 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgexTrace: A Facial Expressive Behaviour Analysis Tool for Continuous Affect Recognition
May 08, 2025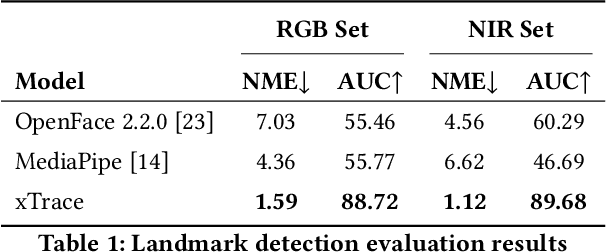
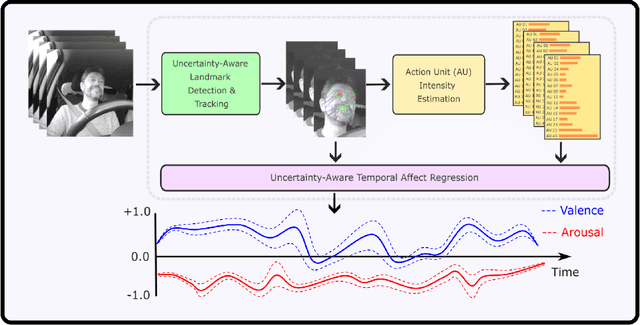

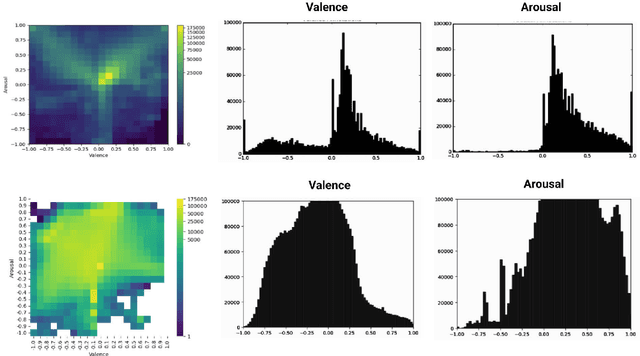
Recognising expressive behaviours in face videos is a long-standing challenge in Affective Computing. Despite significant advancements in recent years, it still remains a challenge to build a robust and reliable system for naturalistic and in-the-wild facial expressive behaviour analysis in real time. This paper addresses two key challenges in building such a system: (1). The paucity of large-scale labelled facial affect video datasets with extensive coverage of the 2D emotion space, and (2). The difficulty of extracting facial video features that are discriminative, interpretable, robust, and computationally efficient. Toward addressing these challenges, we introduce xTrace, a robust tool for facial expressive behaviour analysis and predicting continuous values of dimensional emotions, namely valence and arousal, from in-the-wild face videos. To address challenge (1), our affect recognition model is trained on the largest facial affect video data set, containing ~450k videos that cover most emotion zones in the dimensional emotion space, making xTrace highly versatile in analysing a wide spectrum of naturalistic expressive behaviours. To address challenge (2), xTrace uses facial affect descriptors that are not only explainable, but can also achieve a high degree of accuracy and robustness with low computational complexity. The key components of xTrace are benchmarked against three existing tools: MediaPipe, OpenFace, and Augsburg Affect Toolbox. On an in-the-wild validation set composed of 50k videos, xTrace achieves 0.86 mean CCC and 0.13 mean absolute error values. We present a detailed error analysis of affect predictions from xTrace, illustrating (a). its ability to recognise emotions with high accuracy across most bins in the 2D emotion space, (b). its robustness to non-frontal head pose angles, and (c). a strong correlation between its uncertainty estimates and its accuracy.
Are 3D Face Shapes Expressive Enough for Recognising Continuous Emotions and Action Unit Intensities?
Jul 03, 2022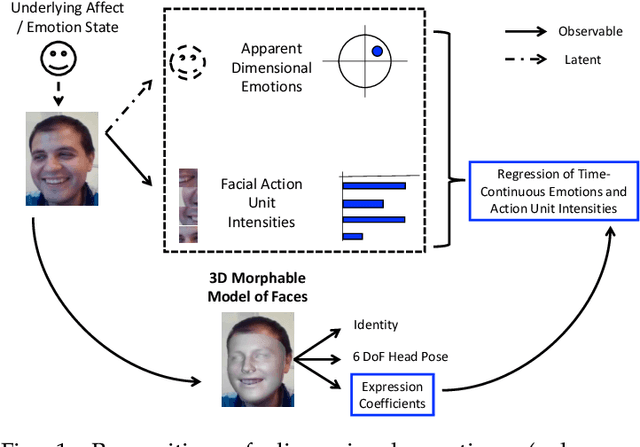
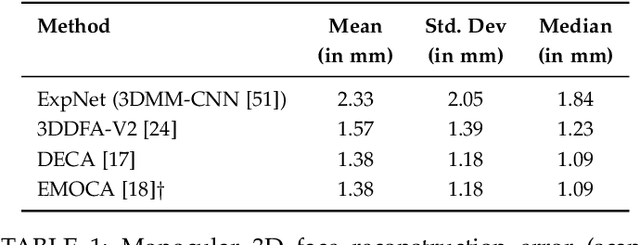
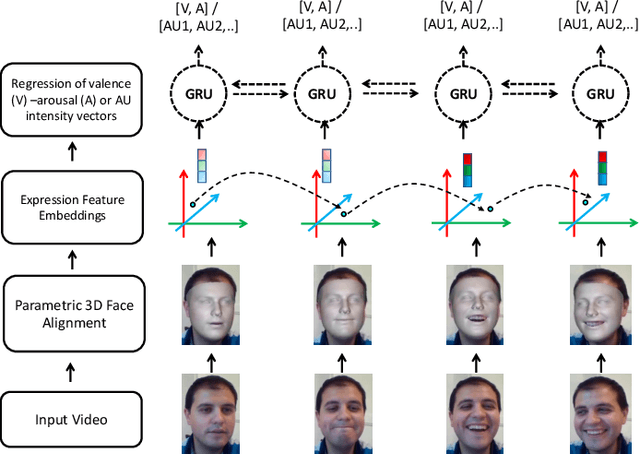
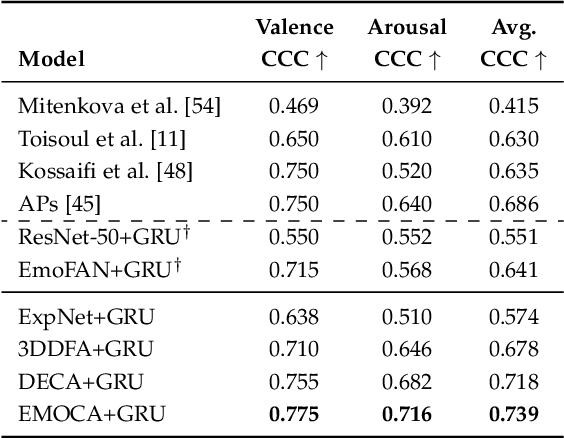
Recognising continuous emotions and action unit (AU) intensities from face videos requires a spatial and temporal understanding of expression dynamics. Existing works primarily rely on 2D face appearances to extract such dynamics. This work focuses on a promising alternative based on parametric 3D face shape alignment models, which disentangle different factors of variation, including expression-induced shape variations. We aim to understand how expressive 3D face shapes are in estimating valence-arousal and AU intensities compared to the state-of-the-art 2D appearance-based models. We benchmark four recent 3D face alignment models: ExpNet, 3DDFA-V2, DECA, and EMOCA. In valence-arousal estimation, expression features of 3D face models consistently surpassed previous works and yielded an average concordance correlation of .739 and .574 on SEWA and AVEC 2019 CES corpora, respectively. We also study how 3D face shapes performed on AU intensity estimation on BP4D and DISFA datasets, and report that 3D face features were on par with 2D appearance features in AUs 4, 6, 10, 12, and 25, but not the entire set of AUs. To understand this discrepancy, we conduct a correspondence analysis between valence-arousal and AUs, which points out that accurate prediction of valence-arousal may require the knowledge of only a few AUs.
COLD Fusion: Calibrated and Ordinal Latent Distribution Fusion for Uncertainty-Aware Multimodal Emotion Recognition
Jun 12, 2022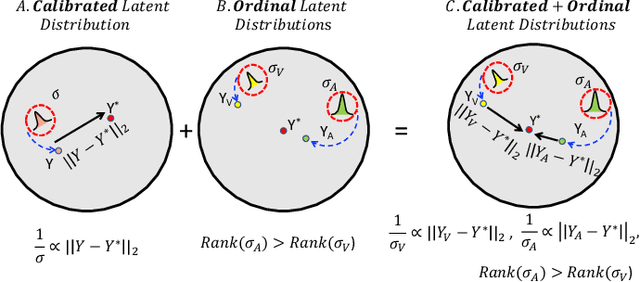

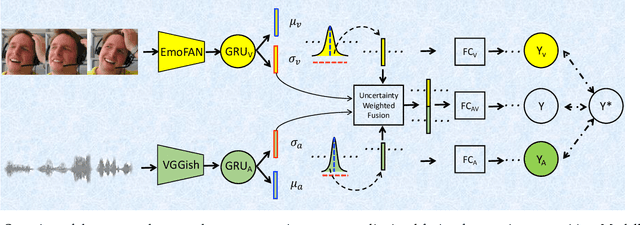

Automatically recognising apparent emotions from face and voice is hard, in part because of various sources of uncertainty, including in the input data and the labels used in a machine learning framework. This paper introduces an uncertainty-aware audiovisual fusion approach that quantifies modality-wise uncertainty towards emotion prediction. To this end, we propose a novel fusion framework in which we first learn latent distributions over audiovisual temporal context vectors separately, and then constrain the variance vectors of unimodal latent distributions so that they represent the amount of information each modality provides w.r.t. emotion recognition. In particular, we impose Calibration and Ordinal Ranking constraints on the variance vectors of audiovisual latent distributions. When well-calibrated, modality-wise uncertainty scores indicate how much their corresponding predictions may differ from the ground truth labels. Well-ranked uncertainty scores allow the ordinal ranking of different frames across the modalities. To jointly impose both these constraints, we propose a softmax distributional matching loss. In both classification and regression settings, we compare our uncertainty-aware fusion model with standard model-agnostic fusion baselines. Our evaluation on two emotion recognition corpora, AVEC 2019 CES and IEMOCAP, shows that audiovisual emotion recognition can considerably benefit from well-calibrated and well-ranked latent uncertainty measures.
Continuous-Time Audiovisual Fusion with Recurrence vs. Attention for In-The-Wild Affect Recognition
Mar 29, 2022
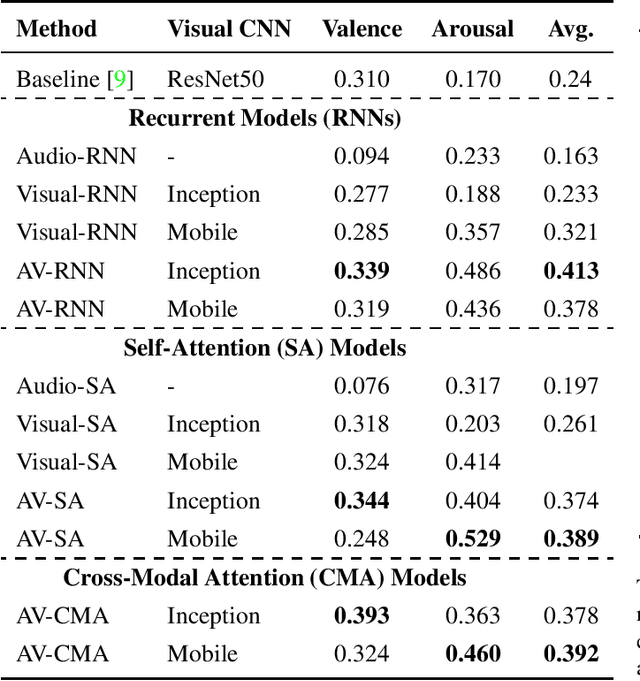
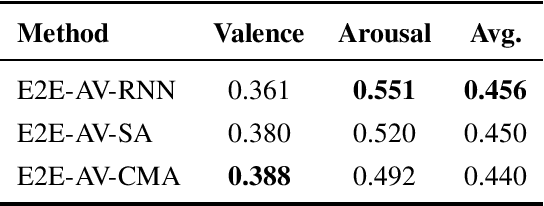
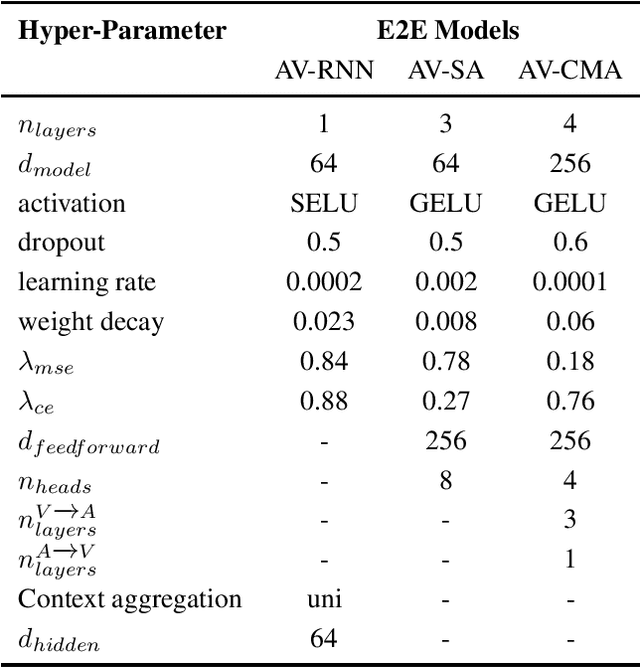
In this paper, we present our submission to 3rd Affective Behavior Analysis in-the-wild (ABAW) challenge. Learningcomplex interactions among multimodal sequences is critical to recognise dimensional affect from in-the-wild audiovisual data. Recurrence and attention are the two widely used sequence modelling mechanisms in the literature. To clearly understand the performance differences between recurrent and attention models in audiovisual affect recognition, we present a comprehensive evaluation of fusion models based on LSTM-RNNs, self-attention and cross-modal attention, trained for valence and arousal estimation. Particularly, we study the impact of some key design choices: the modelling complexity of CNN backbones that provide features to the the temporal models, with and without end-to-end learning. We trained the audiovisual affect recognition models on in-the-wild ABAW corpus by systematically tuning the hyper-parameters involved in the network architecture design and training optimisation. Our extensive evaluation of the audiovisual fusion models shows that LSTM-RNNs can outperform the attention models when coupled with low-complex CNN backbones and trained in an end-to-end fashion, implying that attention models may not necessarily be the optimal choice for continuous-time multimodal emotion recognition.
Affective Processes: stochastic modelling of temporal context for emotion and facial expression recognition
Mar 24, 2021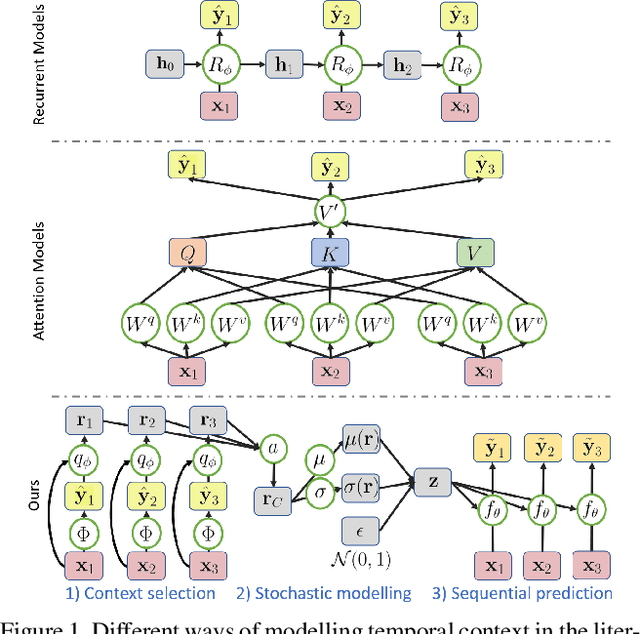
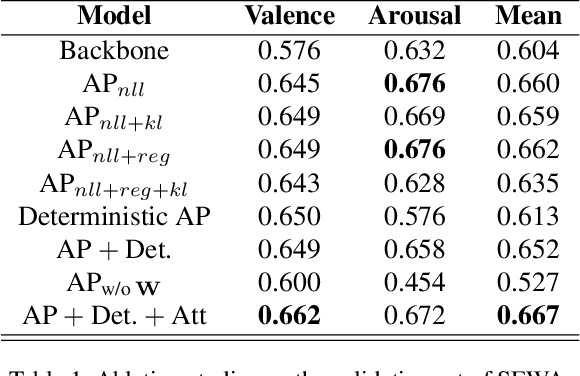
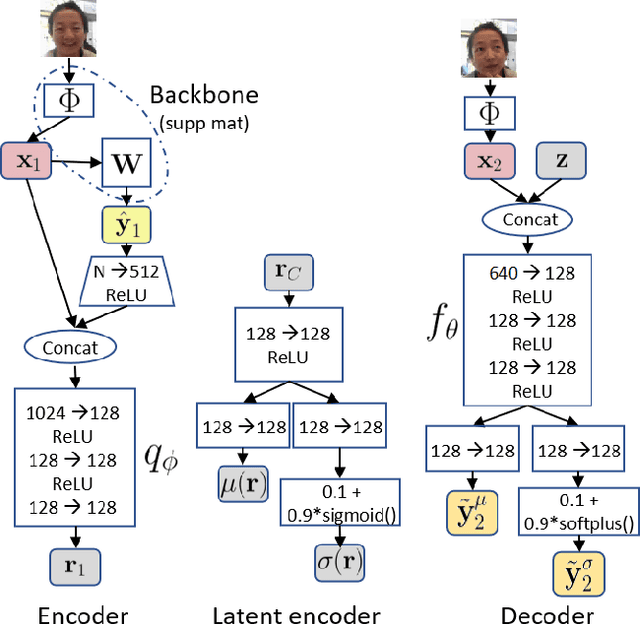

Temporal context is key to the recognition of expressions of emotion. Existing methods, that rely on recurrent or self-attention models to enforce temporal consistency, work on the feature level, ignoring the task-specific temporal dependencies, and fail to model context uncertainty. To alleviate these issues, we build upon the framework of Neural Processes to propose a method for apparent emotion recognition with three key novel components: (a) probabilistic contextual representation with a global latent variable model; (b) temporal context modelling using task-specific predictions in addition to features; and (c) smart temporal context selection. We validate our approach on four databases, two for Valence and Arousal estimation (SEWA and AffWild2), and two for Action Unit intensity estimation (DISFA and BP4D). Results show a consistent improvement over a series of strong baselines as well as over state-of-the-art methods.