 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre 3D Face Shapes Expressive Enough for Recognising Continuous Emotions and Action Unit Intensities?
Jul 03, 2022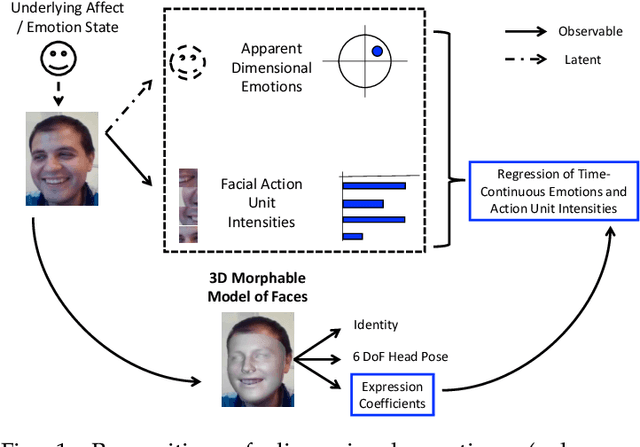
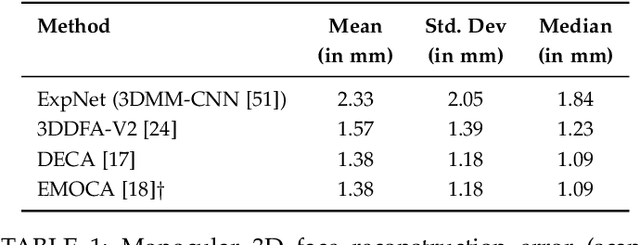
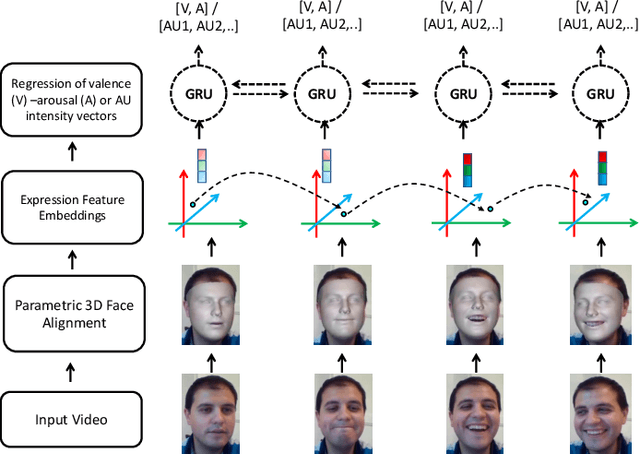
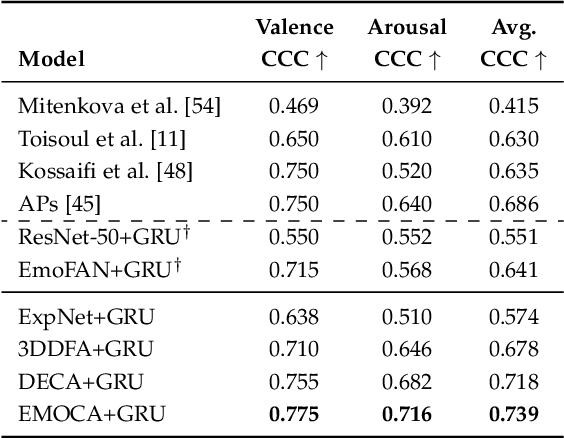
Recognising continuous emotions and action unit (AU) intensities from face videos requires a spatial and temporal understanding of expression dynamics. Existing works primarily rely on 2D face appearances to extract such dynamics. This work focuses on a promising alternative based on parametric 3D face shape alignment models, which disentangle different factors of variation, including expression-induced shape variations. We aim to understand how expressive 3D face shapes are in estimating valence-arousal and AU intensities compared to the state-of-the-art 2D appearance-based models. We benchmark four recent 3D face alignment models: ExpNet, 3DDFA-V2, DECA, and EMOCA. In valence-arousal estimation, expression features of 3D face models consistently surpassed previous works and yielded an average concordance correlation of .739 and .574 on SEWA and AVEC 2019 CES corpora, respectively. We also study how 3D face shapes performed on AU intensity estimation on BP4D and DISFA datasets, and report that 3D face features were on par with 2D appearance features in AUs 4, 6, 10, 12, and 25, but not the entire set of AUs. To understand this discrepancy, we conduct a correspondence analysis between valence-arousal and AUs, which points out that accurate prediction of valence-arousal may require the knowledge of only a few AUs.
COLD Fusion: Calibrated and Ordinal Latent Distribution Fusion for Uncertainty-Aware Multimodal Emotion Recognition
Jun 12, 2022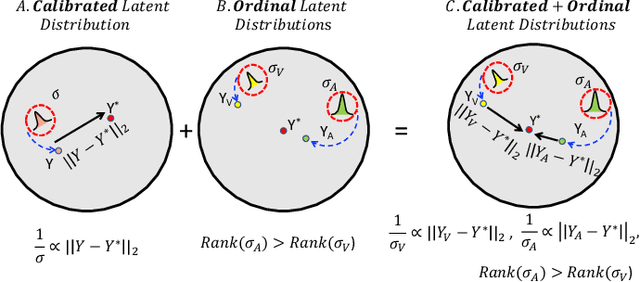

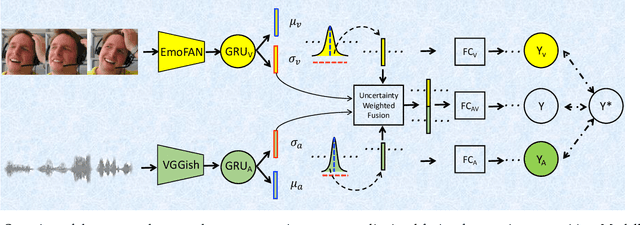

Automatically recognising apparent emotions from face and voice is hard, in part because of various sources of uncertainty, including in the input data and the labels used in a machine learning framework. This paper introduces an uncertainty-aware audiovisual fusion approach that quantifies modality-wise uncertainty towards emotion prediction. To this end, we propose a novel fusion framework in which we first learn latent distributions over audiovisual temporal context vectors separately, and then constrain the variance vectors of unimodal latent distributions so that they represent the amount of information each modality provides w.r.t. emotion recognition. In particular, we impose Calibration and Ordinal Ranking constraints on the variance vectors of audiovisual latent distributions. When well-calibrated, modality-wise uncertainty scores indicate how much their corresponding predictions may differ from the ground truth labels. Well-ranked uncertainty scores allow the ordinal ranking of different frames across the modalities. To jointly impose both these constraints, we propose a softmax distributional matching loss. In both classification and regression settings, we compare our uncertainty-aware fusion model with standard model-agnostic fusion baselines. Our evaluation on two emotion recognition corpora, AVEC 2019 CES and IEMOCAP, shows that audiovisual emotion recognition can considerably benefit from well-calibrated and well-ranked latent uncertainty measures.