 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTurning Video Models into Generalist Robot Policies
May 27, 2026Video generative models have emerged as a promising robotics backbone, capable of generating videos that depict the completion of complex tasks across embodiments and environments. Recent work proposes robot foundation models that jointly predict future observations and actions by finetuning video models with action-labeled data. In this paper, we test the limits of an alternative approach: leave the video planner as-is while training an embodiment-specific inverse dynamics model (IDM). This decoupling offers several natural benefits: the video planner remains embodiment-agnostic, different video models can be interchanged easily without re-training the IDM, and the IDM can be independently trained with readily available self-play data. We present a closed-loop, video-to-action policy that combines an action-free video world model with a carefully-designed IDM based on the robot embodiment Jacobian. We demonstrate that our IDM design is both data-efficient and scalable to high-dimensional action spaces. Our policy, which we coin the Video-to-Embodied Robot Action Model (VERA), achieves strong performance across simulated and real-world benchmarks, including zero-shot Panda arm manipulation and 16-DoF Allegro-hand dexterous cube re-orientation. The same video planner can be used across multiple embodiments by pairing it with different embodiment-specific IDMs. Our results show that decoupled video planning plus faithful video-to-action translation is a viable alternative route towards zero-shot, cross-embodiment, and generalizable robot control. More results are available on our project website: https://vera.csail.mit.edu.
Sumo: Dynamic and Generalizable Whole-Body Loco-Manipulation
Apr 09, 2026This paper presents a sim-to-real approach that enables legged robots to dynamically manipulate large and heavy objects with whole-body dexterity. Our key insight is that by performing test-time steering of a pre-trained whole-body control policy with a sample-based planner, we can enable these robots to solve a variety of dynamic loco-manipulation tasks. Interestingly, we find our method generalizes to a diverse set of objects and tasks with no additional tuning or training, and can be further enhanced by flexibly adjusting the cost function at test time. We demonstrate the capabilities of our approach through a variety of challenging loco-manipulation tasks on a Spot quadruped robot in the real world, including uprighting a tire heavier than the robot's nominal lifting capacity and dragging a crowd-control barrier larger and taller than the robot itself. Additionally, we show that the same approach can be generalized to humanoid loco-manipulation tasks, such as opening a door and pushing a table, in simulation. Project code and videos are available at \href{https://sumo.rai-inst.com/}{https://sumo.rai-inst.com/}.
Approximately Optimal Global Planning for Contact-Rich SE(2) Manipulation on a Graph of Reachable Sets
Jan 15, 2026If we consider human manipulation, it is clear that contact-rich manipulation (CRM)-the ability to use any surface of the manipulator to make contact with objects-can be far more efficient and natural than relying solely on end-effectors (i.e., fingertips). However, state-of-the-art model-based planners for CRM are still focused on feasibility rather than optimality, limiting their ability to fully exploit CRM's advantages. We introduce a new paradigm that computes approximately optimal manipulator plans. This approach has two phases. Offline, we construct a graph of mutual reachable sets, where each set contains all object orientations reachable from a starting object orientation and grasp. Online, we plan over this graph, effectively computing and sequencing local plans for globally optimized motion. On a challenging, representative contact-rich task, our approach outperforms a leading planner, reducing task cost by 61%. It also achieves a 91% success rate across 250 queries and maintains sub-minute query times, ultimately demonstrating that globally optimized contact-rich manipulation is now practical for real-world tasks.
Dexterous Contact-Rich Manipulation via the Contact Trust Region
May 04, 2025What is a good local description of contact dynamics for contact-rich manipulation, and where can we trust this local description? While many approaches often rely on the Taylor approximation of dynamics with an ellipsoidal trust region, we argue that such approaches are fundamentally inconsistent with the unilateral nature of contact. As a remedy, we present the Contact Trust Region (CTR), which captures the unilateral nature of contact while remaining efficient for computation. With CTR, we first develop a Model-Predictive Control (MPC) algorithm capable of synthesizing local contact-rich plans. Then, we extend this capability to plan globally by stitching together local MPC plans, enabling efficient and dexterous contact-rich manipulation. To verify the performance of our method, we perform comprehensive evaluations, both in high-fidelity simulation and on hardware, on two contact-rich systems: a planar IiwaBimanual system and a 3D AllegroHand system. On both systems, our method offers a significantly lower-compute alternative to existing RL-based approaches to contact-rich manipulation. In particular, our Allegro in-hand manipulation policy, in the form of a roadmap, takes fewer than 10 minutes to build offline on a standard laptop using just its CPU, with online inference taking just a few seconds. Experiment data, video and code are available at ctr.theaiinstitute.com.
Physics-Driven Data Generation for Contact-Rich Manipulation via Trajectory Optimization
Feb 27, 2025



We present a low-cost data generation pipeline that integrates physics-based simulation, human demonstrations, and model-based planning to efficiently generate large-scale, high-quality datasets for contact-rich robotic manipulation tasks. Starting with a small number of embodiment-flexible human demonstrations collected in a virtual reality simulation environment, the pipeline refines these demonstrations using optimization-based kinematic retargeting and trajectory optimization to adapt them across various robot embodiments and physical parameters. This process yields a diverse, physically consistent dataset that enables cross-embodiment data transfer, and offers the potential to reuse legacy datasets collected under different hardware configurations or physical parameters. We validate the pipeline's effectiveness by training diffusion policies from the generated datasets for challenging contact-rich manipulation tasks across multiple robot embodiments, including a floating Allegro hand and bimanual robot arms. The trained policies are deployed zero-shot on hardware for bimanual iiwa arms, achieving high success rates with minimal human input. Project website: https://lujieyang.github.io/physicsgen/.
Should We Learn Contact-Rich Manipulation Policies from Sampling-Based Planners?
Dec 12, 2024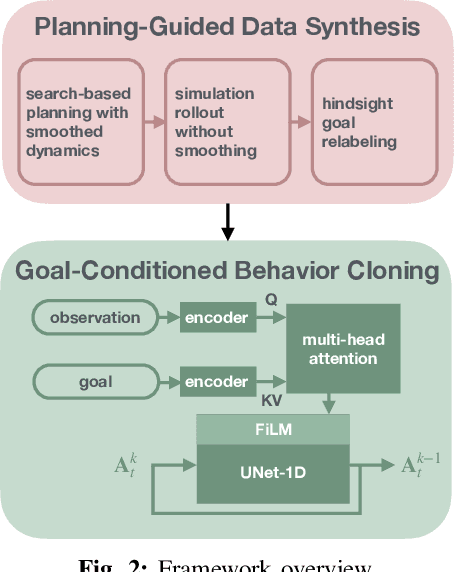
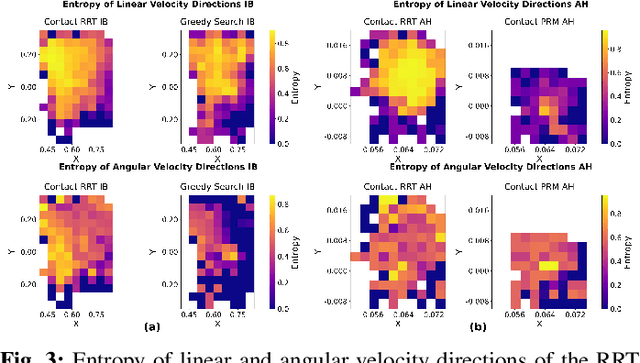

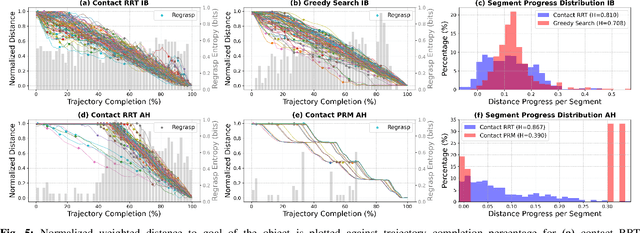
The tremendous success of behavior cloning (BC) in robotic manipulation has been largely confined to tasks where demonstrations can be effectively collected through human teleoperation. However, demonstrations for contact-rich manipulation tasks that require complex coordination of multiple contacts are difficult to collect due to the limitations of current teleoperation interfaces. We investigate how to leverage model-based planning and optimization to generate training data for contact-rich dexterous manipulation tasks. Our analysis reveals that popular sampling-based planners like rapidly exploring random tree (RRT), while efficient for motion planning, produce demonstrations with unfavorably high entropy. This motivates modifications to our data generation pipeline that prioritizes demonstration consistency while maintaining solution diversity. Combined with a diffusion-based goal-conditioned BC approach, our method enables effective policy learning and zero-shot transfer to hardware for two challenging contact-rich manipulation tasks.
Planning-Guided Diffusion Policy Learning for Generalizable Contact-Rich Bimanual Manipulation
Dec 03, 2024



Contact-rich bimanual manipulation involves precise coordination of two arms to change object states through strategically selected contacts and motions. Due to the inherent complexity of these tasks, acquiring sufficient demonstration data and training policies that generalize to unseen scenarios remain a largely unresolved challenge. Building on recent advances in planning through contacts, we introduce Generalizable Planning-Guided Diffusion Policy Learning (GLIDE), an approach that effectively learns to solve contact-rich bimanual manipulation tasks by leveraging model-based motion planners to generate demonstration data in high-fidelity physics simulation. Through efficient planning in randomized environments, our approach generates large-scale and high-quality synthetic motion trajectories for tasks involving diverse objects and transformations. We then train a task-conditioned diffusion policy via behavior cloning using these demonstrations. To tackle the sim-to-real gap, we propose a set of essential design options in feature extraction, task representation, action prediction, and data augmentation that enable learning robust prediction of smooth action sequences and generalization to unseen scenarios. Through experiments in both simulation and the real world, we demonstrate that our approach can enable a bimanual robotic system to effectively manipulate objects of diverse geometries, dimensions, and physical properties. Website: https://glide-manip.github.io/
Is Linear Feedback on Smoothed Dynamics Sufficient for Stabilizing Contact-Rich Plans?
Nov 14, 2024



Designing planners and controllers for contact-rich manipulation is extremely challenging as contact violates the smoothness conditions that many gradient-based controller synthesis tools assume. Contact smoothing approximates a non-smooth system with a smooth one, allowing one to use these synthesis tools more effectively. However, applying classical control synthesis methods to smoothed contact dynamics remains relatively under-explored. This paper analyzes the efficacy of linear controller synthesis using differential simulators based on contact smoothing. We introduce natural baselines for leveraging contact smoothing to compute (a) open-loop plans robust to uncertain conditions and/or dynamics, and (b) feedback gains to stabilize around open-loop plans. Using robotic bimanual whole-body manipulation as a testbed, we perform extensive empirical experiments on over 300 trajectories and analyze why LQR seems insufficient for stabilizing contact-rich plans. The video summarizing this paper and hardware experiments is found here: https://youtu.be/HLaKi6qbwQg?si=_zCAmBBD6rGSitm9.
Dynamic Loss Decay based Robust Oriented Object Detection on Remote Sensing Images with Noisy Labels
May 15, 2024
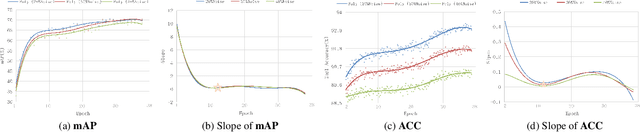

The ambiguous appearance, tiny scale, and fine-grained classes of objects in remote sensing imagery inevitably lead to the noisy annotations in category labels of detection dataset. However, the effects and treatments of the label noises are underexplored in modern oriented remote sensing object detectors. To address this issue, we propose a robust oriented remote sensing object detection method through dynamic loss decay (DLD) mechanism, inspired by the two phase ``early-learning'' and ``memorization'' learning dynamics of deep neural networks on clean and noisy samples. To be specific, we first observe the end point of early learning phase termed as EL, after which the models begin to memorize the false labels that significantly degrade the detection accuracy. Secondly, under the guidance of the training indicator, the losses of each sample are ranked in descending order, and we adaptively decay the losses of the top K largest ones (bad samples) in the following epochs. Because these large losses are of high confidence to be calculated with wrong labels. Experimental results show that the method achieves excellent noise resistance performance tested on multiple public datasets such as HRSC2016 and DOTA-v1.0/v2.0 with synthetic category label noise. Our solution also has won the 2st place in the "fine-grained object detection based on sub-meter remote sensing imagery" track with noisy labels of 2023 National Big Data and Computing Intelligence Challenge.
Intelligent Cardiac Auscultation for Murmur Detection via Parallel-Attentive Models with Uncertainty Estimation
May 07, 2024Heart murmurs are a common manifestation of cardiovascular diseases and can provide crucial clues to early cardiac abnormalities. While most current research methods primarily focus on the accuracy of models, they often overlook other important aspects such as the interpretability of machine learning algorithms and the uncertainty of predictions. This paper introduces a heart murmur detection method based on a parallel-attentive model, which consists of two branches: One is based on a self-attention module and the other one is based on a convolutional network. Unlike traditional approaches, this structure is better equipped to handle long-term dependencies in sequential data, and thus effectively captures the local and global features of heart murmurs. Additionally, we acknowledge the significance of understanding the uncertainty of model predictions in the medical field for clinical decision-making. Therefore, we have incorporated an effective uncertainty estimation method based on Monte Carlo Dropout into our model. Furthermore, we have employed temperature scaling to calibrate the predictions of our probabilistic model, enhancing its reliability. In experiments conducted on the CirCor Digiscope dataset for heart murmur detection, our proposed method achieves a weighted accuracy of 79.8% and an F1 of 65.1%, representing state-of-the-art results.