 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature-Augmented Transformers for Robust AI-Text Detection Across Domains and Generators
May 05, 2026AI-generated text is nowadays produced at scale across domains and heterogeneous generation pipelines, making robustness to distribution shift a central requirement for supervised binary detectors. We train transformer-based detectors on HC3 PLUS and calibrate a single decision threshold by maximising balanced accuracy on held-out validation; this threshold is then kept fixed for all downstream test distributions, revealing domain- and generator-dependent error asymmetries under shift. We evaluate in-domain on HC3 PLUS, under cross-dataset transfer to the multi-domain, multi-generator M4 benchmark, and on the external AI-Text-Detection-Pile. Although base models achieve near-ceiling in-domain performance (up to 99.5% balanced accuracy), performance under shift is brittle and strongly model-dependent. Feature augmentation via attention-based linguistic feature fusion improves transfer, with our best model (DeBERTa-v3-base+FeatAttn) achieving 85.9% balanced accuracy on M4. Multi-seed experiments confirm high stability. Under the same fixed-threshold protocol, our model outperforms strong zero-shot baselines by up to +7.22 points. Category-level ablations further show that readability and vocabulary features contribute most to robustness under shift. Overall, these results demonstrate that feature augmentation and a modern DeBERTa backbone significantly outperform earlier BERT/RoBERTa models, while the fixed-threshold protocol provides a more realistic and informative assessment of practical detector robustness.
EmoTrans: A Benchmark for Understanding, Reasoning, and Predicting Emotion Transitions in Multimodal LLMs
Apr 25, 2026Recent multimodal large language models (MLLMs) have shown strong capabilities in perception, reasoning, and generation, and are increasingly used in applications such as social robots and human-computer interaction, where understanding human emotions is essential. However, existing benchmarks mainly formulate emotion understanding as a static recognition problem, leaving it largely unclear whether current MLLMs can understand emotion as a dynamic process that evolves, shifts between states, and unfolds across diverse social contexts. To bridge this gap, we present EmoTrans, a benchmark for evaluating emotion dynamics understanding in multimodal videos. EmoTrans contains 1,000 carefully collected and manually annotated video clips, covering 12 real-world scenarios, and further provides over 3,000 task-specific question-answer (QA) pairs for fine-grained evaluation. The benchmark introduces four tasks, namely Emotion Change Detection (ECD), Emotion State Identification (ESI), Emotion Transition Reasoning (ETR), and Next Emotion Prediction (NEP), forming a progressive evaluation framework from coarse-grained detection to deeper reasoning and prediction. We conduct a comprehensive evaluation of 18 state-of-the-art MLLMs on EmoTrans and obtain two main findings. First, although current MLLMs show relatively stronger performance on coarse-grained emotion change detection, they still struggle with fine-grained emotion dynamics modeling. Second, socially complex settings, especially multi-person scenarios, remain substantially challenging, while reasoning-oriented variants do not consistently yield clear improvements. To facilitate future research, we publicly release the benchmark, evaluation protocol, and code at https://github.com/Emo-gml/EmoTrans.
Enhancing Efficiency and Performance in Deepfake Audio Detection through Neuron-level dropin & Neuroplasticity Mechanisms
Mar 25, 2026Current audio deepfake detection has achieved remarkable performance using diverse deep learning architectures such as ResNet, and has seen further improvements with the introduction of large models (LMs) like Wav2Vec. The success of large language models (LLMs) further demonstrates the benefits of scaling model parameters, but also highlights one bottleneck where performance gains are constrained by parameter counts. Simply stacking additional layers, as done in current LLMs, is computationally expensive and requires full retraining. Furthermore, existing low-rank adaptation methods are primarily applied to attention-based architectures, which limits their scope. Inspired by the neuronal plasticity observed in mammalian brains, we propose novel algorithms, dropin and further plasticity, that dynamically adjust the number of neurons in certain layers to flexibly modulate model parameters. We evaluate these algorithms on multiple architectures, including ResNet, Gated Recurrent Neural Networks, and Wav2Vec. Experimental results using the widely recognised ASVSpoof2019 LA, PA, and FakeorReal dataset demonstrate consistent improvements in computational efficiency with the dropin approach and a maximum of around 39% and 66% relative reduction in Equal Error Rate with the dropin and plasticity approach among these dataset, respectively. The code and supplementary material are available at Github link.
Neuron-Level Emotion Control in Speech-Generative Large Audio-Language Models
Mar 18, 2026Large audio-language models (LALMs) can produce expressive speech, yet reliable emotion control remains elusive: conversions often miss the target affect and may degrade linguistic fidelity through refusals, hallucinations, or paraphrase. We present, to our knowledge, the first neuron-level study of emotion control in speech-generative LALMs and demonstrate that compact emotion-sensitive neurons (ESNs) are causally actionable, enabling training-free emotion steering at inference time. ESNs are identified via success-filtered activation aggregation enforcing both emotion realization and content preservation. Across three LALMs (Qwen2.5-Omni-7B, MiniCPM-o 4.5, Kimi-Audio), ESN interventions yield emotion-specific gains that generalize to unseen speakers and are supported by automatic and human evaluation. Controllability depends on selector design, mask sparsity, filtering, and intervention strength. Our results establish a mechanistic framework for training-free emotion control in speech generation.
SmoothCLAP: Soft-Target Enhanced Contrastive Language\--Audio Pretraining for Affective Computing
Jan 18, 2026The ambiguity of human emotions poses several challenges for machine learning models, as they often overlap and lack clear delineating boundaries. Contrastive language-audio pretraining (CLAP) has emerged as a key technique for generalisable emotion recognition. However, as conventional CLAP enforces a strict one-to-one alignment between paired audio-text samples, it overlooks intra-modal similarity and treats all non-matching pairs as equally negative. This conflicts with the fuzzy boundaries between different emotions. To address this limitation, we propose SmoothCLAP, which introduces softened targets derived from intra-modal similarity and paralinguistic features. By combining these softened targets with conventional contrastive supervision, SmoothCLAP learns embeddings that respect graded emotional relationships, while retaining the same inference pipeline as CLAP. Experiments on eight affective computing tasks across English and German demonstrate that SmoothCLAP is consistently achieving superior performance. Our results highlight that leveraging soft supervision is a promising strategy for building emotion-aware audio-text models.
Affect and Effect: Limitations of regularisation-based continual learning in EEG-based emotion classification
Jan 09, 2026Generalisation to unseen subjects in EEG-based emotion classification remains a challenge due to high inter-and intra-subject variability. Continual learning (CL) poses a promising solution by learning from a sequence of tasks while mitigating catastrophic forgetting. Regularisation-based CL approaches, such as Elastic Weight Consolidation (EWC), Synaptic Intelligence (SI), and Memory Aware Synapses (MAS), are commonly used as baselines in EEG-based CL studies, yet their suitability for this problem remains underexplored. This study theoretically and empirically finds that regularisation-based CL methods show limited performance for EEG-based emotion classification on the DREAMER and SEED datasets. We identify a fundamental misalignment in the stability-plasticity trade-off, where regularisation-based methods prioritise mitigating catastrophic forgetting (backward transfer) over adapting to new subjects (forward transfer). We investigate this limitation under subject-incremental sequences and observe that: (1) the heuristics for estimating parameter importance become less reliable under noisy data and covariate shift, (2) gradients on parameters deemed important by these heuristics often interfere with gradient updates required for new subjects, moving optimisation away from the minimum, (3) importance values accumulated across tasks over-constrain the model, and (4) performance is sensitive to subject order. Forward transfer showed no statistically significant improvement over sequential fine-tuning (p > 0.05 across approaches and datasets). The high variability of EEG signals means past subjects provide limited value to future subjects. Regularisation-based continual learning approaches are therefore limited for robust generalisation to unseen subjects in EEG-based emotion classification.
Discovering and Causally Validating Emotion-Sensitive Neurons in Large Audio-Language Models
Jan 06, 2026Emotion is a central dimension of spoken communication, yet, we still lack a mechanistic account of how modern large audio-language models (LALMs) encode it internally. We present the first neuron-level interpretability study of emotion-sensitive neurons (ESNs) in LALMs and provide causal evidence that such units exist in Qwen2.5-Omni, Kimi-Audio, and Audio Flamingo 3. Across these three widely used open-source models, we compare frequency-, entropy-, magnitude-, and contrast-based neuron selectors on multiple emotion recognition benchmarks. Using inference-time interventions, we reveal a consistent emotion-specific signature: ablating neurons selected for a given emotion disproportionately degrades recognition of that emotion while largely preserving other classes, whereas gain-based amplification steers predictions toward the target emotion. These effects arise with modest identification data and scale systematically with intervention strength. We further observe that ESNs exhibit non-uniform layer-wise clustering with partial cross-dataset transfer. Taken together, our results offer a causal, neuron-level account of emotion decisions in LALMs and highlight targeted neuron interventions as an actionable handle for controllable affective behaviors.
AI-enhanced conversational agents for personalized asthma support Factors for engagement, value and efficacy
Jul 22, 2025Asthma-related deaths in the UK are the highest in Europe, and only 30% of patients access basic care. There is a need for alternative approaches to reaching people with asthma in order to provide health education, self-management support and bridges to care. Automated conversational agents (specifically, mobile chatbots) present opportunities for providing alternative and individually tailored access to health education, self-management support and risk self-assessment. But would patients engage with a chatbot, and what factors influence engagement? We present results from a patient survey (N=1257) devised by a team of asthma clinicians, patients, and technology developers, conducted to identify optimal factors for efficacy, value and engagement for a chatbot. Results indicate that most adults with asthma (53%) are interested in using a chatbot and the patients most likely to do so are those who believe their asthma is more serious and who are less confident about self-management. Results also indicate enthusiasm for 24/7 access, personalisation, and for WhatsApp as the preferred access method (compared to app, voice assistant, SMS or website). Obstacles to uptake include security/privacy concerns and skepticism of technological capabilities. We present detailed findings and consolidate these into 7 recommendations for developers for optimising efficacy of chatbot-based health support.
Articulatory Feature Prediction from Surface EMG during Speech Production
May 20, 2025



We present a model for predicting articulatory features from surface electromyography (EMG) signals during speech production. The proposed model integrates convolutional layers and a Transformer block, followed by separate predictors for articulatory features. Our approach achieves a high prediction correlation of approximately 0.9 for most articulatory features. Furthermore, we demonstrate that these predicted articulatory features can be decoded into intelligible speech waveforms. To our knowledge, this is the first method to decode speech waveforms from surface EMG via articulatory features, offering a novel approach to EMG-based speech synthesis. Additionally, we analyze the relationship between EMG electrode placement and articulatory feature predictability, providing knowledge-driven insights for optimizing EMG electrode configurations. The source code and decoded speech samples are publicly available.
The First MPDD Challenge: Multimodal Personality-aware Depression Detection
May 15, 2025
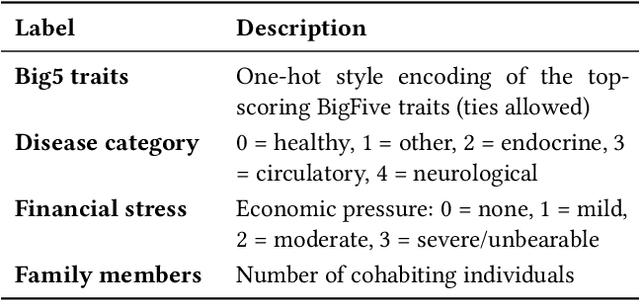


Depression is a widespread mental health issue affecting diverse age groups, with notable prevalence among college students and the elderly. However, existing datasets and detection methods primarily focus on young adults, neglecting the broader age spectrum and individual differences that influence depression manifestation. Current approaches often establish a direct mapping between multimodal data and depression indicators, failing to capture the complexity and diversity of depression across individuals. This challenge includes two tracks based on age-specific subsets: Track 1 uses the MPDD-Elderly dataset for detecting depression in older adults, and Track 2 uses the MPDD-Young dataset for detecting depression in younger participants. The Multimodal Personality-aware Depression Detection (MPDD) Challenge aims to address this gap by incorporating multimodal data alongside individual difference factors. We provide a baseline model that fuses audio and video modalities with individual difference information to detect depression manifestations in diverse populations. This challenge aims to promote the development of more personalized and accurate de pression detection methods, advancing mental health research and fostering inclusive detection systems. More details are available on the official challenge website: https://hacilab.github.io/MPDDChallenge.github.io.