 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Assisted Stance Detection in Scientific Discourse: A Test Case in Bayesian Cognitive Science
Jun 14, 2026Qualitative coding is central to social science, but expert annotation is difficult to scale. LLMs offer a possible extension, yet require careful validation when the target construct is interpretive, theoretically loaded, and only indirectly expressed. We study this problem in a difficult case: detecting whether authors treat Bayesian models as descriptions of mental and neural mechanisms (realism) or as useful mathematical tools (instrumentalism). Our method combines a theory-driven codebook, expert-coded reference annotations, a diagnostic-gated prompt-optimization search yielding a shared zero-shot prompt for three frontier LLMs (GPT-5.1, Claude Sonnet 4.6, Gemini 3 Pro Preview), and multi-rater reliability analysis. The final prompt achieved a held-out combined reliability score of 0.76 (harmonic mean of ICC = 0.79 and $α$ = 0.74), with all diagnostics satisfied. Deployed on 6,858 quotes from 210 articles, the three LLMs reached substantial quote-level agreement (ICC = 0.80; $α$ = 0.76; combined = 0.78) and near-perfect article-level rank stability ($r$ = 0.96-0.97 across rater pairs). The corpus was predominantly weakly realist, but article-level stances were rarely uniform: only 1.4% of articles used a single band, while 59.5% spanned four or more. Low-level perception/motor articles scored 8.8 Realism points higher than high-level cognition articles ($p < .001$, $d = 0.60$), quantifying a long-held qualitative intuition. We present this as an expert-led case study; the framework is intended to generalize to similar theoretically demanding tasks, not to all qualitative analysis.
Expanding Spatial and Temporal Context for Robotic Imitation Learning With Scene Graphs
May 31, 2026Imitation learning enables robots to learn how to execute tasks via observation. However, real-world environments like homes and offices are often severely partially observed due to their large spatial scales. In addition, many tasks involve executing a series of subtasks requiring autonomous robots to reason over extended time horizons. To address these challenges, we propose using scene graphs as an explicit and structured memory mechanism in imitation learning. By maintaining a dynamic scene graph that captures object-centric relationships and their evolution over time, our method allows the agent to retain relevant historical context during task execution to efficiently reason over incrementally accrued scene information. Our experiments on simulated mobile manipulation and real-world tabletop manipulation demonstrate that our approach substantially improves policy performance, particularly in settings that demand long-term reasoning and robust generalization under partial observability.
Physics-Driven Data Generation for Contact-Rich Manipulation via Trajectory Optimization
Feb 27, 2025



We present a low-cost data generation pipeline that integrates physics-based simulation, human demonstrations, and model-based planning to efficiently generate large-scale, high-quality datasets for contact-rich robotic manipulation tasks. Starting with a small number of embodiment-flexible human demonstrations collected in a virtual reality simulation environment, the pipeline refines these demonstrations using optimization-based kinematic retargeting and trajectory optimization to adapt them across various robot embodiments and physical parameters. This process yields a diverse, physically consistent dataset that enables cross-embodiment data transfer, and offers the potential to reuse legacy datasets collected under different hardware configurations or physical parameters. We validate the pipeline's effectiveness by training diffusion policies from the generated datasets for challenging contact-rich manipulation tasks across multiple robot embodiments, including a floating Allegro hand and bimanual robot arms. The trained policies are deployed zero-shot on hardware for bimanual iiwa arms, achieving high success rates with minimal human input. Project website: https://lujieyang.github.io/physicsgen/.
On-Robot Reinforcement Learning with Goal-Contrastive Rewards
Oct 25, 2024Reinforcement Learning (RL) has the potential to enable robots to learn from their own actions in the real world. Unfortunately, RL can be prohibitively expensive, in terms of on-robot runtime, due to inefficient exploration when learning from a sparse reward signal. Designing dense reward functions is labour-intensive and requires domain expertise. In our work, we propose GCR (Goal-Contrastive Rewards), a dense reward function learning method that can be trained on passive video demonstrations. By using videos without actions, our method is easier to scale, as we can use arbitrary videos. GCR combines two loss functions, an implicit value loss function that models how the reward increases when traversing a successful trajectory, and a goal-contrastive loss that discriminates between successful and failed trajectories. We perform experiments in simulated manipulation environments across RoboMimic and MimicGen tasks, as well as in the real world using a Franka arm and a Spot quadruped. We find that GCR leads to a more-sample efficient RL, enabling model-free RL to solve about twice as many tasks as our baseline reward learning methods. We also demonstrate positive cross-embodiment transfer from videos of people and of other robots performing a task. Appendix: \url{https://tinyurl.com/gcr-appendix-2}.
GenDP: 3D Semantic Fields for Category-Level Generalizable Diffusion Policy
Oct 23, 2024



Diffusion-based policies have shown remarkable capability in executing complex robotic manipulation tasks but lack explicit characterization of geometry and semantics, which often limits their ability to generalize to unseen objects and layouts. To enhance the generalization capabilities of Diffusion Policy, we introduce a novel framework that incorporates explicit spatial and semantic information via 3D semantic fields. We generate 3D descriptor fields from multi-view RGBD observations with large foundational vision models, then compare these descriptor fields against reference descriptors to obtain semantic fields. The proposed method explicitly considers geometry and semantics, enabling strong generalization capabilities in tasks requiring category-level generalization, resolving geometric ambiguities, and attention to subtle geometric details. We evaluate our method across eight tasks involving articulated objects and instances with varying shapes and textures from multiple object categories. Our method demonstrates its effectiveness by increasing Diffusion Policy's average success rate on unseen instances from 20% to 93%. Additionally, we provide a detailed analysis and visualization to interpret the sources of performance gain and explain how our method can generalize to novel instances.
Theia: Distilling Diverse Vision Foundation Models for Robot Learning
Jul 29, 2024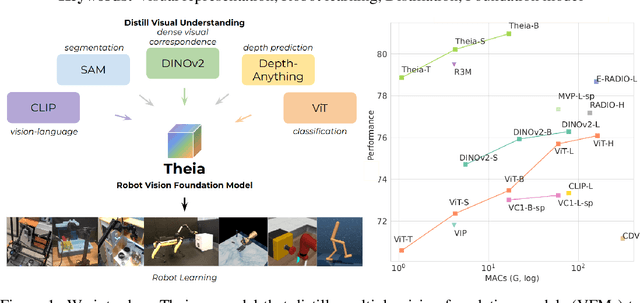



Vision-based robot policy learning, which maps visual inputs to actions, necessitates a holistic understanding of diverse visual tasks beyond single-task needs like classification or segmentation. Inspired by this, we introduce Theia, a vision foundation model for robot learning that distills multiple off-the-shelf vision foundation models trained on varied vision tasks. Theia's rich visual representations encode diverse visual knowledge, enhancing downstream robot learning. Extensive experiments demonstrate that Theia outperforms its teacher models and prior robot learning models using less training data and smaller model sizes. Additionally, we quantify the quality of pre-trained visual representations and hypothesize that higher entropy in feature norm distributions leads to improved robot learning performance. Code and models are available at https://github.com/bdaiinstitute/theia.
Equivariant Diffusion Policy
Jul 01, 2024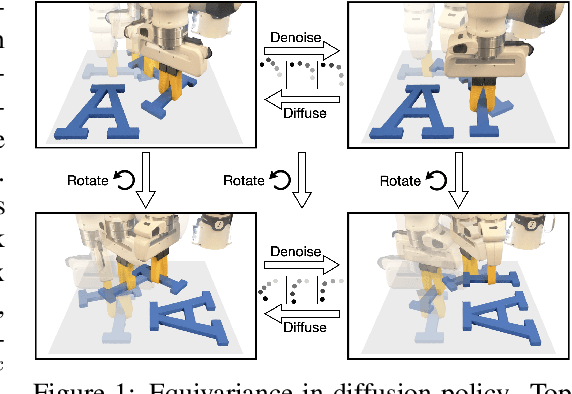



Recent work has shown diffusion models are an effective approach to learning the multimodal distributions arising from demonstration data in behavior cloning. However, a drawback of this approach is the need to learn a denoising function, which is significantly more complex than learning an explicit policy. In this work, we propose Equivariant Diffusion Policy, a novel diffusion policy learning method that leverages domain symmetries to obtain better sample efficiency and generalization in the denoising function. We theoretically analyze the $\mathrm{SO}(2)$ symmetry of full 6-DoF control and characterize when a diffusion model is $\mathrm{SO}(2)$-equivariant. We furthermore evaluate the method empirically on a set of 12 simulation tasks in MimicGen, and show that it obtains a success rate that is, on average, 21.9% higher than the baseline Diffusion Policy. We also evaluate the method on a real-world system to show that effective policies can be learned with relatively few training samples, whereas the baseline Diffusion Policy cannot.
Pregrasp Object Material Classification by a Novel Gripper Design with Integrated Spectroscopy
Jul 03, 2022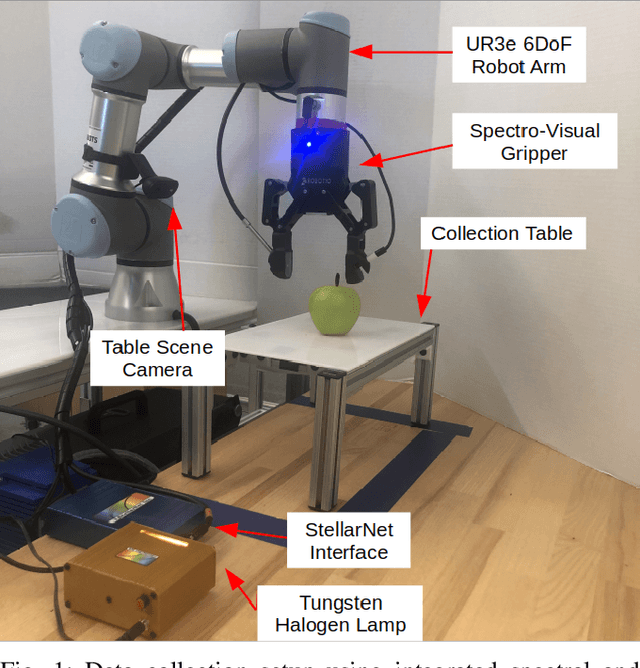
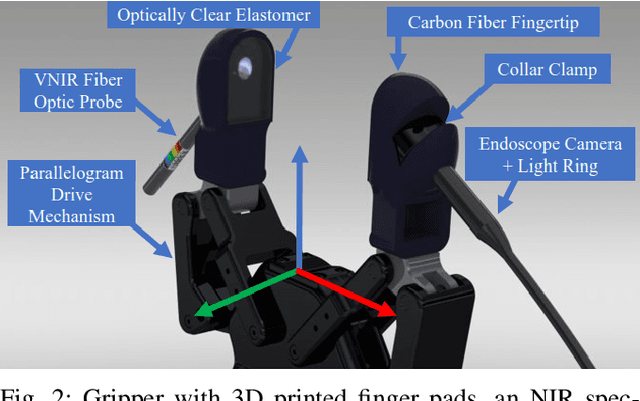
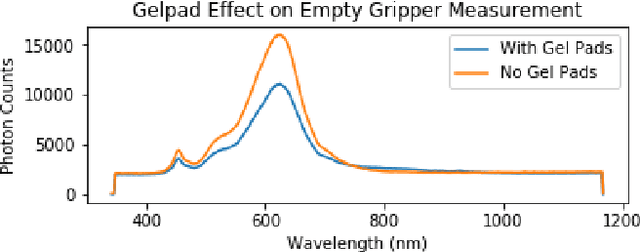

Robots benefit from being able to classify objects they interact with or manipulate based on their material properties. This capability ensures fine manipulation of complex objects through proper grasp pose and force selection. Prior work has focused on haptic or visual processing to determine material type at grasp time. In this work, we introduce a novel parallel robot gripper design and a method for collecting spectral readings and visual images from within the gripper finger. We train a nonlinear Support Vector Machine (SVM) that can classify the material of the object about to be grasped through recursive estimation, with increasing confidence as the distance from the finger tips to the object decreases. In order to validate the hardware design and classification method, we collect samples from 16 real and fake fruit varieties (composed of polystyrene/plastic) resulting in a dataset containing spectral curves, scene images, and high-resolution texture images as the objects are grasped, lifted, and released. Our modeling method demonstrates an accuracy of 96.4% in classifying objects in a 32 class decision problem. This represents a performance improvement by 29.4% over the state of the art computer vision algorithms at distinguishing between visually similar materials. In contrast to prior work, our recursive estimation model accounts for increasing spectral signal strength and allows for decisions to be made as the gripper approaches an object. We conclude that spectroscopy is a promising sensing modality for enabling robots to not only classify grasped objects but also understand their underlying material composition.
Tactile Pose Estimation and Policy Learning for Unknown Object Manipulation
Mar 21, 2022
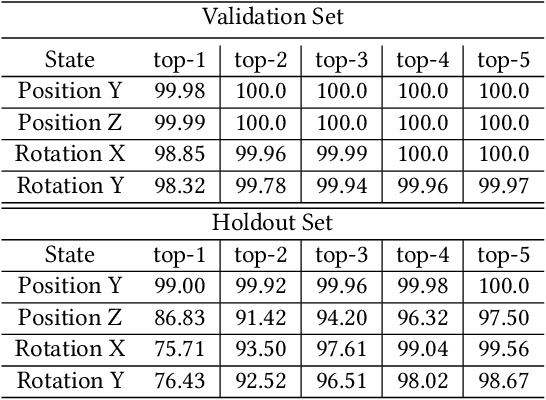
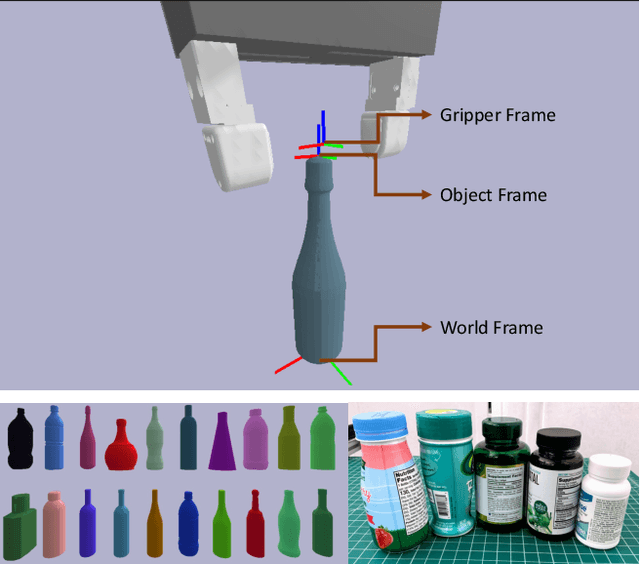

Object pose estimation methods allow finding locations of objects in unstructured environments. This is a highly desired skill for autonomous robot manipulation as robots need to estimate the precise poses of the objects in order to manipulate them. In this paper, we investigate the problems of tactile pose estimation and manipulation for category-level objects. Our proposed method uses a Bayes filter with a learned tactile observation model and a deterministic motion model. Later, we train policies using deep reinforcement learning where the agents use the belief estimation from the Bayes filter. Our models are trained in simulation and transferred to the real world. We analyze the reliability and the performance of our framework through a series of simulated and real-world experiments and compare our method to the baseline work. Our results show that the learned tactile observation model can localize the pose of novel objects at 2-mm and 1-degree resolution for position and orientation, respectively. Furthermore, we experiment on a bottle opening task where the gripper needs to reach the desired grasp state.
Learning Bayes Filter Models for Tactile Localization
Nov 11, 2020



Localizing and tracking the pose of robotic grippers are necessary skills for manipulation tasks. However, the manipulators with imprecise kinematic models (e.g. low-cost arms) or manipulators with unknown world coordinates (e.g. poor camera-arm calibration) cannot locate the gripper with respect to the world. In these circumstances, we can leverage tactile feedback between the gripper and the environment. In this paper, we present learnable Bayes filter models that can localize robotic grippers using tactile feedback. We propose a novel observation model that conditions the tactile feedback on visual maps of the environment along with a motion model to recursively estimate the gripper's location. Our models are trained in simulation with self-supervision and transferred to the real world. Our method is evaluated on a tabletop localization task in which the gripper interacts with objects. We report results in simulation and on a real robot, generalizing over different sizes, shapes, and configurations of the objects.