 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA novel policy for pre-trained Deep Reinforcement Learning for Speech Emotion Recognition
Paper and Code
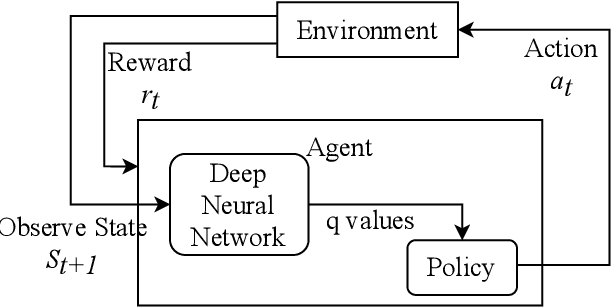


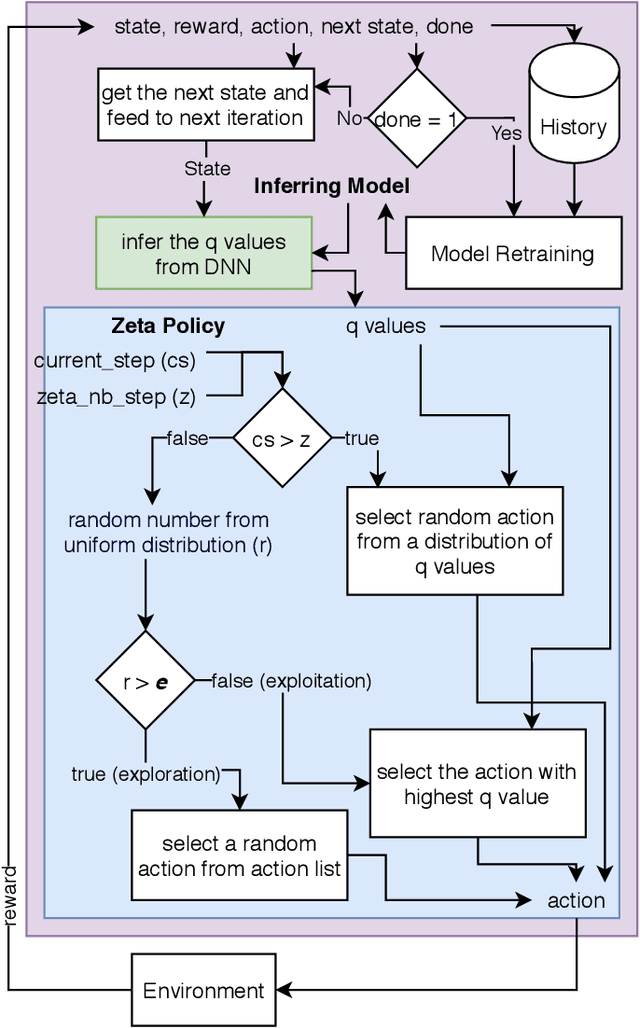
Reinforcement Learning (RL) is a semi-supervised learning paradigm which an agent learns by interacting with an environment. Deep learning in combination with RL provides an efficient method to learn how to interact with the environment is called Deep Reinforcement Learning (deep RL). Deep RL has gained tremendous success in gaming - such as AlphaGo, but its potential have rarely being explored for challenging tasks like Speech Emotion Recognition (SER). The deep RL being used for SER can potentially improve the performance of an automated call centre agent by dynamically learning emotional-aware response to customer queries. While the policy employed by the RL agent plays a major role in action selection, there is no current RL policy tailored for SER. In addition, extended learning period is a general challenge for deep RL which can impact the speed of learning for SER. Therefore, in this paper, we introduce a novel policy - "Zeta policy" which is tailored for SER and apply Pre-training in deep RL to achieve faster learning rate. Pre-training with cross dataset was also studied to discover the feasibility of pre-training the RL Agent with a similar dataset in a scenario of where no real environmental data is not available. IEMOCAP and SAVEE datasets were used for the evaluation with the problem being to recognize four emotions happy, sad, angry and neutral in the utterances provided. Experimental results show that the proposed "Zeta policy" performs better than existing policies. The results also support that pre-training can reduce the training time upon reducing the warm-up period and is robust to cross-corpus scenario.