 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAffective Computing Has Changed: The Foundation Model Disruption
Sep 13, 2024The dawn of Foundation Models has on the one hand revolutionised a wide range of research problems, and, on the other hand, democratised the access and use of AI-based tools by the general public. We even observe an incursion of these models into disciplines related to human psychology, such as the Affective Computing domain, suggesting their affective, emerging capabilities. In this work, we aim to raise awareness of the power of Foundation Models in the field of Affective Computing by synthetically generating and analysing multimodal affective data, focusing on vision, linguistics, and speech (acoustics). We also discuss some fundamental problems, such as ethical issues and regulatory aspects, related to the use of Foundation Models in this research area.
HEAR4Health: A blueprint for making computer audition a staple of modern healthcare
Jan 25, 2023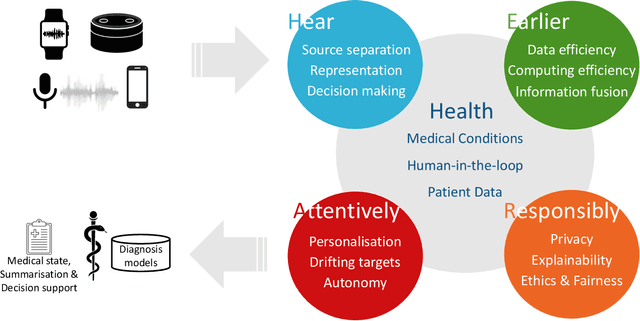

Recent years have seen a rapid increase in digital medicine research in an attempt to transform traditional healthcare systems to their modern, intelligent, and versatile equivalents that are adequately equipped to tackle contemporary challenges. This has led to a wave of applications that utilise AI technologies; first and foremost in the fields of medical imaging, but also in the use of wearables and other intelligent sensors. In comparison, computer audition can be seen to be lagging behind, at least in terms of commercial interest. Yet, audition has long been a staple assistant for medical practitioners, with the stethoscope being the quintessential sign of doctors around the world. Transforming this traditional technology with the use of AI entails a set of unique challenges. We categorise the advances needed in four key pillars: Hear, corresponding to the cornerstone technologies needed to analyse auditory signals in real-life conditions; Earlier, for the advances needed in computational and data efficiency; Attentively, for accounting to individual differences and handling the longitudinal nature of medical data; and, finally, Responsibly, for ensuring compliance to the ethical standards accorded to the field of medicine.
COVYT: Introducing the Coronavirus YouTube and TikTok speech dataset featuring the same speakers with and without infection
Jun 20, 2022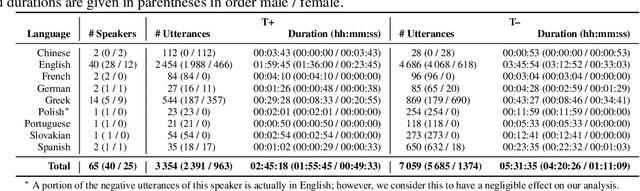
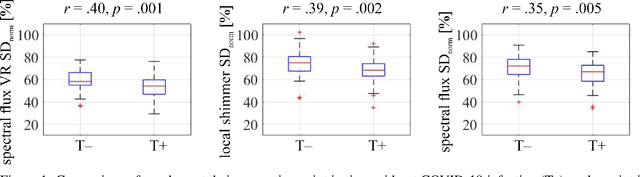
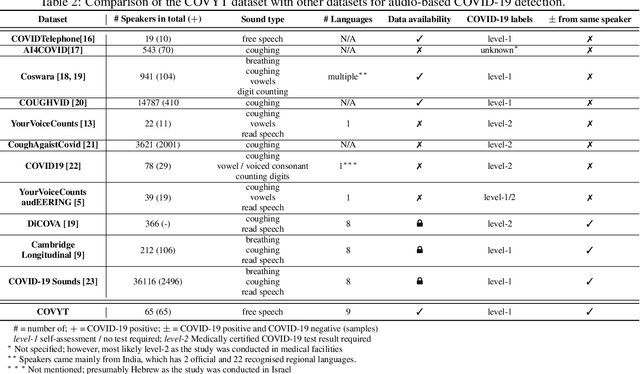
More than two years after its outbreak, the COVID-19 pandemic continues to plague medical systems around the world, putting a strain on scarce resources, and claiming human lives. From the very beginning, various AI-based COVID-19 detection and monitoring tools have been pursued in an attempt to stem the tide of infections through timely diagnosis. In particular, computer audition has been suggested as a non-invasive, cost-efficient, and eco-friendly alternative for detecting COVID-19 infections through vocal sounds. However, like all AI methods, also computer audition is heavily dependent on the quantity and quality of available data, and large-scale COVID-19 sound datasets are difficult to acquire -- amongst other reasons -- due to the sensitive nature of such data. To that end, we introduce the COVYT dataset -- a novel COVID-19 dataset collected from public sources containing more than 8 hours of speech from 65 speakers. As compared to other existing COVID-19 sound datasets, the unique feature of the COVYT dataset is that it comprises both COVID-19 positive and negative samples from all 65 speakers. We analyse the acoustic manifestation of COVID-19 on the basis of these perfectly speaker characteristic balanced `in-the-wild' data using interpretable audio descriptors, and investigate several classification scenarios that shed light into proper partitioning strategies for a fair speech-based COVID-19 detection.
The voice of COVID-19: Acoustic correlates of infection
Dec 17, 2020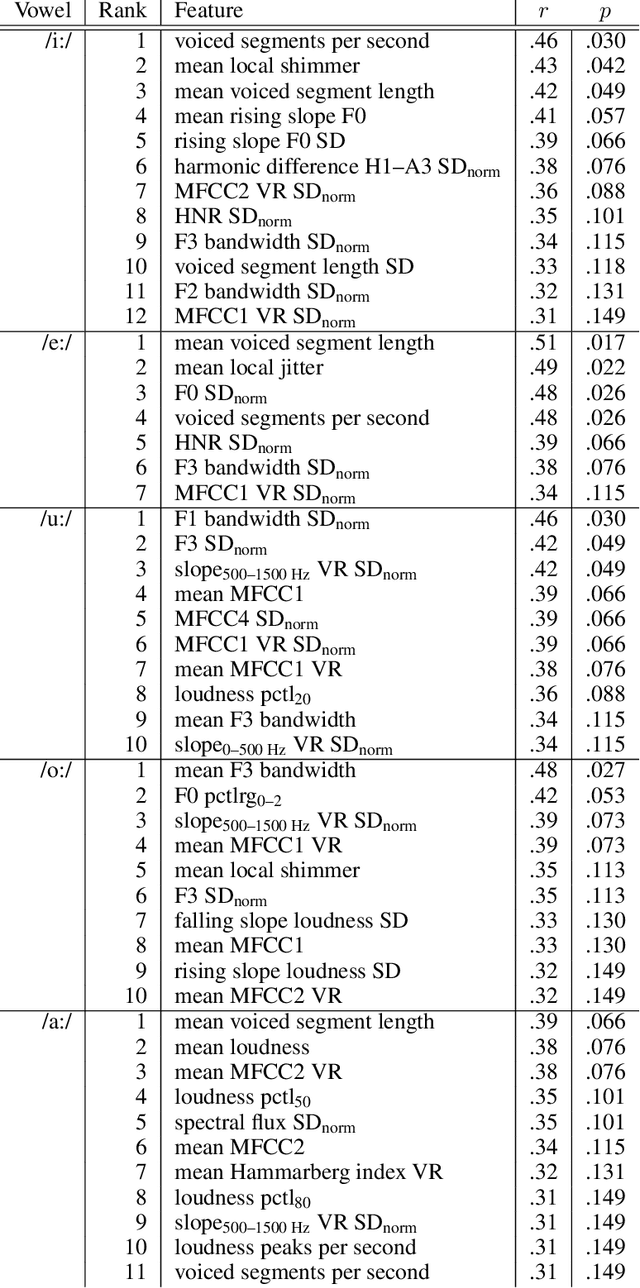
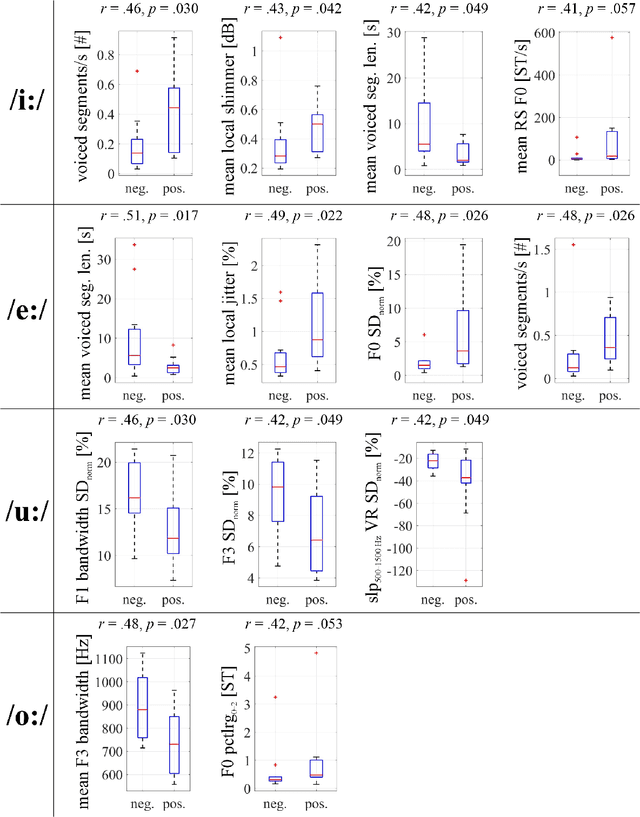
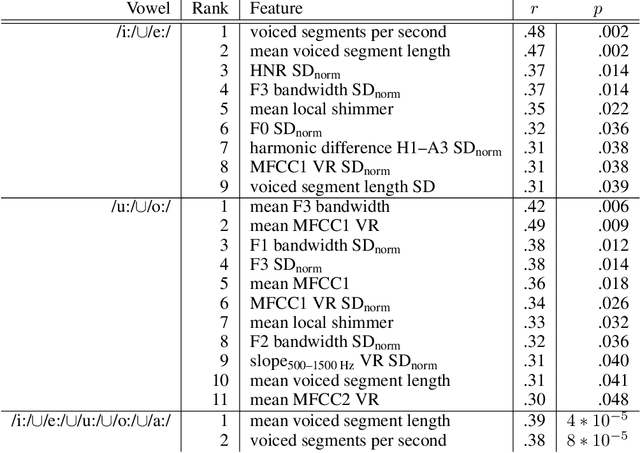
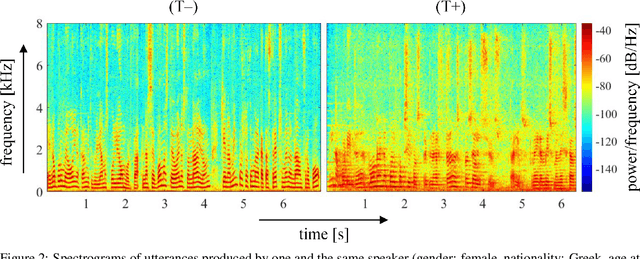
COVID-19 is a global health crisis that has been affecting many aspects of our daily lives throughout the past year. The symptomatology of COVID-19 is heterogeneous with a severity continuum. A considerable proportion of symptoms are related to pathological changes in the vocal system, leading to the assumption that COVID-19 may also affect voice production. For the very first time, the present study aims to investigate voice acoustic correlates of an infection with COVID-19 on the basis of a comprehensive acoustic parameter set. We compare 88 acoustic features extracted from recordings of the vowels /i:/, /e:/, /o:/, /u:/, and /a:/ produced by 11 symptomatic COVID-19 positive and 11 COVID-19 negative German-speaking participants. We employ the Mann-Whitney U test and calculate effect sizes to identify features with the most prominent group differences. The mean voiced segment length and the number of voiced segments per second yield the most important differences across all vowels indicating discontinuities in the pulmonic airstream during phonation in COVID-19 positive participants. Group differences in the front vowels /i:/ and /e:/ are additionally reflected in the variation of the fundamental frequency and the harmonics-to-noise ratio, group differences in back vowels /o:/ and /u:/ in statistics of the Mel-frequency cepstral coefficients and the spectral slope. Findings of this study can be considered an important proof-of-concept contribution for a potential future voice-based identification of individuals infected with COVID-19.