 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefashioning Emotion Recognition Modelling: The Advent of Generalised Large Models
Paper and Code
Aug 21, 2023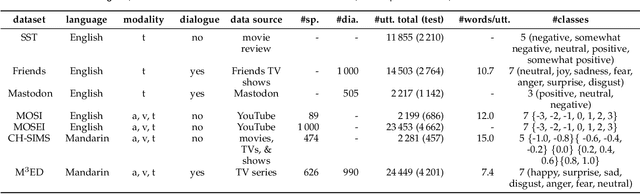
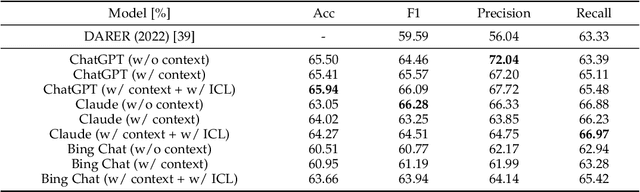
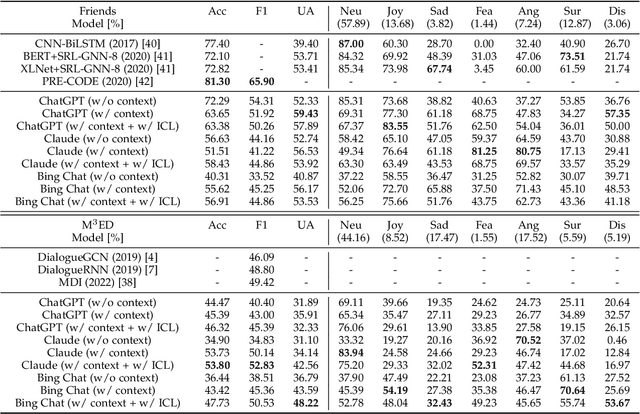
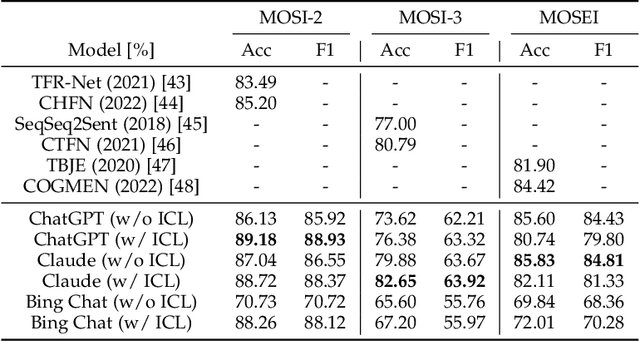
After the inception of emotion recognition or affective computing, it has increasingly become an active research topic due to its broad applications. Over the past couple of decades, emotion recognition models have gradually migrated from statistically shallow models to neural network-based deep models, which can significantly boost the performance of emotion recognition models and consistently achieve the best results on different benchmarks. Therefore, in recent years, deep models have always been considered the first option for emotion recognition. However, the debut of large language models (LLMs), such as ChatGPT, has remarkably astonished the world due to their emerged capabilities of zero/few-shot learning, in-context learning, chain-of-thought, and others that are never shown in previous deep models. In the present paper, we comprehensively investigate how the LLMs perform in emotion recognition in terms of diverse aspects, including in-context learning, few-short learning, accuracy, generalisation, and explanation. Moreover, we offer some insights and pose other potential challenges, hoping to ignite broader discussions about enhancing emotion recognition in the new era of advanced and generalised large models.