 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf Supervised Adversarial Domain Adaptation for Cross-Corpus and Cross-Language Speech Emotion Recognition
Paper and Code
Apr 19, 2022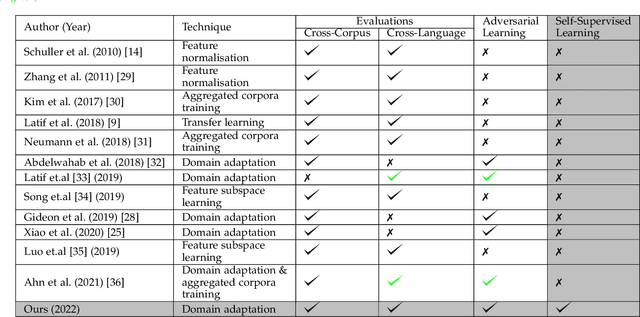
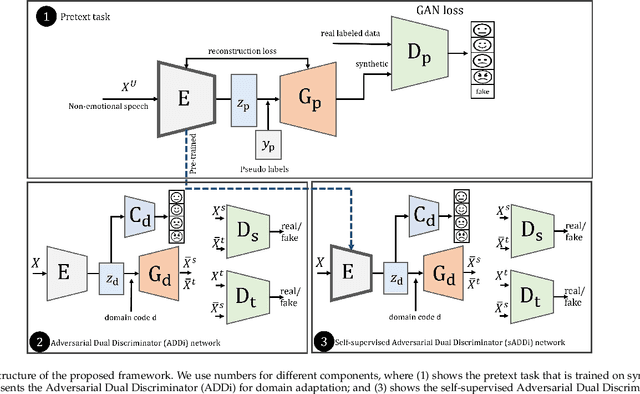
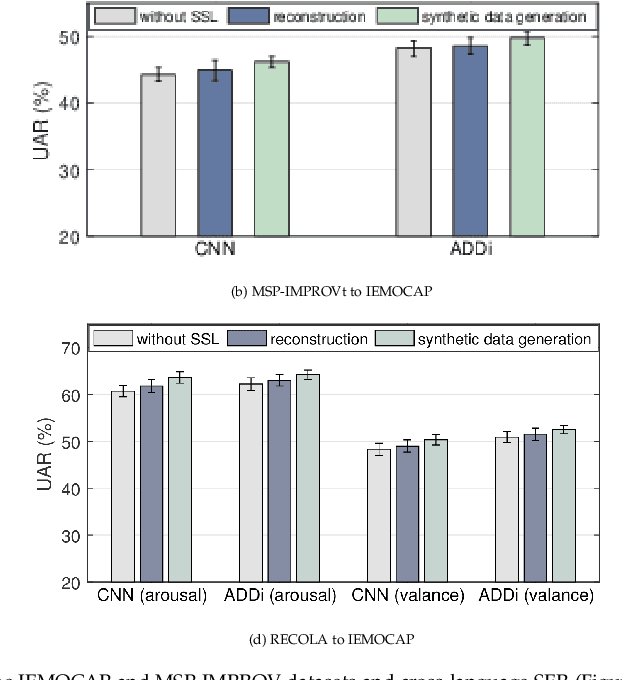
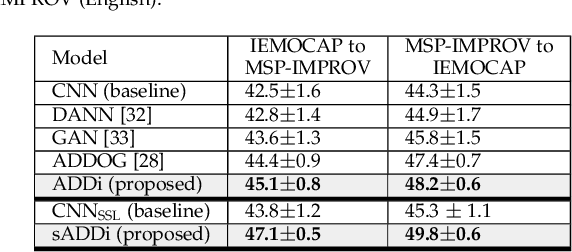
Despite the recent advancement in speech emotion recognition (SER) within a single corpus setting, the performance of these SER systems degrades significantly for cross-corpus and cross-language scenarios. The key reason is the lack of generalisation in SER systems towards unseen conditions, which causes them to perform poorly in cross-corpus and cross-language settings. Recent studies focus on utilising adversarial methods to learn domain generalised representation for improving cross-corpus and cross-language SER to address this issue. However, many of these methods only focus on cross-corpus SER without addressing the cross-language SER performance degradation due to a larger domain gap between source and target language data. This contribution proposes an adversarial dual discriminator (ADDi) network that uses the three-players adversarial game to learn generalised representations without requiring any target data labels. We also introduce a self-supervised ADDi (sADDi) network that utilises self-supervised pre-training with unlabelled data. We propose synthetic data generation as a pretext task in sADDi, enabling the network to produce emotionally discriminative and domain invariant representations and providing complementary synthetic data to augment the system. The proposed model is rigorously evaluated using five publicly available datasets in three languages and compared with multiple studies on cross-corpus and cross-language SER. Experimental results demonstrate that the proposed model achieves improved performance compared to the state-of-the-art methods.