 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentity-free Artificial Emotional Intelligence via Micro-Gesture Understanding
May 21, 2024
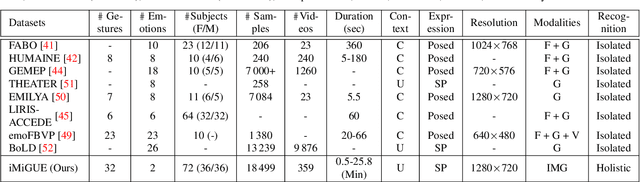
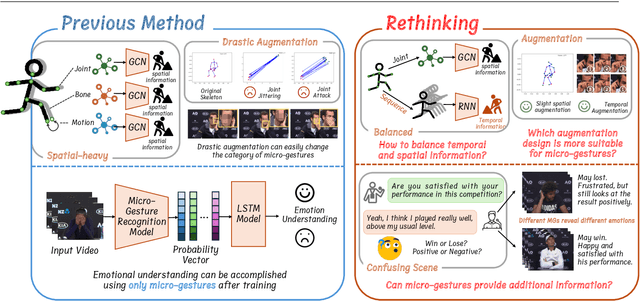
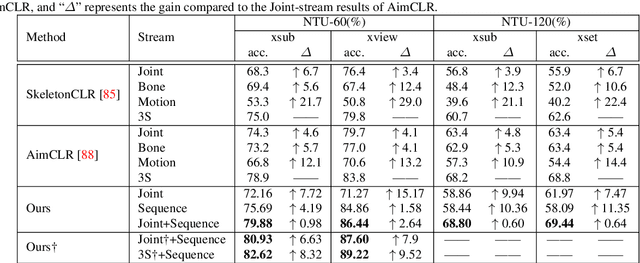
In this work, we focus on a special group of human body language -- the micro-gesture (MG), which differs from the range of ordinary illustrative gestures in that they are not intentional behaviors performed to convey information to others, but rather unintentional behaviors driven by inner feelings. This characteristic introduces two novel challenges regarding micro-gestures that are worth rethinking. The first is whether strategies designed for other action recognition are entirely applicable to micro-gestures. The second is whether micro-gestures, as supplementary data, can provide additional insights for emotional understanding. In recognizing micro-gestures, we explored various augmentation strategies that take into account the subtle spatial and brief temporal characteristics of micro-gestures, often accompanied by repetitiveness, to determine more suitable augmentation methods. Considering the significance of temporal domain information for micro-gestures, we introduce a simple and efficient plug-and-play spatiotemporal balancing fusion method. We not only studied our method on the considered micro-gesture dataset but also conducted experiments on mainstream action datasets. The results show that our approach performs well in micro-gesture recognition and on other datasets, achieving state-of-the-art performance compared to previous micro-gesture recognition methods. For emotional understanding based on micro-gestures, we construct complex emotional reasoning scenarios. Our evaluation, conducted with large language models, shows that micro-gestures play a significant and positive role in enhancing comprehensive emotional understanding. The scenarios we developed can be extended to other micro-gesture-based tasks such as deception detection and interviews. We confirm that our new insights contribute to advancing research in micro-gesture and emotional artificial intelligence.
emoDARTS: Joint Optimisation of CNN & Sequential Neural Network Architectures for Superior Speech Emotion Recognition
Mar 21, 2024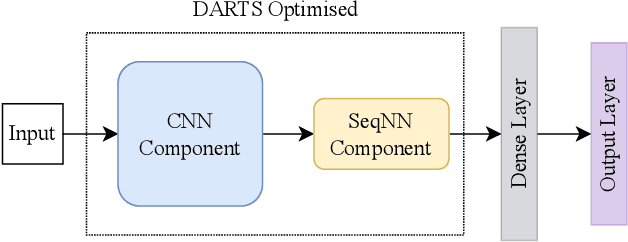
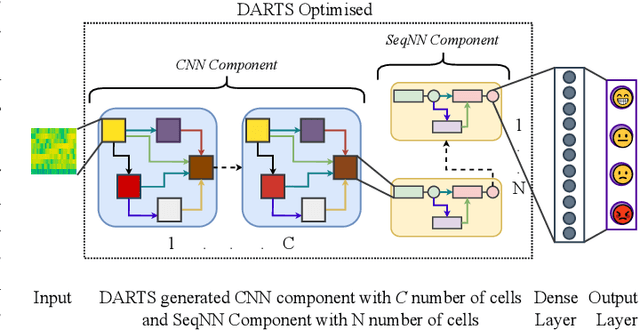

Speech Emotion Recognition (SER) is crucial for enabling computers to understand the emotions conveyed in human communication. With recent advancements in Deep Learning (DL), the performance of SER models has significantly improved. However, designing an optimal DL architecture requires specialised knowledge and experimental assessments. Fortunately, Neural Architecture Search (NAS) provides a potential solution for automatically determining the best DL model. The Differentiable Architecture Search (DARTS) is a particularly efficient method for discovering optimal models. This study presents emoDARTS, a DARTS-optimised joint CNN and Sequential Neural Network (SeqNN: LSTM, RNN) architecture that enhances SER performance. The literature supports the selection of CNN and LSTM coupling to improve performance. While DARTS has previously been used to choose CNN and LSTM operations independently, our technique adds a novel mechanism for selecting CNN and SeqNN operations in conjunction using DARTS. Unlike earlier work, we do not impose limits on the layer order of the CNN. Instead, we let DARTS choose the best layer order inside the DARTS cell. We demonstrate that emoDARTS outperforms conventionally designed CNN-LSTM models and surpasses the best-reported SER results achieved through DARTS on CNN-LSTM by evaluating our approach on the IEMOCAP, MSP-IMPROV, and MSP-Podcast datasets.
Refashioning Emotion Recognition Modelling: The Advent of Generalised Large Models
Aug 21, 2023
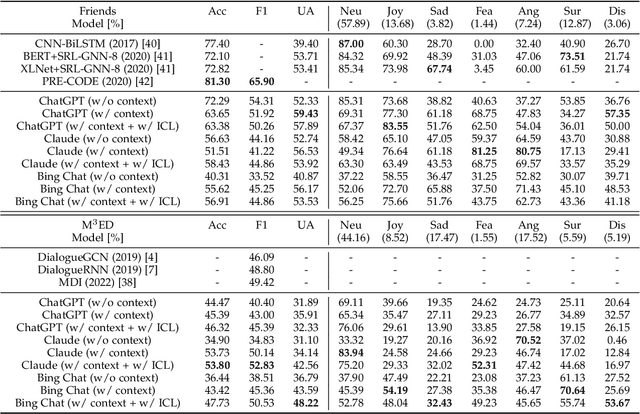
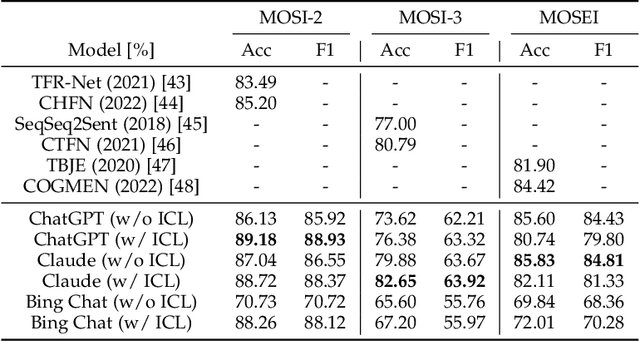
After the inception of emotion recognition or affective computing, it has increasingly become an active research topic due to its broad applications. Over the past couple of decades, emotion recognition models have gradually migrated from statistically shallow models to neural network-based deep models, which can significantly boost the performance of emotion recognition models and consistently achieve the best results on different benchmarks. Therefore, in recent years, deep models have always been considered the first option for emotion recognition. However, the debut of large language models (LLMs), such as ChatGPT, has remarkably astonished the world due to their emerged capabilities of zero/few-shot learning, in-context learning, chain-of-thought, and others that are never shown in previous deep models. In the present paper, we comprehensively investigate how the LLMs perform in emotion recognition in terms of diverse aspects, including in-context learning, few-short learning, accuracy, generalisation, and explanation. Moreover, we offer some insights and pose other potential challenges, hoping to ignite broader discussions about enhancing emotion recognition in the new era of advanced and generalised large models.
Audio Barlow Twins: Self-Supervised Audio Representation Learning
Sep 28, 2022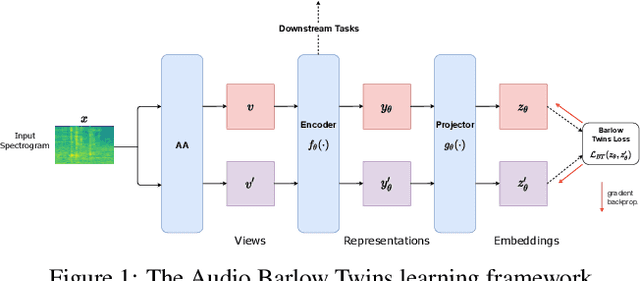
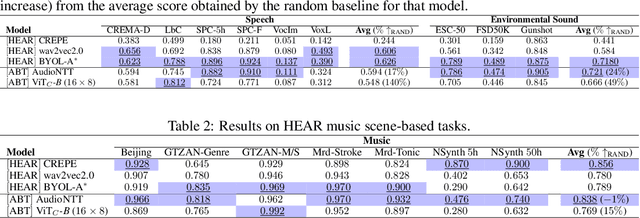

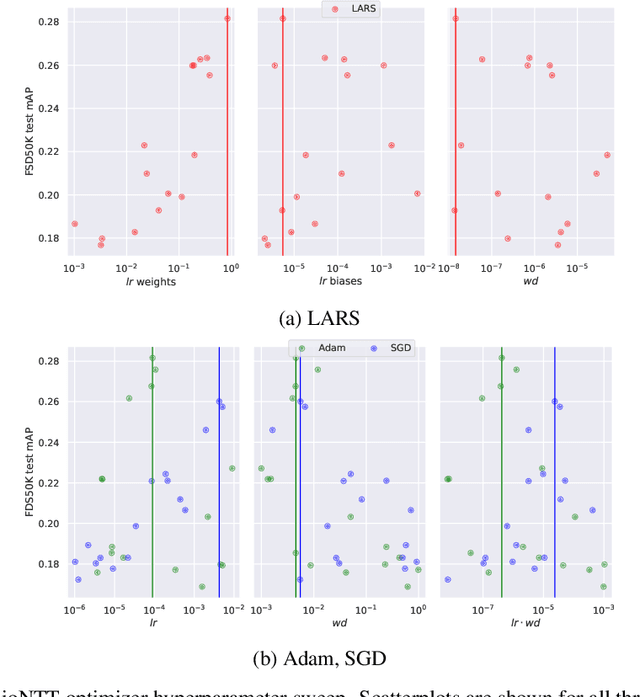
The Barlow Twins self-supervised learning objective requires neither negative samples or asymmetric learning updates, achieving results on a par with the current state-of-the-art within Computer Vision. As such, we present Audio Barlow Twins, a novel self-supervised audio representation learning approach, adapting Barlow Twins to the audio domain. We pre-train on the large-scale audio dataset AudioSet, and evaluate the quality of the learnt representations on 18 tasks from the HEAR 2021 Challenge, achieving results which outperform, or otherwise are on a par with, the current state-of-the-art for instance discrimination self-supervised learning approaches to audio representation learning. Code at https://github.com/jonahanton/SSL_audio.
Predicting Sex and Stroke Success -- Computer-aided Player Grunt Analysis in Tennis Matches
Feb 18, 2022


Professional athletes increasingly use automated analysis of meta- and signal data to improve their training and game performance. As in other related human-to-human research fields, signal data, in particular, contain important performance- and mood-specific indicators for automated analysis. In this paper, we introduce the novel data set SCORE! to investigate the performance of several features and machine learning paradigms in the prediction of the sex and immediate stroke success in tennis matches, based only on vocal expression through players' grunts. The data was gathered from YouTube, labelled under the exact same definition, and the audio processed for modelling. We extract several widely used basic, expert-knowledge, and deep acoustic features of the audio samples and evaluate their effectiveness in combination with various machine learning approaches. In a binary setting, the best system, using spectrograms and a Convolutional Recurrent Neural Network, achieves an unweighted average recall (UAR) of 84.0 % for the player sex prediction task, and 60.3 % predicting stroke success, based only on acoustic cues in players' grunts of both sexes. Further, we achieve a UAR of 58.3 %, and 61.3 %, when the models are exclusively trained on female or male grunts, respectively.
Recent Advances in Computer Audition for Diagnosing COVID-19: An Overview
Dec 08, 2020
Computer audition (CA) has been demonstrated to be efficient in healthcare domains for speech-affecting disorders (e.g., autism spectrum, depression, or Parkinson's disease) and body sound-affecting abnormalities (e. g., abnormal bowel sounds, heart murmurs, or snore sounds). Nevertheless, CA has been underestimated in the considered data-driven technologies for fighting the COVID-19 pandemic caused by the SARS-CoV-2 coronavirus. In this light, summarise the most recent advances in CA for COVID-19 speech and/or sound analysis. While the milestones achieved are encouraging, there are yet not any solid conclusions that can be made. This comes mostly, as data is still sparse, often not sufficiently validated and lacking in systematic comparison with related diseases that affect the respiratory system. In particular, CA-based methods cannot be a standalone screening tool for SARS-CoV-2. We hope this brief overview can provide a good guidance and attract more attention from a broader artificial intelligence community.
Capturing dynamics of post-earnings-announcement drift using genetic algorithm-optimised supervised learning
Sep 07, 2020
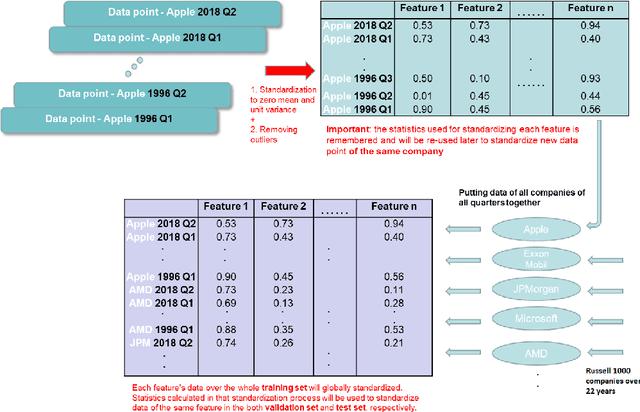


While Post-Earnings-Announcement Drift (PEAD) is one of the most studied stock market anomalies, the current literature is often limited in explaining this phenomenon by a small number of factors using simpler regression methods. In this paper, we use a machine learning based approach instead, and aim to capture the PEAD dynamics using data from a large group of stocks and a wide range of both fundamental and technical factors. Our model is built around the Extreme Gradient Boosting (XGBoost) and uses a long list of engineered input features based on quarterly financial announcement data from 1,106 companies in the Russell 1000 index between 1997 and 2018. We perform numerous experiments on PEAD predictions and analysis and have the following contributions to the literature. First, we show how Post-Earnings-Announcement Drift can be analysed using machine learning methods and demonstrate such methods' prowess in producing credible forecasting on the drift direction. It is the first time PEAD dynamics are studied using XGBoost. We show that the drift direction is in fact driven by different factors for stocks from different industrial sectors and in different quarters and XGBoost is effective in understanding the changing drivers. Second, we show that an XGBoost well optimised by a Genetic Algorithm can help allocate out-of-sample stocks to form portfolios with higher positive returns to long and portfolios with lower negative returns to short, a finding that could be adopted in the process of developing market neutral strategies. Third, we show how theoretical event-driven stock strategies have to grapple with ever changing market prices in reality, reducing their effectiveness. We present a tactic to remedy the difficulty of buying into a moving market when dealing with PEAD signals.
End2You -- The Imperial Toolkit for Multimodal Profiling by End-to-End Learning
Feb 04, 2018
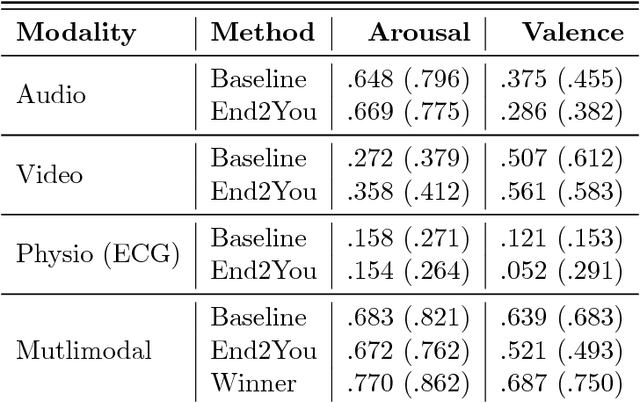
We introduce End2You -- the Imperial College London toolkit for multimodal profiling by end-to-end deep learning. End2You is an open-source toolkit implemented in Python and is based on Tensorflow. It provides capabilities to train and evaluate models in an end-to-end manner, i.e., using raw input. It supports input from raw audio, visual, physiological or other types of information or combination of those, and the output can be of an arbitrary representation, for either classification or regression tasks. To our knowledge, this is the first toolkit that provides generic end-to-end learning for profiling capabilities in either unimodal or multimodal cases. To test our toolkit, we utilise the RECOLA database as was used in the AVEC 2016 challenge. Experimental results indicate that End2You can provide comparable results to state-of-the-art methods despite no need of expert-alike feature representations, but self-learning these from the data "end to end".