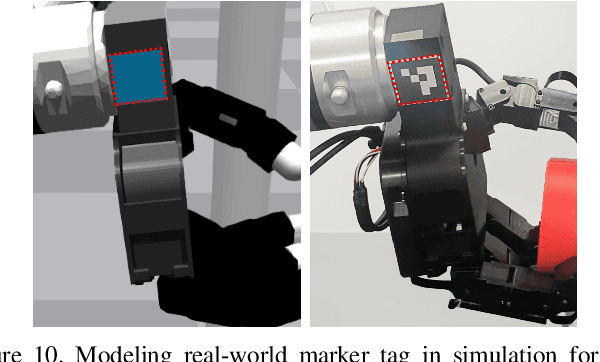

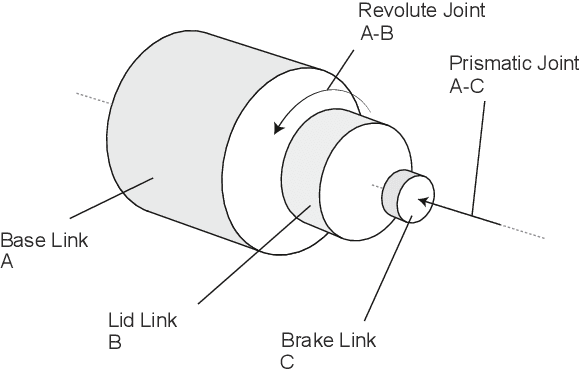

Manipulating objects with two multi-fingered hands has been a long-standing challenge in robotics, attributed to the contact-rich nature of many manipulation tasks and the complexity inherent in coordinating a high-dimensional bimanual system. In this work, we consider the problem of twisting lids of various bottle-like objects with two hands, and demonstrate that policies trained in simulation using deep reinforcement learning can be effectively transferred to the real world. With novel engineering insights into physical modeling, real-time perception, and reward design, the policy demonstrates generalization capabilities across a diverse set of unseen objects, showcasing dynamic and dexterous behaviors. Our findings serve as compelling evidence that deep reinforcement learning combined with sim-to-real transfer remains a promising approach for addressing manipulation problems of unprecedented complexity.
Robot Synesthesia: In-Hand Manipulation with Visuotactile Sensing
Dec 04, 2023



Executing contact-rich manipulation tasks necessitates the fusion of tactile and visual feedback. However, the distinct nature of these modalities poses significant challenges. In this paper, we introduce a system that leverages visual and tactile sensory inputs to enable dexterous in-hand manipulation. Specifically, we propose Robot Synesthesia, a novel point cloud-based tactile representation inspired by human tactile-visual synesthesia. This approach allows for the simultaneous and seamless integration of both sensory inputs, offering richer spatial information and facilitating better reasoning about robot actions. The method, trained in a simulated environment and then deployed to a real robot, is applicable to various in-hand object rotation tasks. Comprehensive ablations are performed on how the integration of vision and touch can improve reinforcement learning and Sim2Real performance. Our project page is available at https://yingyuan0414.github.io/visuotactile/ .