 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParameterised Quantum Circuits for Novel Representation Learning in Speech Emotion Recognition
Jan 21, 2025Speech Emotion Recognition (SER) is a complex and challenging task in human-computer interaction due to the intricate dependencies of features and the overlapping nature of emotional expressions conveyed through speech. Although traditional deep learning methods have shown effectiveness, they often struggle to capture subtle emotional variations and overlapping states. This paper introduces a hybrid classical-quantum framework that integrates Parameterised Quantum Circuits (PQCs) with conventional Convolutional Neural Network (CNN) architectures. By leveraging quantum properties such as superposition and entanglement, the proposed model enhances feature representation and captures complex dependencies more effectively than classical methods. Experimental evaluations conducted on benchmark datasets, including IEMOCAP, RECOLA, and MSP-Improv, demonstrate that the hybrid model achieves higher accuracy in both binary and multi-class emotion classification while significantly reducing the number of trainable parameters. While a few existing studies have explored the feasibility of using Quantum Circuits to reduce model complexity, none have successfully shown how they can enhance accuracy. This study is the first to demonstrate that Quantum Circuits has the potential to improve the accuracy of SER. The findings highlight the promise of QML to transform SER, suggesting a promising direction for future research and practical applications in emotion-aware systems.
emoDARTS: Joint Optimisation of CNN & Sequential Neural Network Architectures for Superior Speech Emotion Recognition
Mar 21, 2024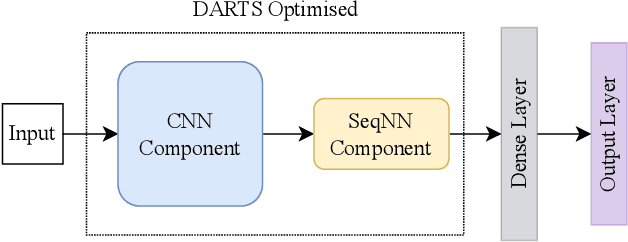
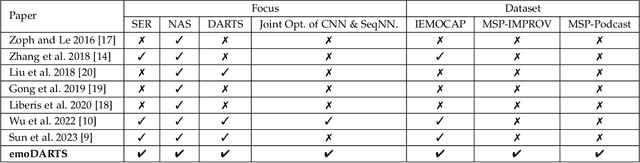
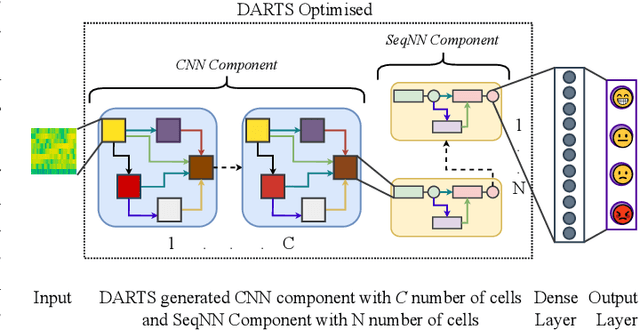

Speech Emotion Recognition (SER) is crucial for enabling computers to understand the emotions conveyed in human communication. With recent advancements in Deep Learning (DL), the performance of SER models has significantly improved. However, designing an optimal DL architecture requires specialised knowledge and experimental assessments. Fortunately, Neural Architecture Search (NAS) provides a potential solution for automatically determining the best DL model. The Differentiable Architecture Search (DARTS) is a particularly efficient method for discovering optimal models. This study presents emoDARTS, a DARTS-optimised joint CNN and Sequential Neural Network (SeqNN: LSTM, RNN) architecture that enhances SER performance. The literature supports the selection of CNN and LSTM coupling to improve performance. While DARTS has previously been used to choose CNN and LSTM operations independently, our technique adds a novel mechanism for selecting CNN and SeqNN operations in conjunction using DARTS. Unlike earlier work, we do not impose limits on the layer order of the CNN. Instead, we let DARTS choose the best layer order inside the DARTS cell. We demonstrate that emoDARTS outperforms conventionally designed CNN-LSTM models and surpasses the best-reported SER results achieved through DARTS on CNN-LSTM by evaluating our approach on the IEMOCAP, MSP-IMPROV, and MSP-Podcast datasets.
Improving Speech Emotion Recognition Performance using Differentiable Architecture Search
May 23, 2023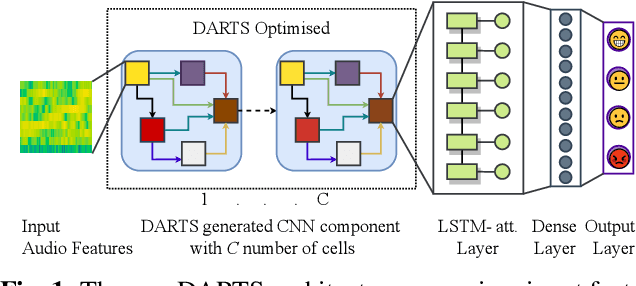
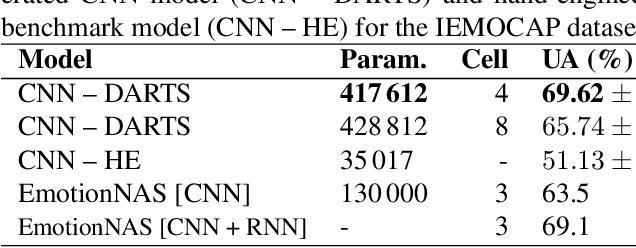
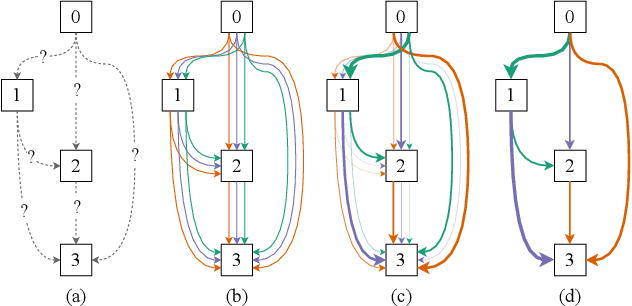
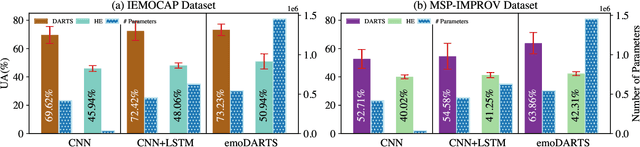
Speech Emotion Recognition (SER) is a critical enabler of emotion-aware communication in human-computer interactions. Deep Learning (DL) has improved the performance of SER models by improving model complexity. However, designing DL architectures requires prior experience and experimental evaluations. Encouragingly, Neural Architecture Search (NAS) allows automatic search for an optimum DL model. In particular, Differentiable Architecture Search (DARTS) is an efficient method of using NAS to search for optimised models. In this paper, we propose DARTS for a joint CNN and LSTM architecture for improving SER performance. Our choice of the CNN LSTM coupling is inspired by results showing that similar models offer improved performance. While SER researchers have considered CNNs and RNNs separately, the viability of using DARTs jointly for CNN and LSTM still needs exploration. Experimenting with the IEMOCAP dataset, we demonstrate that our approach outperforms best-reported results using DARTS for SER.
A novel policy for pre-trained Deep Reinforcement Learning for Speech Emotion Recognition
Jan 31, 2021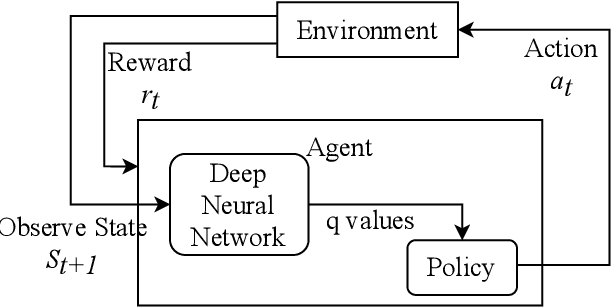


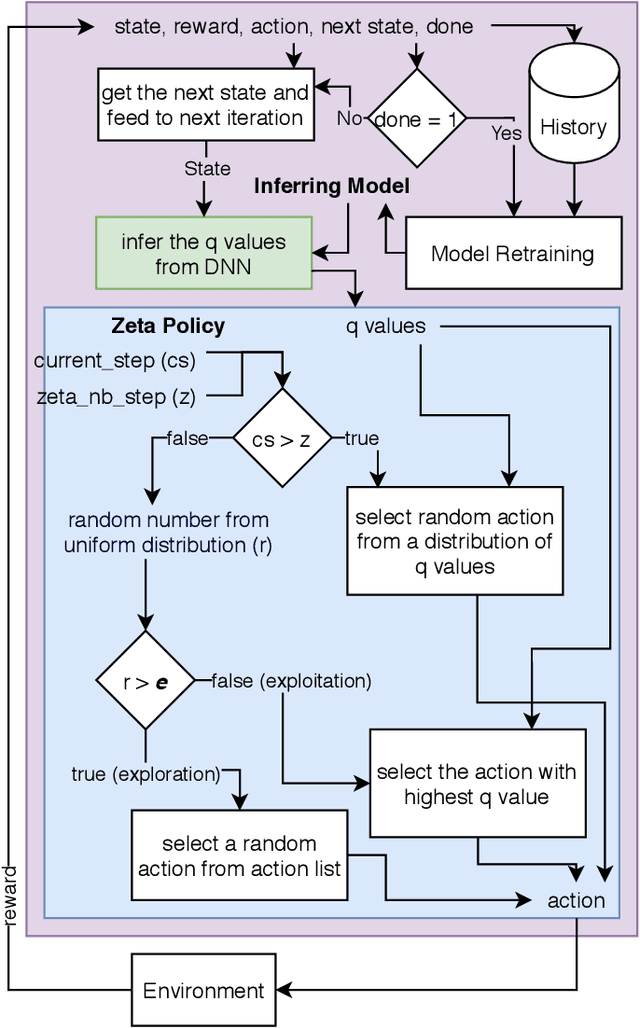
Reinforcement Learning (RL) is a semi-supervised learning paradigm which an agent learns by interacting with an environment. Deep learning in combination with RL provides an efficient method to learn how to interact with the environment is called Deep Reinforcement Learning (deep RL). Deep RL has gained tremendous success in gaming - such as AlphaGo, but its potential have rarely being explored for challenging tasks like Speech Emotion Recognition (SER). The deep RL being used for SER can potentially improve the performance of an automated call centre agent by dynamically learning emotional-aware response to customer queries. While the policy employed by the RL agent plays a major role in action selection, there is no current RL policy tailored for SER. In addition, extended learning period is a general challenge for deep RL which can impact the speed of learning for SER. Therefore, in this paper, we introduce a novel policy - "Zeta policy" which is tailored for SER and apply Pre-training in deep RL to achieve faster learning rate. Pre-training with cross dataset was also studied to discover the feasibility of pre-training the RL Agent with a similar dataset in a scenario of where no real environmental data is not available. IEMOCAP and SAVEE datasets were used for the evaluation with the problem being to recognize four emotions happy, sad, angry and neutral in the utterances provided. Experimental results show that the proposed "Zeta policy" performs better than existing policies. The results also support that pre-training can reduce the training time upon reducing the warm-up period and is robust to cross-corpus scenario.
Pre-training in Deep Reinforcement Learning for Automatic Speech Recognition
Oct 26, 2019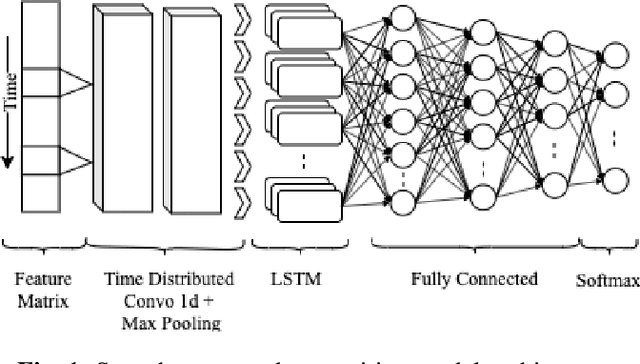

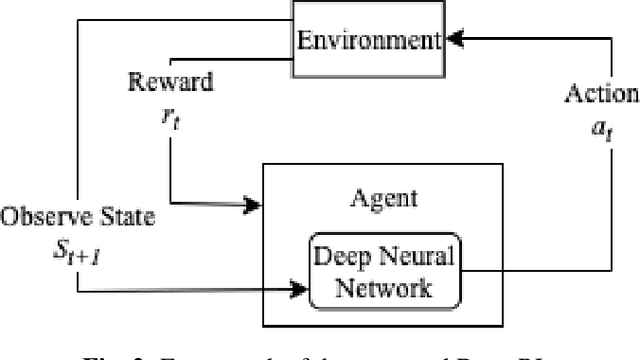
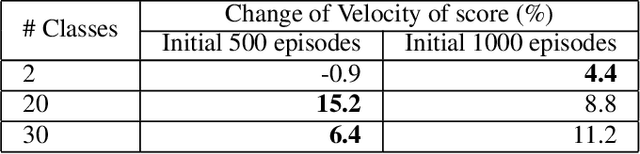
Deep reinforcement learning (deep RL) is a combination of deep learning with reinforcement learning principles to create efficient methods that can learn by interacting with its environment. This led to breakthroughs in many complex tasks that were previously difficult to solve. However, deep RL requires a large amount of training time that makes it difficult to use in various real-life applications like human-computer interaction (HCI). Therefore, in this paper, we study pre-training in deep RL to reduce the training time and improve the performance in speech recognition, a popular application of HCI. We achieve significantly improved performance in less time on a publicly available speech command recognition dataset.