 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre 3D Face Shapes Expressive Enough for Recognising Continuous Emotions and Action Unit Intensities?
Paper and Code
Jul 03, 2022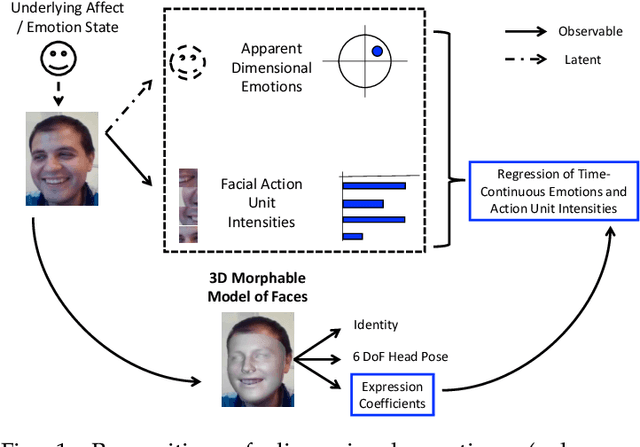
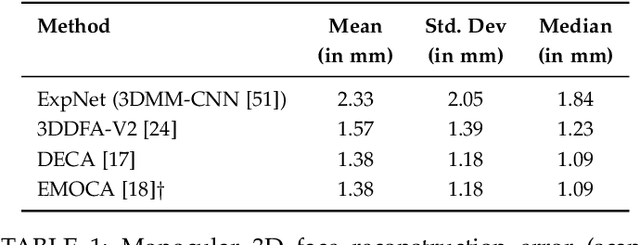
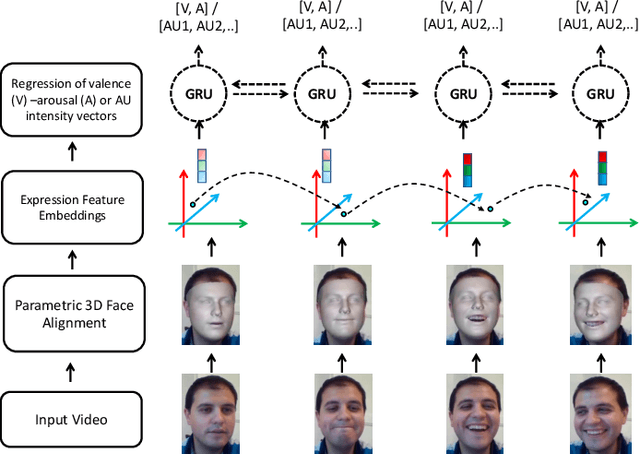
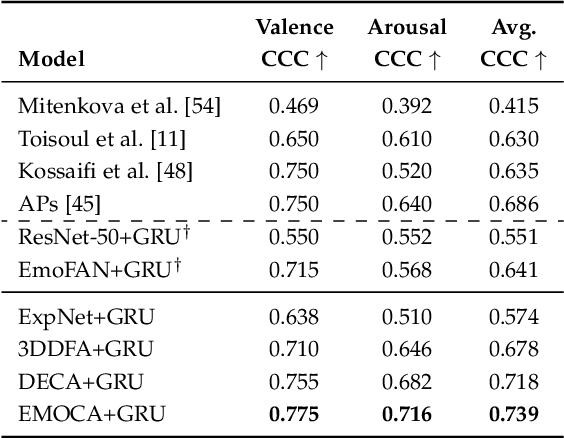
Recognising continuous emotions and action unit (AU) intensities from face videos requires a spatial and temporal understanding of expression dynamics. Existing works primarily rely on 2D face appearances to extract such dynamics. This work focuses on a promising alternative based on parametric 3D face shape alignment models, which disentangle different factors of variation, including expression-induced shape variations. We aim to understand how expressive 3D face shapes are in estimating valence-arousal and AU intensities compared to the state-of-the-art 2D appearance-based models. We benchmark four recent 3D face alignment models: ExpNet, 3DDFA-V2, DECA, and EMOCA. In valence-arousal estimation, expression features of 3D face models consistently surpassed previous works and yielded an average concordance correlation of .739 and .574 on SEWA and AVEC 2019 CES corpora, respectively. We also study how 3D face shapes performed on AU intensity estimation on BP4D and DISFA datasets, and report that 3D face features were on par with 2D appearance features in AUs 4, 6, 10, 12, and 25, but not the entire set of AUs. To understand this discrepancy, we conduct a correspondence analysis between valence-arousal and AUs, which points out that accurate prediction of valence-arousal may require the knowledge of only a few AUs.