 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Horizon Electricity Price Forecasting with Deep Learning in the Australian National Electricity Market
Feb 01, 2026Accurate electricity price forecasting (EPF) is essential for operational planning, trading, and flexible asset scheduling in liberalised power systems, yet remains challenging due to volatility, heavy-tailed spikes, and frequent regime shifts. While deep learning (DL) has been increasingly adopted in EPF to capture complex and nonlinear price dynamics, several important gaps persist: (i) limited attention to multi-day horizons beyond day-ahead forecasting, (ii) insufficient exploration of state-of-the-art (SOTA) time series DL models, and (iii) a predominant reliance on aggregated horizon-level evaluation that obscures time-of-day forecasting variation. To address these gaps, we propose a novel EPF framework that extends the forecast horizon to multi-day-ahead by systematically building forecasting models that leverage benchmarked SOTA time series DL models. We conduct a comprehensive evaluation to analyse time-of-day forecasting performance by integrating model assessment at intraday interval levels across all five regions in the Australian National Electricity Market (NEM). The results show that no single model consistently dominates across regions, metrics, and horizons. Overall, standard DL models deliver superior performance in most regions, while SOTA time series DL models demonstrate greater robustness to forecast horizon extension. Intraday interval-level evaluation reveals pronounced diurnal error patterns, indicating that absolute errors peak during the evening ramp, relative errors inflate during midday negative-price regimes, and directional accuracy degrades during periods of frequent trend changes. These findings suggest that future research on DL-based EPF can benefit from enriched feature representations and modelling strategies that enhance longer-term forecasting robustness while maintaining sensitivity to intraday volatility and structural price dynamics.
NeuralPrefix: A Zero-shot Sensory Data Imputation Plugin
Feb 09, 2025Real-world sensing challenges such as sensor failures, communication issues, and power constraints lead to data intermittency. An issue that is known to undermine the traditional classification task that assumes a continuous data stream. Previous works addressed this issue by designing bespoke solutions (i.e. task-specific and/or modality-specific imputation). These approaches, while effective for their intended purposes, had limitations in their applicability across different tasks and sensor modalities. This raises an important question: Can we build a task-agnostic imputation pipeline that is transferable to new sensors without requiring additional training? In this work, we formalise the concept of zero-shot imputation and propose a novel approach that enables the adaptation of pre-trained models to handle data intermittency. This framework, named NeuralPrefix, is a generative neural component that precedes a task model during inference, filling in gaps caused by data intermittency. NeuralPrefix is built as a continuous dynamical system, where its internal state can be estimated at any point in time by solving an Ordinary Differential Equation (ODE). This approach allows for a more versatile and adaptable imputation method, overcoming the limitations of task-specific and modality-specific solutions. We conduct a comprehensive evaluation of NeuralPrefix on multiple sensory datasets, demonstrating its effectiveness across various domains. When tested on intermittent data with a high 50% missing data rate, NeuralPreifx accurately recovers all the missing samples, achieving SSIM score between 0.93-0.96. Zero-shot evaluations show that NeuralPrefix generalises well to unseen datasets, even when the measurements come from a different modality.
Parameterised Quantum Circuits for Novel Representation Learning in Speech Emotion Recognition
Jan 21, 2025Speech Emotion Recognition (SER) is a complex and challenging task in human-computer interaction due to the intricate dependencies of features and the overlapping nature of emotional expressions conveyed through speech. Although traditional deep learning methods have shown effectiveness, they often struggle to capture subtle emotional variations and overlapping states. This paper introduces a hybrid classical-quantum framework that integrates Parameterised Quantum Circuits (PQCs) with conventional Convolutional Neural Network (CNN) architectures. By leveraging quantum properties such as superposition and entanglement, the proposed model enhances feature representation and captures complex dependencies more effectively than classical methods. Experimental evaluations conducted on benchmark datasets, including IEMOCAP, RECOLA, and MSP-Improv, demonstrate that the hybrid model achieves higher accuracy in both binary and multi-class emotion classification while significantly reducing the number of trainable parameters. While a few existing studies have explored the feasibility of using Quantum Circuits to reduce model complexity, none have successfully shown how they can enhance accuracy. This study is the first to demonstrate that Quantum Circuits has the potential to improve the accuracy of SER. The findings highlight the promise of QML to transform SER, suggesting a promising direction for future research and practical applications in emotion-aware systems.
Task Progressive Curriculum Learning for Robust Visual Question Answering
Nov 26, 2024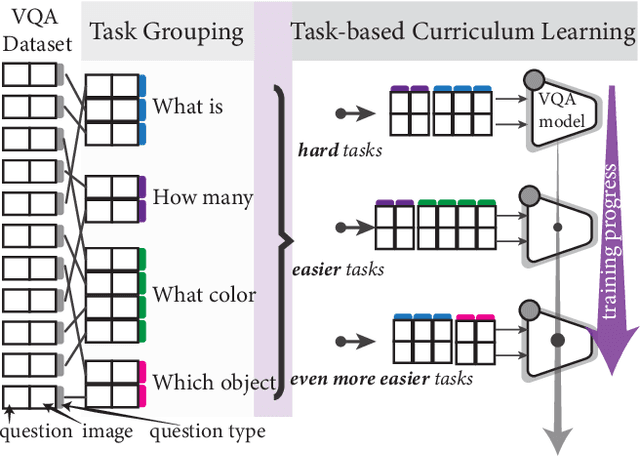
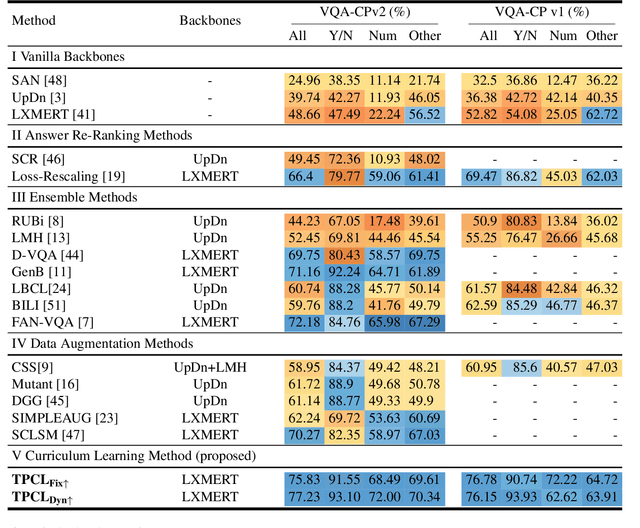
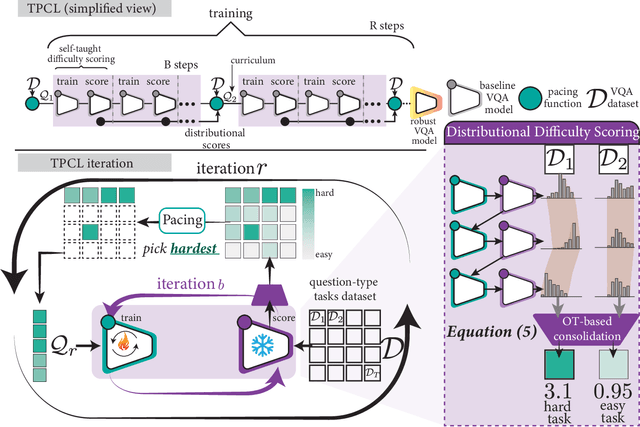
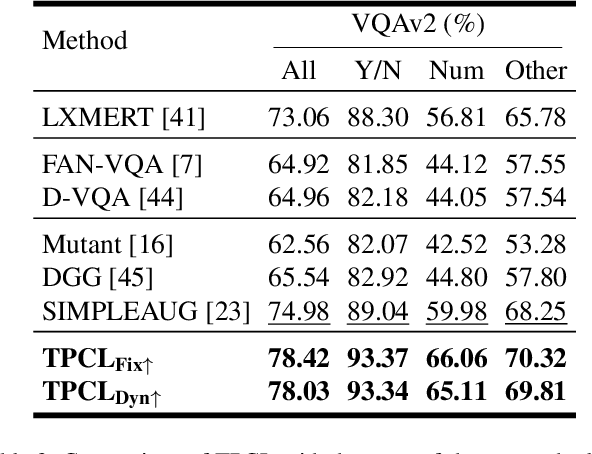
Visual Question Answering (VQA) systems are known for their poor performance in out-of-distribution datasets. An issue that was addressed in previous works through ensemble learning, answer re-ranking, or artificially growing the training set. In this work, we show for the first time that robust Visual Question Answering is attainable by simply enhancing the training strategy. Our proposed approach, Task Progressive Curriculum Learning (TPCL), breaks the main VQA problem into smaller, easier tasks based on the question type. Then, it progressively trains the model on a (carefully crafted) sequence of tasks. We further support the method by a novel distributional-based difficulty measurer. Our approach is conceptually simple, model-agnostic, and easy to implement. We demonstrate TPCL effectiveness through a comprehensive evaluation on standard datasets. Without either data augmentation or explicit debiasing mechanism, it achieves state-of-the-art on VQA-CP v2, VQA-CP v1 and VQA v2 datasets. Extensive experiments demonstrate that TPCL outperforms the most competitive robust VQA approaches by more than 5% and 7% on VQA-CP v2 and VQA-CP v1; respectively. TPCL also can boost VQA baseline backbone performance by up to 28.5%.
emoDARTS: Joint Optimisation of CNN & Sequential Neural Network Architectures for Superior Speech Emotion Recognition
Mar 21, 2024
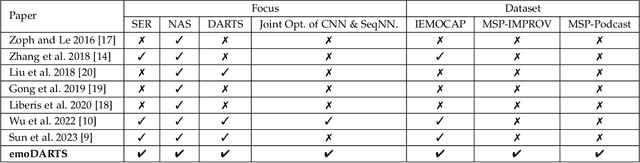
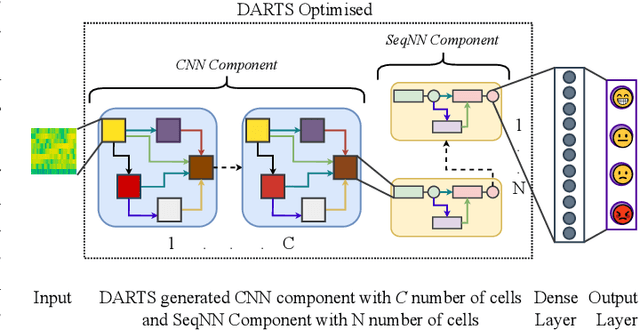

Speech Emotion Recognition (SER) is crucial for enabling computers to understand the emotions conveyed in human communication. With recent advancements in Deep Learning (DL), the performance of SER models has significantly improved. However, designing an optimal DL architecture requires specialised knowledge and experimental assessments. Fortunately, Neural Architecture Search (NAS) provides a potential solution for automatically determining the best DL model. The Differentiable Architecture Search (DARTS) is a particularly efficient method for discovering optimal models. This study presents emoDARTS, a DARTS-optimised joint CNN and Sequential Neural Network (SeqNN: LSTM, RNN) architecture that enhances SER performance. The literature supports the selection of CNN and LSTM coupling to improve performance. While DARTS has previously been used to choose CNN and LSTM operations independently, our technique adds a novel mechanism for selecting CNN and SeqNN operations in conjunction using DARTS. Unlike earlier work, we do not impose limits on the layer order of the CNN. Instead, we let DARTS choose the best layer order inside the DARTS cell. We demonstrate that emoDARTS outperforms conventionally designed CNN-LSTM models and surpasses the best-reported SER results achieved through DARTS on CNN-LSTM by evaluating our approach on the IEMOCAP, MSP-IMPROV, and MSP-Podcast datasets.
Improving Speech Emotion Recognition Performance using Differentiable Architecture Search
May 23, 2023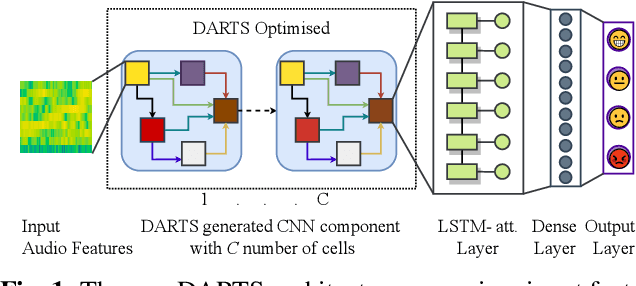
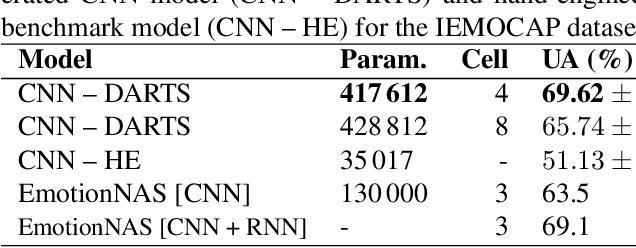
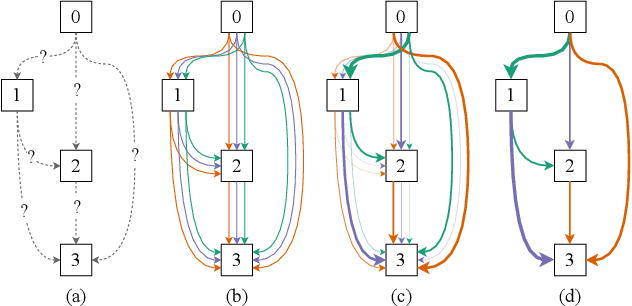
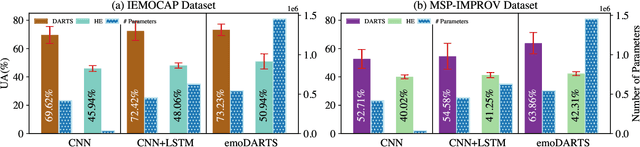
Speech Emotion Recognition (SER) is a critical enabler of emotion-aware communication in human-computer interactions. Deep Learning (DL) has improved the performance of SER models by improving model complexity. However, designing DL architectures requires prior experience and experimental evaluations. Encouragingly, Neural Architecture Search (NAS) allows automatic search for an optimum DL model. In particular, Differentiable Architecture Search (DARTS) is an efficient method of using NAS to search for optimised models. In this paper, we propose DARTS for a joint CNN and LSTM architecture for improving SER performance. Our choice of the CNN LSTM coupling is inspired by results showing that similar models offer improved performance. While SER researchers have considered CNNs and RNNs separately, the viability of using DARTs jointly for CNN and LSTM still needs exploration. Experimenting with the IEMOCAP dataset, we demonstrate that our approach outperforms best-reported results using DARTS for SER.
Multitask Learning from Augmented Auxiliary Data for Improving Speech Emotion Recognition
Jul 12, 2022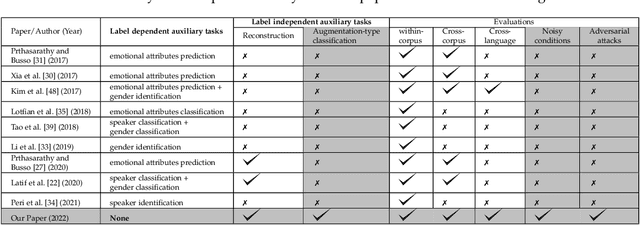
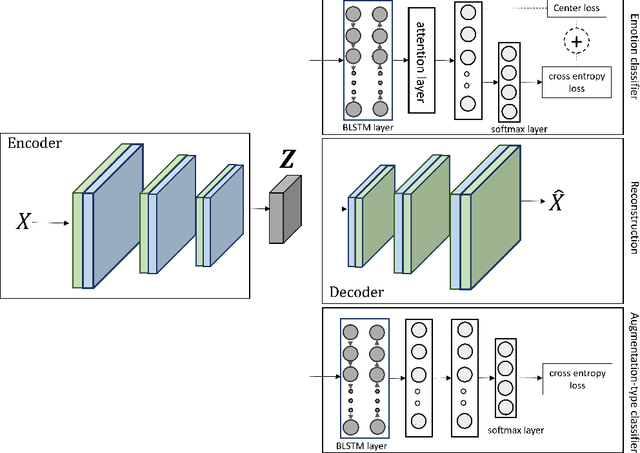
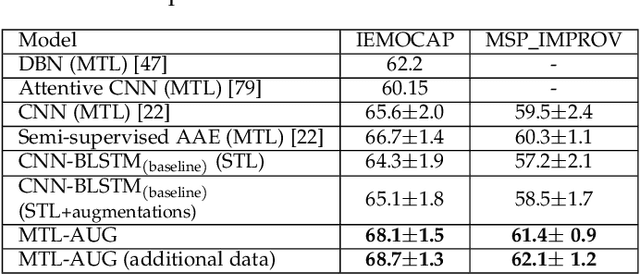
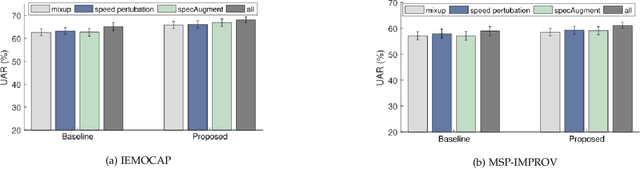
Despite the recent progress in speech emotion recognition (SER), state-of-the-art systems lack generalisation across different conditions. A key underlying reason for poor generalisation is the scarcity of emotion datasets, which is a significant roadblock to designing robust machine learning (ML) models. Recent works in SER focus on utilising multitask learning (MTL) methods to improve generalisation by learning shared representations. However, most of these studies propose MTL solutions with the requirement of meta labels for auxiliary tasks, which limits the training of SER systems. This paper proposes an MTL framework (MTL-AUG) that learns generalised representations from augmented data. We utilise augmentation-type classification and unsupervised reconstruction as auxiliary tasks, which allow training SER systems on augmented data without requiring any meta labels for auxiliary tasks. The semi-supervised nature of MTL-AUG allows for the exploitation of the abundant unlabelled data to further boost the performance of SER. We comprehensively evaluate the proposed framework in the following settings: (1) within corpus, (2) cross-corpus and cross-language, (3) noisy speech, (4) and adversarial attacks. Our evaluations using the widely used IEMOCAP, MSP-IMPROV, and EMODB datasets show improved results compared to existing state-of-the-art methods.
Self Supervised Adversarial Domain Adaptation for Cross-Corpus and Cross-Language Speech Emotion Recognition
Apr 19, 2022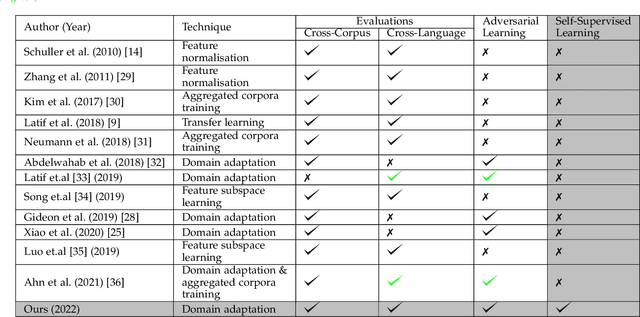
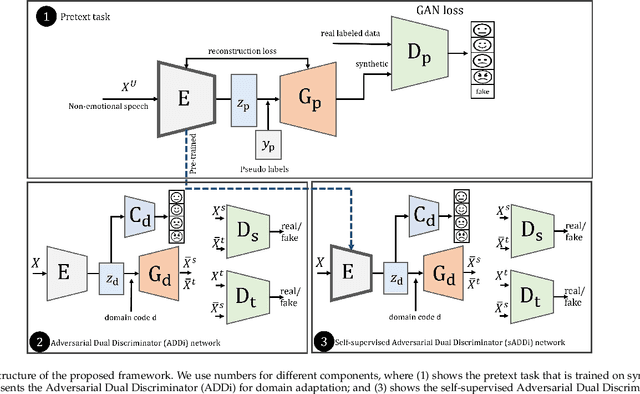
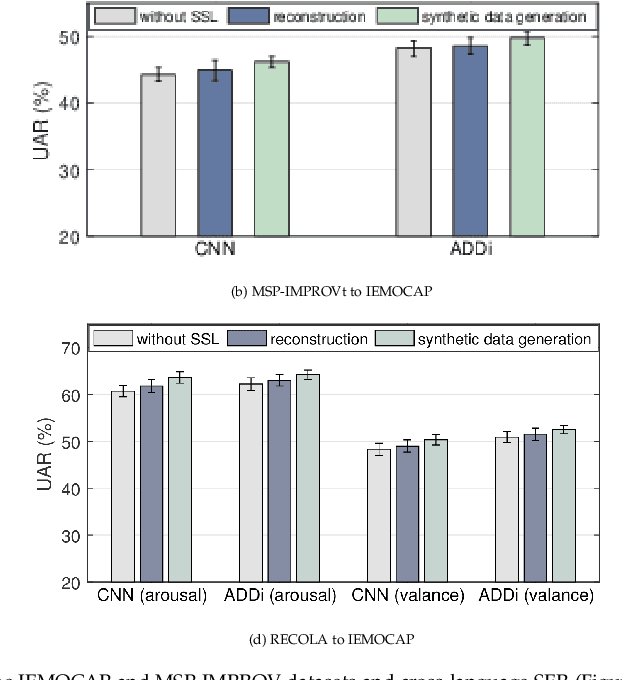
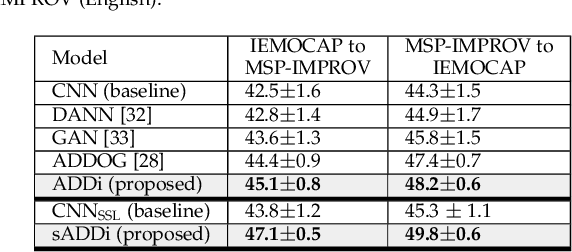
Despite the recent advancement in speech emotion recognition (SER) within a single corpus setting, the performance of these SER systems degrades significantly for cross-corpus and cross-language scenarios. The key reason is the lack of generalisation in SER systems towards unseen conditions, which causes them to perform poorly in cross-corpus and cross-language settings. Recent studies focus on utilising adversarial methods to learn domain generalised representation for improving cross-corpus and cross-language SER to address this issue. However, many of these methods only focus on cross-corpus SER without addressing the cross-language SER performance degradation due to a larger domain gap between source and target language data. This contribution proposes an adversarial dual discriminator (ADDi) network that uses the three-players adversarial game to learn generalised representations without requiring any target data labels. We also introduce a self-supervised ADDi (sADDi) network that utilises self-supervised pre-training with unlabelled data. We propose synthetic data generation as a pretext task in sADDi, enabling the network to produce emotionally discriminative and domain invariant representations and providing complementary synthetic data to augment the system. The proposed model is rigorously evaluated using five publicly available datasets in three languages and compared with multiple studies on cross-corpus and cross-language SER. Experimental results demonstrate that the proposed model achieves improved performance compared to the state-of-the-art methods.
A novel policy for pre-trained Deep Reinforcement Learning for Speech Emotion Recognition
Jan 31, 2021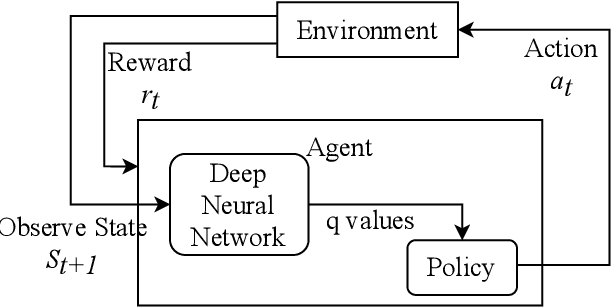


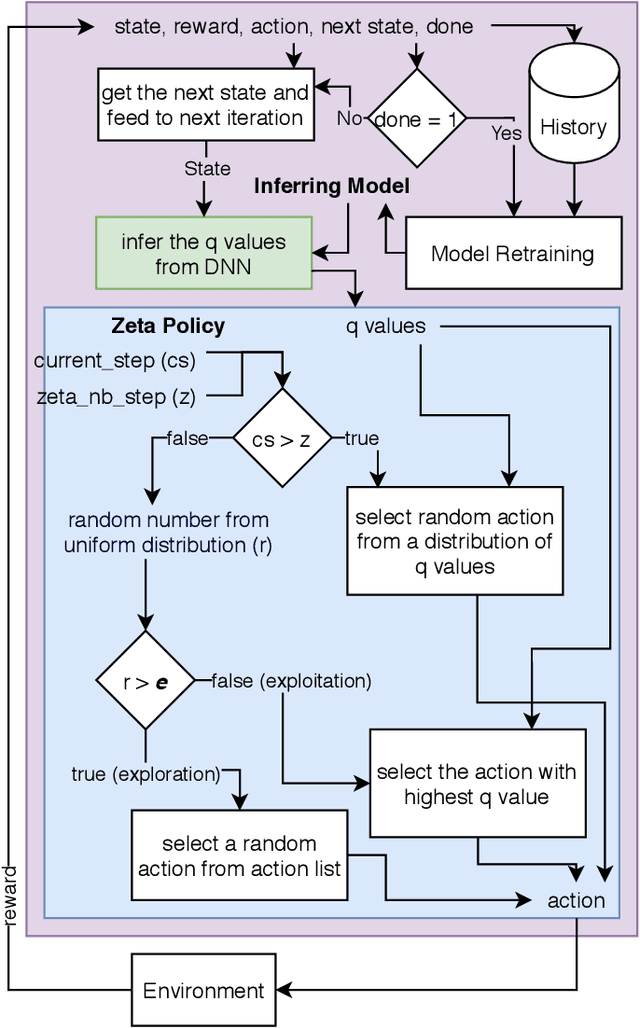
Reinforcement Learning (RL) is a semi-supervised learning paradigm which an agent learns by interacting with an environment. Deep learning in combination with RL provides an efficient method to learn how to interact with the environment is called Deep Reinforcement Learning (deep RL). Deep RL has gained tremendous success in gaming - such as AlphaGo, but its potential have rarely being explored for challenging tasks like Speech Emotion Recognition (SER). The deep RL being used for SER can potentially improve the performance of an automated call centre agent by dynamically learning emotional-aware response to customer queries. While the policy employed by the RL agent plays a major role in action selection, there is no current RL policy tailored for SER. In addition, extended learning period is a general challenge for deep RL which can impact the speed of learning for SER. Therefore, in this paper, we introduce a novel policy - "Zeta policy" which is tailored for SER and apply Pre-training in deep RL to achieve faster learning rate. Pre-training with cross dataset was also studied to discover the feasibility of pre-training the RL Agent with a similar dataset in a scenario of where no real environmental data is not available. IEMOCAP and SAVEE datasets were used for the evaluation with the problem being to recognize four emotions happy, sad, angry and neutral in the utterances provided. Experimental results show that the proposed "Zeta policy" performs better than existing policies. The results also support that pre-training can reduce the training time upon reducing the warm-up period and is robust to cross-corpus scenario.
Deep Representation Learning in Speech Processing: Challenges, Recent Advances, and Future Trends
Jan 02, 2020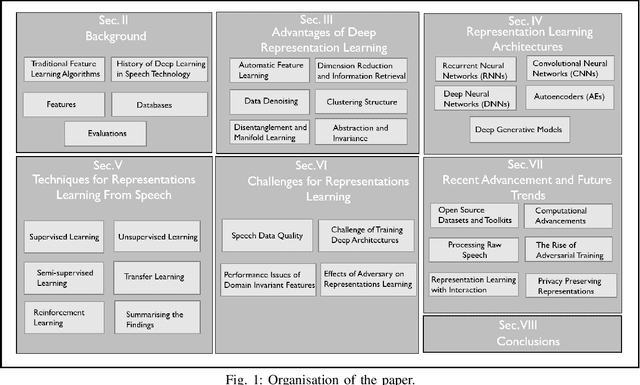
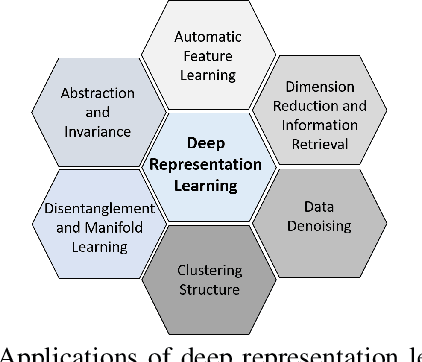
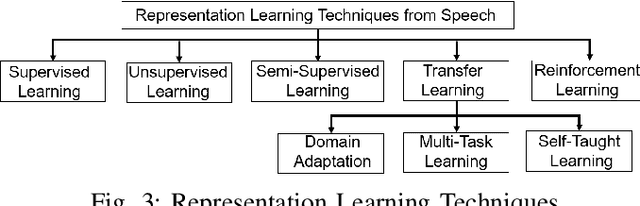
Research on speech processing has traditionally considered the task of designing hand-engineered acoustic features (feature engineering) as a separate distinct problem from the task of designing efficient machine learning (ML) models to make prediction and classification decisions. There are two main drawbacks to this approach: firstly, the feature engineering being manual is cumbersome and requires human knowledge; and secondly, the designed features might not be best for the objective at hand. This has motivated the adoption of a recent trend in speech community towards utilisation of representation learning techniques, which can learn an intermediate representation of the input signal automatically that better suits the task at hand and hence lead to improved performance. The significance of representation learning has increased with advances in deep learning (DL), where the representations are more useful and less dependent on human knowledge, making it very conducive for tasks like classification, prediction, etc. The main contribution of this paper is to present an up-to-date and comprehensive survey on different techniques of speech representation learning by bringing together the scattered research across three distinct research areas including Automatic Speech Recognition (ASR), Speaker Recognition (SR), and Speaker Emotion Recognition (SER). Recent reviews in speech have been conducted for ASR, SR, and SER, however, none of these has focused on the representation learning from speech---a gap that our survey aims to bridge.