 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHEAR4Health: A blueprint for making computer audition a staple of modern healthcare
Jan 25, 2023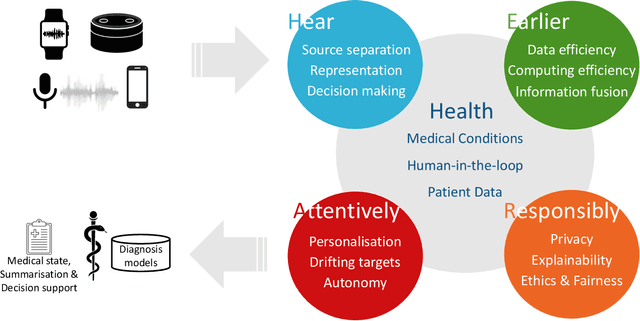

Recent years have seen a rapid increase in digital medicine research in an attempt to transform traditional healthcare systems to their modern, intelligent, and versatile equivalents that are adequately equipped to tackle contemporary challenges. This has led to a wave of applications that utilise AI technologies; first and foremost in the fields of medical imaging, but also in the use of wearables and other intelligent sensors. In comparison, computer audition can be seen to be lagging behind, at least in terms of commercial interest. Yet, audition has long been a staple assistant for medical practitioners, with the stethoscope being the quintessential sign of doctors around the world. Transforming this traditional technology with the use of AI entails a set of unique challenges. We categorise the advances needed in four key pillars: Hear, corresponding to the cornerstone technologies needed to analyse auditory signals in real-life conditions; Earlier, for the advances needed in computational and data efficiency; Attentively, for accounting to individual differences and handling the longitudinal nature of medical data; and, finally, Responsibly, for ensuring compliance to the ethical standards accorded to the field of medicine.
Computational Charisma -- A Brick by Brick Blueprint for Building Charismatic Artificial Intelligence
Dec 31, 2022


Charisma is considered as one's ability to attract and potentially also influence others. Clearly, there can be considerable interest from an artificial intelligence's (AI) perspective to provide it with such skill. Beyond, a plethora of use cases opens up for computational measurement of human charisma, such as for tutoring humans in the acquisition of charisma, mediating human-to-human conversation, or identifying charismatic individuals in big social data. A number of models exist that base charisma on various dimensions, often following the idea that charisma is given if someone could and would help others. Examples include influence (could help) and affability (would help) in scientific studies or power (could help), presence, and warmth (both would help) as a popular concept. Modelling high levels in these dimensions for humanoid robots or virtual agents, seems accomplishable. Beyond, also automatic measurement appears quite feasible with the recent advances in the related fields of Affective Computing and Social Signal Processing. Here, we, thereforem present a blueprint for building machines that can appear charismatic, but also analyse the charisma of others. To this end, we first provide the psychological perspective including different models of charisma and behavioural cues of it. We then switch to conversational charisma in spoken language as an exemplary modality that is essential for human-human and human-computer conversations. The computational perspective then deals with the recognition and generation of charismatic behaviour by AI. This includes an overview of the state of play in the field and the aforementioned blueprint. We then name exemplary use cases of computational charismatic skills before switching to ethical aspects and concluding this overview and perspective on building charisma-enabled AI.
Self-Supervised Attention Networks and Uncertainty Loss Weighting for Multi-Task Emotion Recognition on Vocal Bursts
Sep 27, 2022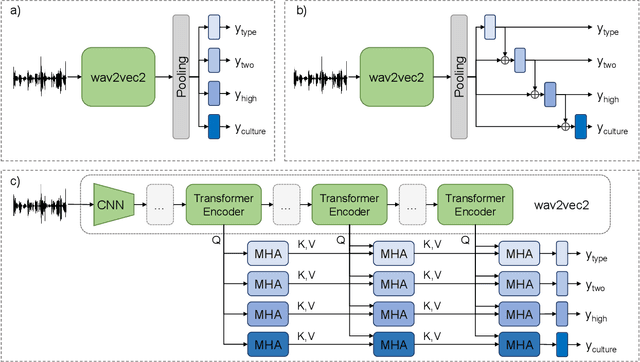
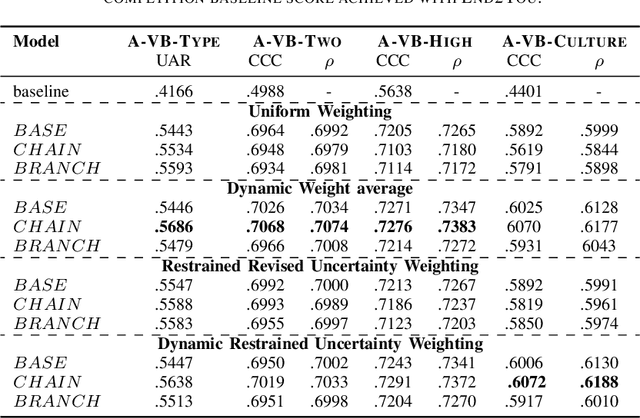

Vocal bursts play an important role in communicating affect, making them valuable for improving speech emotion recognition. Here, we present our approach for classifying vocal bursts and predicting their emotional significance in the ACII Affective Vocal Burst Workshop & Challenge 2022 (A-VB). We use a large self-supervised audio model as shared feature extractor and compare multiple architectures built on classifier chains and attention networks, combined with uncertainty loss weighting strategies. Our approach surpasses the challenge baseline by a wide margin on all four tasks.
Dynamic Restrained Uncertainty Weighting Loss for Multitask Learning of Vocal Expression
Jun 27, 2022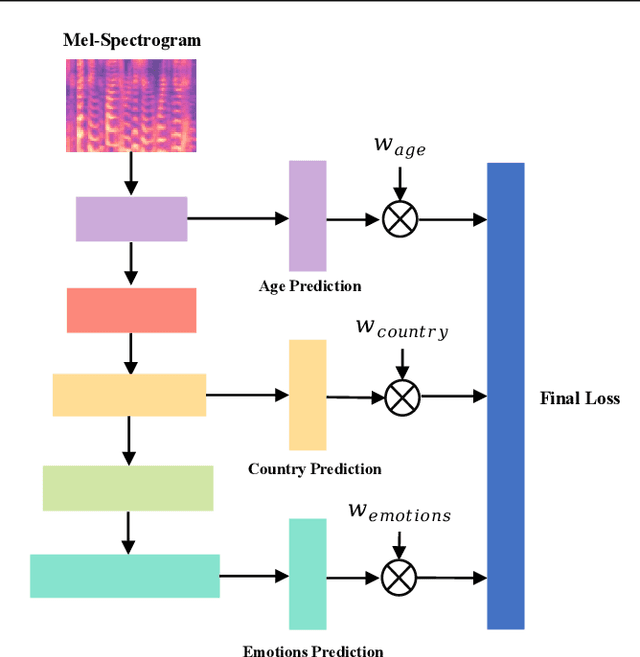
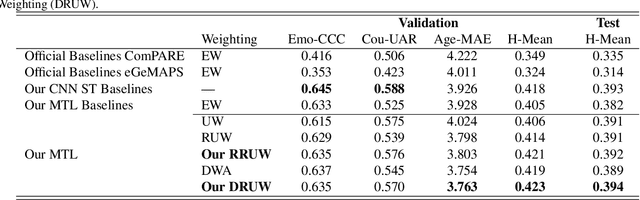
We propose a novel Dynamic Restrained Uncertainty Weighting Loss to experimentally handle the problem of balancing the contributions of multiple tasks on the ICML ExVo 2022 Challenge. The multitask aims to recognize expressed emotions and demographic traits from vocal bursts jointly. Our strategy combines the advantages of Uncertainty Weight and Dynamic Weight Average, by extending weights with a restraint term to make the learning process more explainable. We use a lightweight multi-exit CNN architecture to implement our proposed loss approach. The experimental H-Mean score (0.394) shows a substantial improvement over the baseline H-Mean score (0.335).
Continuous-Time Audiovisual Fusion with Recurrence vs. Attention for In-The-Wild Affect Recognition
Mar 29, 2022
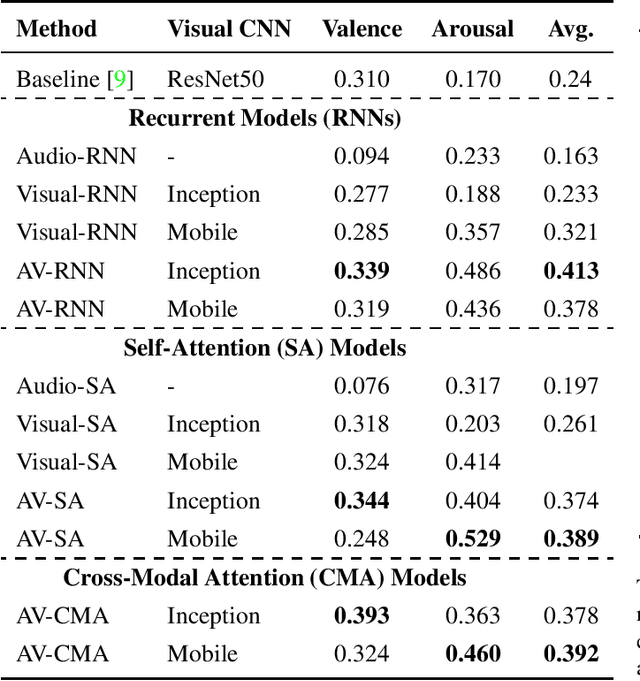
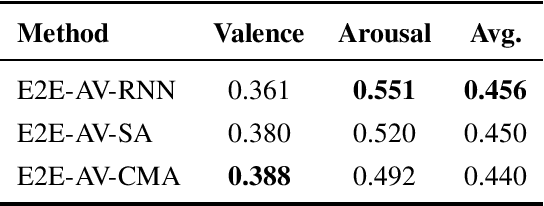
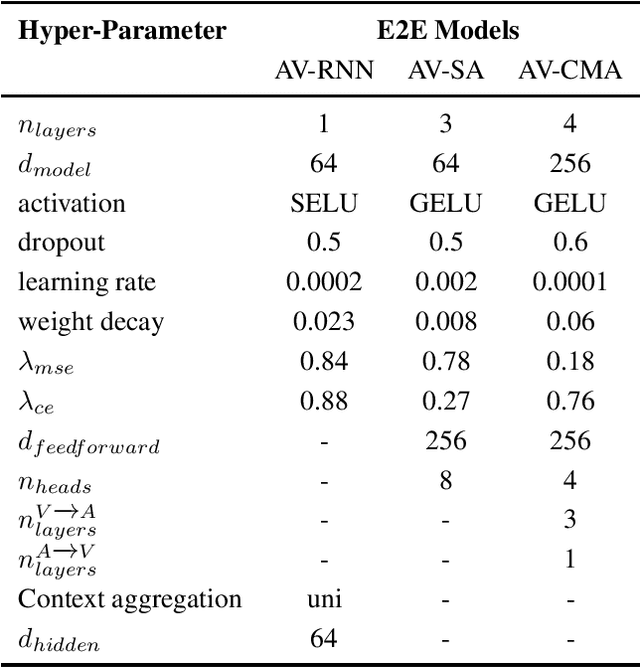
In this paper, we present our submission to 3rd Affective Behavior Analysis in-the-wild (ABAW) challenge. Learningcomplex interactions among multimodal sequences is critical to recognise dimensional affect from in-the-wild audiovisual data. Recurrence and attention are the two widely used sequence modelling mechanisms in the literature. To clearly understand the performance differences between recurrent and attention models in audiovisual affect recognition, we present a comprehensive evaluation of fusion models based on LSTM-RNNs, self-attention and cross-modal attention, trained for valence and arousal estimation. Particularly, we study the impact of some key design choices: the modelling complexity of CNN backbones that provide features to the the temporal models, with and without end-to-end learning. We trained the audiovisual affect recognition models on in-the-wild ABAW corpus by systematically tuning the hyper-parameters involved in the network architecture design and training optimisation. Our extensive evaluation of the audiovisual fusion models shows that LSTM-RNNs can outperform the attention models when coupled with low-complex CNN backbones and trained in an end-to-end fashion, implying that attention models may not necessarily be the optimal choice for continuous-time multimodal emotion recognition.
Go-CaRD -- Generic, Optical Car Part Recognition and Detection: Collection, Insights, and Applications
Jun 15, 2020
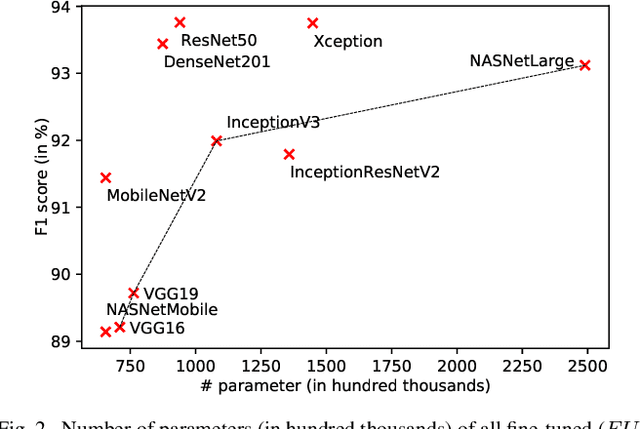

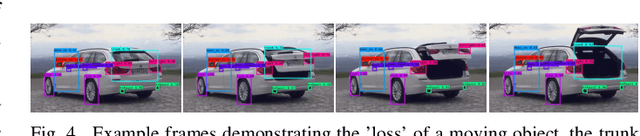
Systems for the automatic recognition and detection of automotive parts are crucial in several emerging research areas in the development of intelligent vehicles. They enable, for example, the detection and modelling of interactions between human and the vehicle. In this paper, we present three suitable datasets as well as quantitatively and qualitatively explore the efficacy of state-of-the-art deep learning architectures for the localisation of 29 interior and exterior vehicle regions, independent of brand, model, and environment. A ResNet50 model achieved an F1 score of 93.67 % for recognition, while our best Darknet model achieved an mAP of 58.20 % for detection. We also experiment with joint and transfer learning approaches and point out potential applications of our systems.
A Novel Fusion of Attention and Sequence to Sequence Autoencoders to Predict Sleepiness From Speech
May 19, 2020
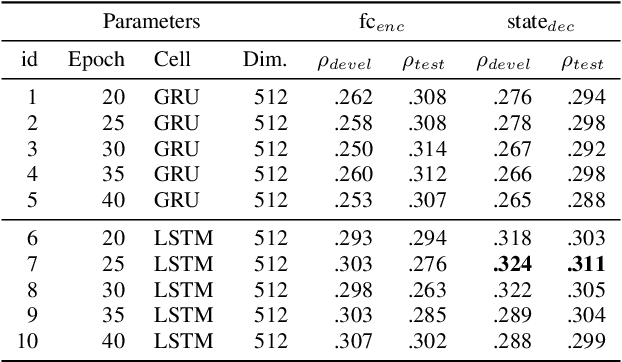
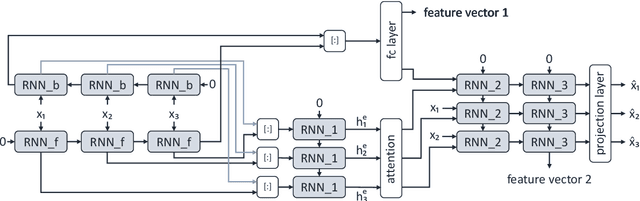
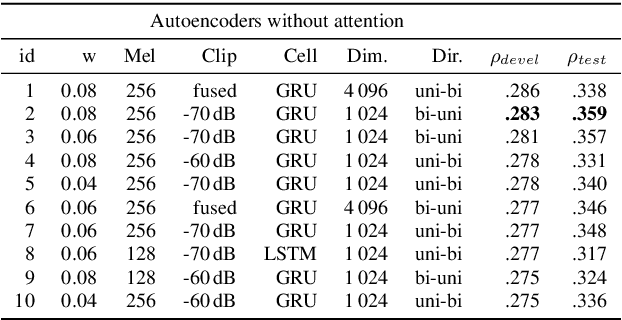
Motivated by the attention mechanism of the human visual system and recent developments in the field of machine translation, we introduce our attention-based and recurrent sequence to sequence autoencoders for fully unsupervised representation learning from audio files. In particular, we test the efficacy of our novel approach on the task of speech-based sleepiness recognition. We evaluate the learnt representations from both autoencoders, and then conduct an early fusion to ascertain possible complementarity between them. In our frameworks, we first extract Mel-spectrograms from raw audio files. Second, we train recurrent autoencoders on these spectrograms which are considered as time-dependent frequency vectors. Afterwards, we extract the activations of specific fully connected layers of the autoencoders which represent the learnt features of spectrograms for the corresponding audio instances. Finally, we train support vector regressors on these representations to obtain the predictions. On the development partition of the data, we achieve Spearman's correlation coefficients of .324, .283, and .320 with the targets on the Karolinska Sleepiness Scale by utilising attention and non-attention autoencoders, and the fusion of both autoencoders' representations, respectively. In the same order, we achieve .311, .359, and .367 Spearman's correlation coefficients on the test data, indicating the suitability of our proposed fusion strategy.