 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAffective Computing Has Changed: The Foundation Model Disruption
Sep 13, 2024The dawn of Foundation Models has on the one hand revolutionised a wide range of research problems, and, on the other hand, democratised the access and use of AI-based tools by the general public. We even observe an incursion of these models into disciplines related to human psychology, such as the Affective Computing domain, suggesting their affective, emerging capabilities. In this work, we aim to raise awareness of the power of Foundation Models in the field of Affective Computing by synthetically generating and analysing multimodal affective data, focusing on vision, linguistics, and speech (acoustics). We also discuss some fundamental problems, such as ethical issues and regulatory aspects, related to the use of Foundation Models in this research area.
On Prompt Sensitivity of ChatGPT in Affective Computing
Mar 20, 2024



Recent studies have demonstrated the emerging capabilities of foundation models like ChatGPT in several fields, including affective computing. However, accessing these emerging capabilities is facilitated through prompt engineering. Despite the existence of some prompting techniques, the field is still rapidly evolving and many prompting ideas still require investigation. In this work, we introduce a method to evaluate and investigate the sensitivity of the performance of foundation models based on different prompts or generation parameters. We perform our evaluation on ChatGPT within the scope of affective computing on three major problems, namely sentiment analysis, toxicity detection, and sarcasm detection. First, we carry out a sensitivity analysis on pivotal parameters in auto-regressive text generation, specifically the temperature parameter $T$ and the top-$p$ parameter in Nucleus sampling, dictating how conservative or creative the model should be during generation. Furthermore, we explore the efficacy of several prompting ideas, where we explore how giving different incentives or structures affect the performance. Our evaluation takes into consideration performance measures on the affective computing tasks, and the effectiveness of the model to follow the stated instructions, hence generating easy-to-parse responses to be smoothly used in downstream applications.
A Wide Evaluation of ChatGPT on Affective Computing Tasks
Aug 26, 2023
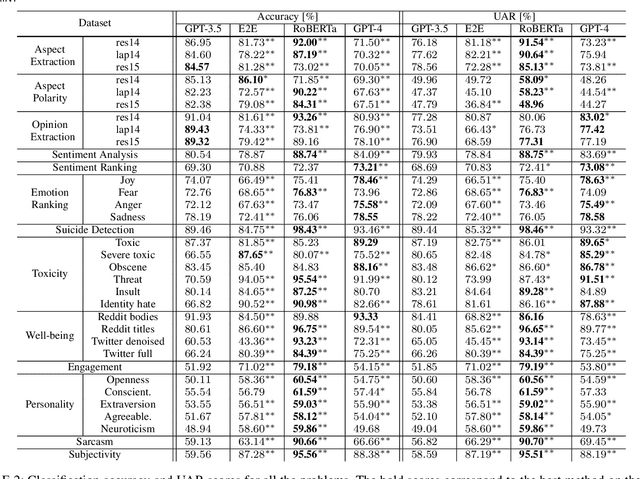
With the rise of foundation models, a new artificial intelligence paradigm has emerged, by simply using general purpose foundation models with prompting to solve problems instead of training a separate machine learning model for each problem. Such models have been shown to have emergent properties of solving problems that they were not initially trained on. The studies for the effectiveness of such models are still quite limited. In this work, we widely study the capabilities of the ChatGPT models, namely GPT-4 and GPT-3.5, on 13 affective computing problems, namely aspect extraction, aspect polarity classification, opinion extraction, sentiment analysis, sentiment intensity ranking, emotions intensity ranking, suicide tendency detection, toxicity detection, well-being assessment, engagement measurement, personality assessment, sarcasm detection, and subjectivity detection. We introduce a framework to evaluate the ChatGPT models on regression-based problems, such as intensity ranking problems, by modelling them as pairwise ranking classification. We compare ChatGPT against more traditional NLP methods, such as end-to-end recurrent neural networks and transformers. The results demonstrate the emergent abilities of the ChatGPT models on a wide range of affective computing problems, where GPT-3.5 and especially GPT-4 have shown strong performance on many problems, particularly the ones related to sentiment, emotions, or toxicity. The ChatGPT models fell short for problems with implicit signals, such as engagement measurement and subjectivity detection.
Can ChatGPT's Responses Boost Traditional Natural Language Processing?
Jul 06, 2023The employment of foundation models is steadily expanding, especially with the launch of ChatGPT and the release of other foundation models. These models have shown the potential of emerging capabilities to solve problems, without being particularly trained to solve. A previous work demonstrated these emerging capabilities in affective computing tasks; the performance quality was similar to traditional Natural Language Processing (NLP) techniques, but falling short of specialised trained models, like fine-tuning of the RoBERTa language model. In this work, we extend this by exploring if ChatGPT has novel knowledge that would enhance existing specialised models when they are fused together. We achieve this by investigating the utility of verbose responses from ChatGPT about solving a downstream task, in addition to studying the utility of fusing that with existing NLP methods. The study is conducted on three affective computing problems, namely sentiment analysis, suicide tendency detection, and big-five personality assessment. The results conclude that ChatGPT has indeed novel knowledge that can improve existing NLP techniques by way of fusion, be it early or late fusion.
Will Affective Computing Emerge from Foundation Models and General AI? A First Evaluation on ChatGPT
Mar 03, 2023ChatGPT has shown the potential of emerging general artificial intelligence capabilities, as it has demonstrated competent performance across many natural language processing tasks. In this work, we evaluate the capabilities of ChatGPT to perform text classification on three affective computing problems, namely, big-five personality prediction, sentiment analysis, and suicide tendency detection. We utilise three baselines, a robust language model (RoBERTa-base), a legacy word model with pretrained embeddings (Word2Vec), and a simple bag-of-words baseline (BoW). Results show that the RoBERTa trained for a specific downstream task generally has a superior performance. On the other hand, ChatGPT provides decent results, and is relatively comparable to the Word2Vec and BoW baselines. ChatGPT further shows robustness against noisy data, where Word2Vec models achieve worse results due to noise. Results indicate that ChatGPT is a good generalist model that is capable of achieving good results across various problems without any specialised training, however, it is not as good as a specialised model for a downstream task.