 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient and Reliable Teleoperation through Real-to-Sim-to-Real Shared Autonomy
Mar 17, 2026Fine-grained, contact-rich teleoperation remains slow, error-prone, and unreliable in real-world manipulation tasks, even for experienced operators. Shared autonomy offers a promising way to improve performance by combining human intent with automated assistance, but learning effective assistance in simulation requires a faithful model of human behavior, which is difficult to obtain in practice. We propose a real-to-sim-to-real shared autonomy framework that augments human teleoperation with learned corrective behaviors, using a simple yet effective k-nearest-neighbor (kNN) human surrogate to model operator actions in simulation. The surrogate is fit from less than five minutes of real-world teleoperation data and enables stable training of a residual copilot policy with model-free reinforcement learning. The resulting copilot is deployed to assist human operators in real-world fine-grained manipulation tasks. Through simulation experiments and a user study with sixteen participants on industry-relevant tasks, including nut threading, gear meshing, and peg insertion, we show that our system improves task success for novice operators and execution efficiency for experienced operators compared to direct teleoperation and shared-autonomy baselines that rely on expert priors or behavioral-cloning pilots. In addition, copilot-assisted teleoperation produces higher-quality demonstrations for downstream imitation learning.
Learning Force-Regulated Manipulation with a Low-Cost Tactile-Force-Controlled Gripper
Feb 10, 2026Successfully manipulating many everyday objects, such as potato chips, requires precise force regulation. Failure to modulate force can lead to task failure or irreversible damage to the objects. Humans can precisely achieve this by adapting force from tactile feedback, even within a short period of physical contact. We aim to give robots this capability. However, commercial grippers exhibit high cost or high minimum force, making them unsuitable for studying force-controlled policy learning with everyday force-sensitive objects. We introduce TF-Gripper, a low-cost (~$150) force-controlled parallel-jaw gripper that integrates tactile sensing as feedback. It has an effective force range of 0.45-45N and is compatible with different robot arms. Additionally, we designed a teleoperation device paired with TF-Gripper to record human-applied grasping forces. While standard low-frequency policies can be trained on this data, they struggle with the reactive, contact-dependent nature of force regulation. To overcome this, we propose RETAF (REactive Tactile Adaptation of Force), a framework that decouples grasping force control from arm pose prediction. RETAF regulates force at high frequency using wrist images and tactile feedback, while a base policy predicts end-effector pose and gripper open/close action. We evaluate TF-Gripper and RETAF across five real-world tasks requiring precise force regulation. Results show that compared to position control, direct force control significantly improves grasp stability and task performance. We further show that tactile feedback is essential for force regulation, and that RETAF consistently outperforms baselines and can be integrated with various base policies. We hope this work opens a path for scaling the learning of force-controlled policies in robotic manipulation. Project page: https://force-gripper.github.io .
3D-ViTac: Learning Fine-Grained Manipulation with Visuo-Tactile Sensing
Oct 31, 2024

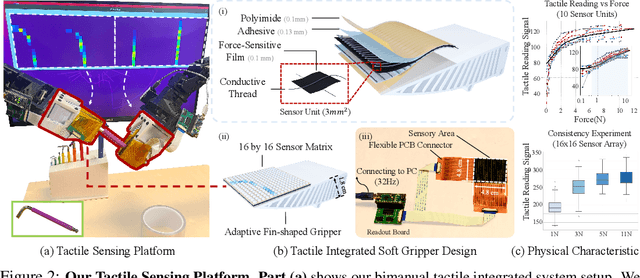

Tactile and visual perception are both crucial for humans to perform fine-grained interactions with their environment. Developing similar multi-modal sensing capabilities for robots can significantly enhance and expand their manipulation skills. This paper introduces \textbf{3D-ViTac}, a multi-modal sensing and learning system designed for dexterous bimanual manipulation. Our system features tactile sensors equipped with dense sensing units, each covering an area of 3$mm^2$. These sensors are low-cost and flexible, providing detailed and extensive coverage of physical contacts, effectively complementing visual information. To integrate tactile and visual data, we fuse them into a unified 3D representation space that preserves their 3D structures and spatial relationships. The multi-modal representation can then be coupled with diffusion policies for imitation learning. Through concrete hardware experiments, we demonstrate that even low-cost robots can perform precise manipulations and significantly outperform vision-only policies, particularly in safe interactions with fragile items and executing long-horizon tasks involving in-hand manipulation. Our project page is available at \url{https://binghao-huang.github.io/3D-ViTac/}.
GenDP: 3D Semantic Fields for Category-Level Generalizable Diffusion Policy
Oct 23, 2024



Diffusion-based policies have shown remarkable capability in executing complex robotic manipulation tasks but lack explicit characterization of geometry and semantics, which often limits their ability to generalize to unseen objects and layouts. To enhance the generalization capabilities of Diffusion Policy, we introduce a novel framework that incorporates explicit spatial and semantic information via 3D semantic fields. We generate 3D descriptor fields from multi-view RGBD observations with large foundational vision models, then compare these descriptor fields against reference descriptors to obtain semantic fields. The proposed method explicitly considers geometry and semantics, enabling strong generalization capabilities in tasks requiring category-level generalization, resolving geometric ambiguities, and attention to subtle geometric details. We evaluate our method across eight tasks involving articulated objects and instances with varying shapes and textures from multiple object categories. Our method demonstrates its effectiveness by increasing Diffusion Policy's average success rate on unseen instances from 20% to 93%. Additionally, we provide a detailed analysis and visualization to interpret the sources of performance gain and explain how our method can generalize to novel instances.
Sim2Real Manipulation on Unknown Objects with Tactile-based Reinforcement Learning
Mar 18, 2024Using tactile sensors for manipulation remains one of the most challenging problems in robotics. At the heart of these challenges is generalization: How can we train a tactile-based policy that can manipulate unseen and diverse objects? In this paper, we propose to perform Reinforcement Learning with only visual tactile sensing inputs on diverse objects in a physical simulator. By training with diverse objects in simulation, it enables the policy to generalize to unseen objects. However, leveraging simulation introduces the Sim2Real transfer problem. To mitigate this problem, we study different tactile representations and evaluate how each affects real-robot manipulation results after transfer. We conduct our experiments on diverse real-world objects and show significant improvements over baselines for the pivoting task. Our project page is available at https://tactilerl.github.io/.
RoboEXP: Action-Conditioned Scene Graph via Interactive Exploration for Robotic Manipulation
Feb 23, 2024



Robots need to explore their surroundings to adapt to and tackle tasks in unknown environments. Prior work has proposed building scene graphs of the environment but typically assumes that the environment is static, omitting regions that require active interactions. This severely limits their ability to handle more complex tasks in household and office environments: before setting up a table, robots must explore drawers and cabinets to locate all utensils and condiments. In this work, we introduce the novel task of interactive scene exploration, wherein robots autonomously explore environments and produce an action-conditioned scene graph (ACSG) that captures the structure of the underlying environment. The ACSG accounts for both low-level information, such as geometry and semantics, and high-level information, such as the action-conditioned relationships between different entities in the scene. To this end, we present the Robotic Exploration (RoboEXP) system, which incorporates the Large Multimodal Model (LMM) and an explicit memory design to enhance our system's capabilities. The robot reasons about what and how to explore an object, accumulating new information through the interaction process and incrementally constructing the ACSG. We apply our system across various real-world settings in a zero-shot manner, demonstrating its effectiveness in exploring and modeling environments it has never seen before. Leveraging the constructed ACSG, we illustrate the effectiveness and efficiency of our RoboEXP system in facilitating a wide range of real-world manipulation tasks involving rigid, articulated objects, nested objects like Matryoshka dolls, and deformable objects like cloth.
Robot Synesthesia: In-Hand Manipulation with Visuotactile Sensing
Dec 04, 2023



Executing contact-rich manipulation tasks necessitates the fusion of tactile and visual feedback. However, the distinct nature of these modalities poses significant challenges. In this paper, we introduce a system that leverages visual and tactile sensory inputs to enable dexterous in-hand manipulation. Specifically, we propose Robot Synesthesia, a novel point cloud-based tactile representation inspired by human tactile-visual synesthesia. This approach allows for the simultaneous and seamless integration of both sensory inputs, offering richer spatial information and facilitating better reasoning about robot actions. The method, trained in a simulated environment and then deployed to a real robot, is applicable to various in-hand object rotation tasks. Comprehensive ablations are performed on how the integration of vision and touch can improve reinforcement learning and Sim2Real performance. Our project page is available at https://yingyuan0414.github.io/visuotactile/ .
Dynamic Handover: Throw and Catch with Bimanual Hands
Sep 11, 2023Humans throw and catch objects all the time. However, such a seemingly common skill introduces a lot of challenges for robots to achieve: The robots need to operate such dynamic actions at high-speed, collaborate precisely, and interact with diverse objects. In this paper, we design a system with two multi-finger hands attached to robot arms to solve this problem. We train our system using Multi-Agent Reinforcement Learning in simulation and perform Sim2Real transfer to deploy on the real robots. To overcome the Sim2Real gap, we provide multiple novel algorithm designs including learning a trajectory prediction model for the object. Such a model can help the robot catcher has a real-time estimation of where the object will be heading, and then react accordingly. We conduct our experiments with multiple objects in the real-world system, and show significant improvements over multiple baselines. Our project page is available at \url{https://binghao-huang.github.io/dynamic_handover/}.
AnyTeleop: A General Vision-Based Dexterous Robot Arm-Hand Teleoperation System
Aug 02, 2023



Vision-based teleoperation offers the possibility to endow robots with human-level intelligence to physically interact with the environment, while only requiring low-cost camera sensors. However, current vision-based teleoperation systems are designed and engineered towards a particular robot model and deploy environment, which scales poorly as the pool of the robot models expands and the variety of the operating environment increases. In this paper, we propose AnyTeleop, a unified and general teleoperation system to support multiple different arms, hands, realities, and camera configurations within a single system. Although being designed to provide great flexibility to the choice of simulators and real hardware, our system can still achieve great performance. For real-world experiments, AnyTeleop can outperform a previous system that was designed for a specific robot hardware with a higher success rate, using the same robot. For teleoperation in simulation, AnyTeleop leads to better imitation learning performance, compared with a previous system that is particularly designed for that simulator. Project page: http://anyteleop.com/.
Rotating without Seeing: Towards In-hand Dexterity through Touch
Mar 27, 2023Tactile information plays a critical role in human dexterity. It reveals useful contact information that may not be inferred directly from vision. In fact, humans can even perform in-hand dexterous manipulation without using vision. Can we enable the same ability for the multi-finger robot hand? In this paper, we present Touch Dexterity, a new system that can perform in-hand object rotation using only touching without seeing the object. Instead of relying on precise tactile sensing in a small region, we introduce a new system design using dense binary force sensors (touch or no touch) overlaying one side of the whole robot hand (palm, finger links, fingertips). Such a design is low-cost, giving a larger coverage of the object, and minimizing the Sim2Real gap at the same time. We train an in-hand rotation policy using Reinforcement Learning on diverse objects in simulation. Relying on touch-only sensing, we can directly deploy the policy in a real robot hand and rotate novel objects that are not presented in training. Extensive ablations are performed on how tactile information help in-hand manipulation.Our project is available at https://touchdexterity.github.io.