 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREACT 2025: the Third Multiple Appropriate Facial Reaction Generation Challenge
May 22, 2025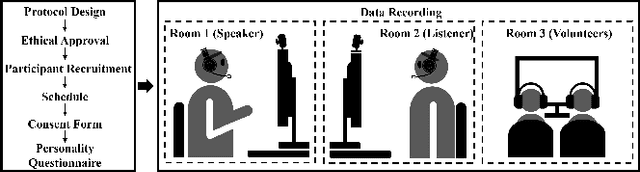

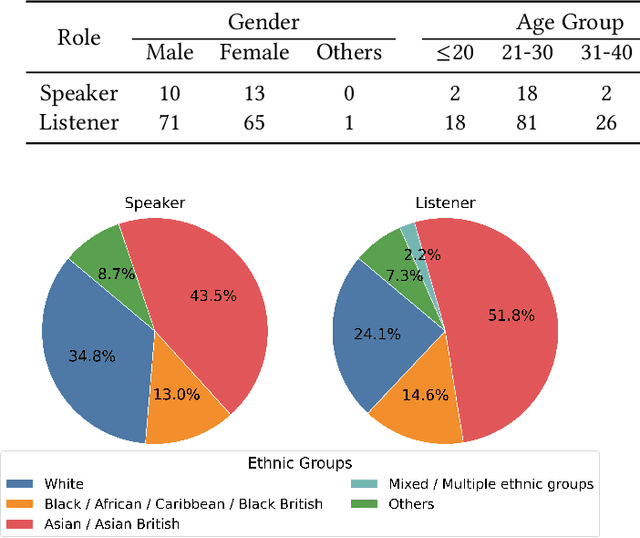
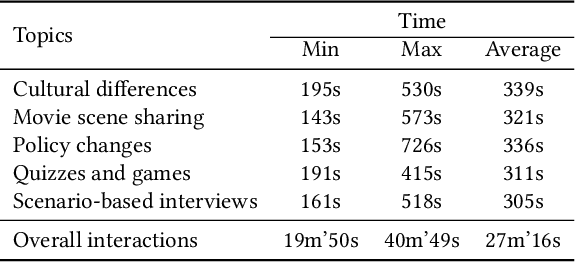
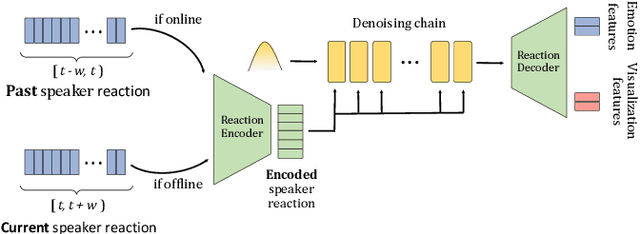
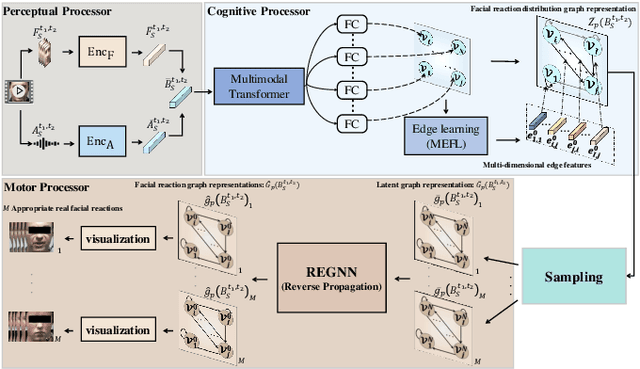
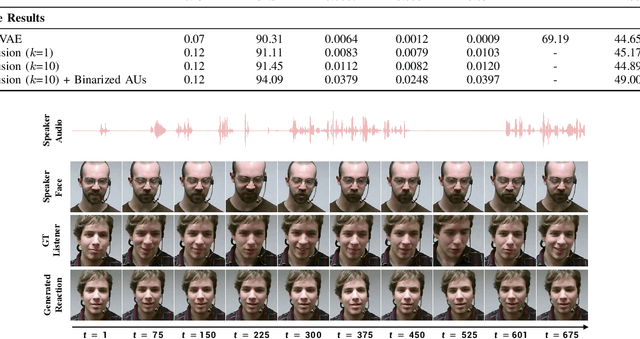
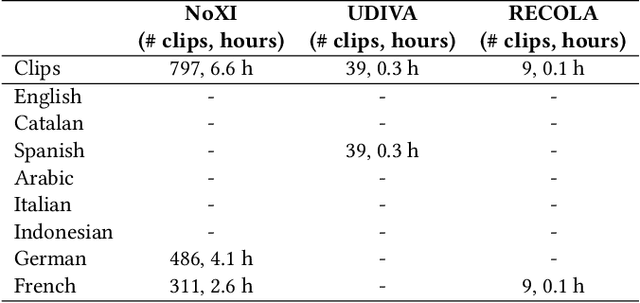
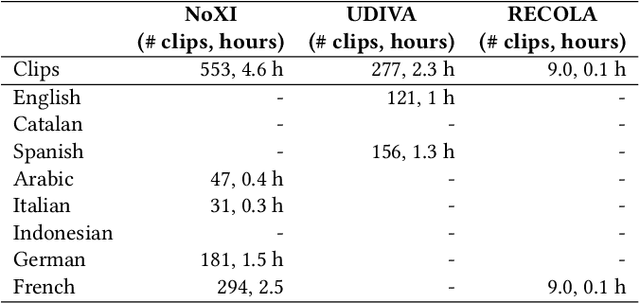
In dyadic interactions, a broad spectrum of human facial reactions might be appropriate for responding to each human speaker behaviour. Following the successful organisation of the REACT 2023 and REACT 2024 challenges, we are proposing the REACT 2025 challenge encouraging the development and benchmarking of Machine Learning (ML) models that can be used to generate multiple appropriate, diverse, realistic and synchronised human-style facial reactions expressed by human listeners in response to an input stimulus (i.e., audio-visual behaviours expressed by their corresponding speakers). As a key of the challenge, we provide challenge participants with the first natural and large-scale multi-modal MAFRG dataset (called MARS) recording 137 human-human dyadic interactions containing a total of 2856 interaction sessions covering five different topics. In addition, this paper also presents the challenge guidelines and the performance of our baselines on the two proposed sub-challenges: Offline MAFRG and Online MAFRG, respectively. The challenge baseline code is publicly available at https://github.com/reactmultimodalchallenge/baseline_react2025
xTrace: A Facial Expressive Behaviour Analysis Tool for Continuous Affect Recognition
May 08, 2025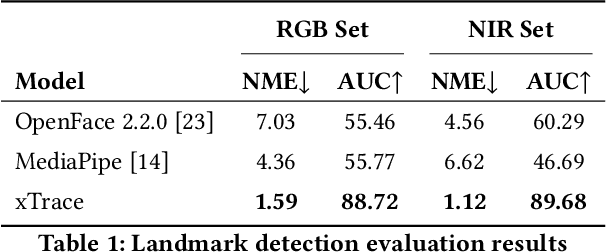
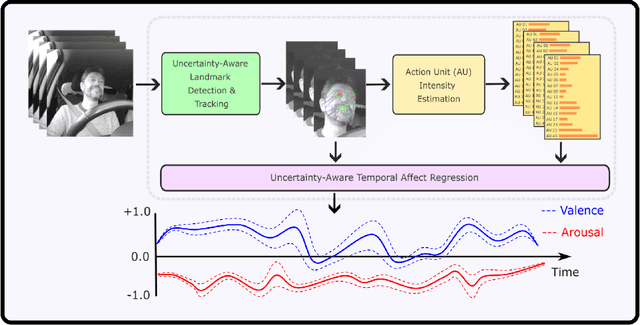

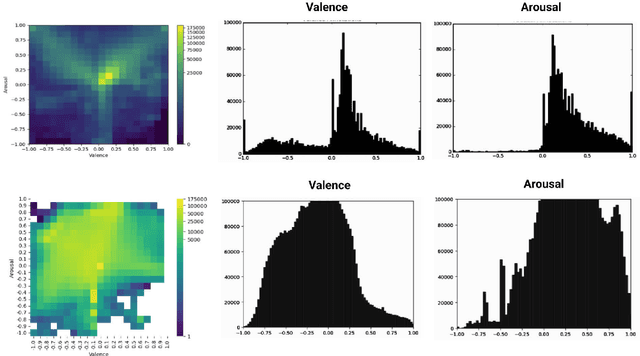
Recognising expressive behaviours in face videos is a long-standing challenge in Affective Computing. Despite significant advancements in recent years, it still remains a challenge to build a robust and reliable system for naturalistic and in-the-wild facial expressive behaviour analysis in real time. This paper addresses two key challenges in building such a system: (1). The paucity of large-scale labelled facial affect video datasets with extensive coverage of the 2D emotion space, and (2). The difficulty of extracting facial video features that are discriminative, interpretable, robust, and computationally efficient. Toward addressing these challenges, we introduce xTrace, a robust tool for facial expressive behaviour analysis and predicting continuous values of dimensional emotions, namely valence and arousal, from in-the-wild face videos. To address challenge (1), our affect recognition model is trained on the largest facial affect video data set, containing ~450k videos that cover most emotion zones in the dimensional emotion space, making xTrace highly versatile in analysing a wide spectrum of naturalistic expressive behaviours. To address challenge (2), xTrace uses facial affect descriptors that are not only explainable, but can also achieve a high degree of accuracy and robustness with low computational complexity. The key components of xTrace are benchmarked against three existing tools: MediaPipe, OpenFace, and Augsburg Affect Toolbox. On an in-the-wild validation set composed of 50k videos, xTrace achieves 0.86 mean CCC and 0.13 mean absolute error values. We present a detailed error analysis of affect predictions from xTrace, illustrating (a). its ability to recognise emotions with high accuracy across most bins in the 2D emotion space, (b). its robustness to non-frontal head pose angles, and (c). a strong correlation between its uncertainty estimates and its accuracy.
Human strategies for correcting `human-robot' errors during a laundry sorting task
Apr 11, 2025



Mental models and expectations underlying human-human interaction (HHI) inform human-robot interaction (HRI) with domestic robots. To ease collaborative home tasks by improving domestic robot speech and behaviours for human-robot communication, we designed a study to understand how people communicated when failure occurs. To identify patterns of natural communication, particularly in response to robotic failures, participants instructed Laundrobot to move laundry into baskets using natural language and gestures. Laundrobot either worked error-free, or in one of two error modes. Participants were not advised Laundrobot would be a human actor, nor given information about error modes. Video analysis from 42 participants found speech patterns, included laughter, verbal expressions, and filler words, such as ``oh'' and ``ok'', also, sequences of body movements, including touching one's own face, increased pointing with a static finger, and expressions of surprise. Common strategies deployed when errors occurred, included correcting and teaching, taking responsibility, and displays of frustration. The strength of reaction to errors diminished with exposure, possibly indicating acceptance or resignation. Some used strategies similar to those used to communicate with other technologies, such as smart assistants. An anthropomorphic robot may not be ideally suited to this kind of task. Laundrobot's appearance, morphology, voice, capabilities, and recovery strategies may have impacted how it was perceived. Some participants indicated Laundrobot's actual skills were not aligned with expectations; this made it difficult to know what to expect and how much Laundrobot understood. Expertise, personality, and cultural differences may affect responses, however these were not assessed.
REACT 2024: the Second Multiple Appropriate Facial Reaction Generation Challenge
Jan 10, 2024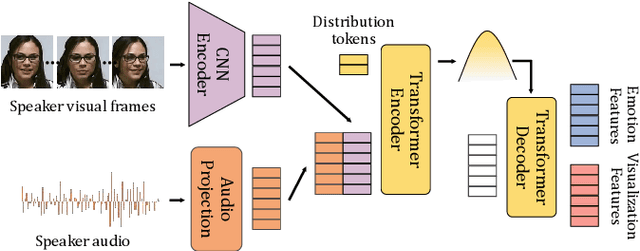
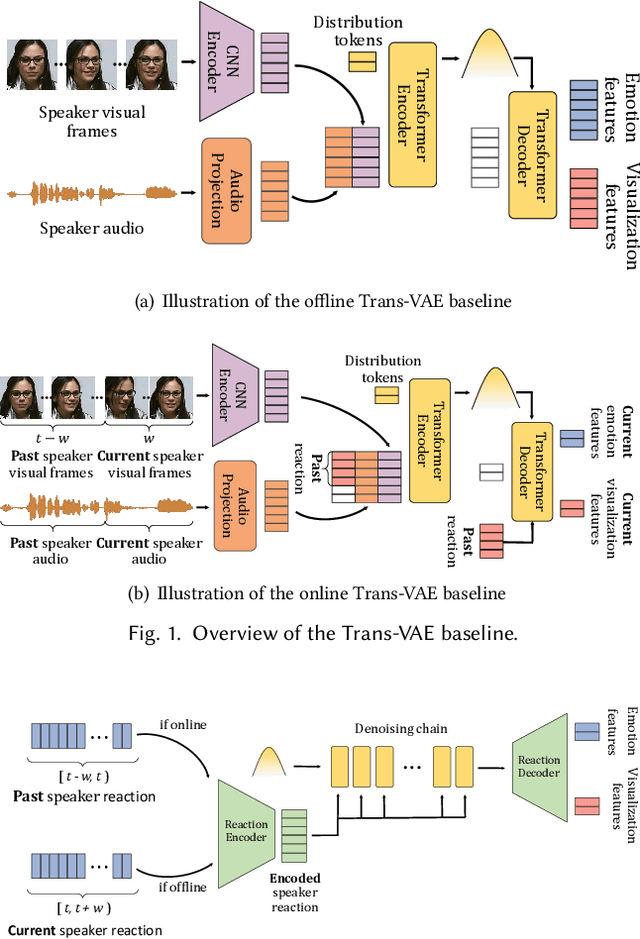
In dyadic interactions, humans communicate their intentions and state of mind using verbal and non-verbal cues, where multiple different facial reactions might be appropriate in response to a specific speaker behaviour. Then, how to develop a machine learning (ML) model that can automatically generate multiple appropriate, diverse, realistic and synchronised human facial reactions from an previously unseen speaker behaviour is a challenging task. Following the successful organisation of the first REACT challenge (REACT 2023), this edition of the challenge (REACT 2024) employs a subset used by the previous challenge, which contains segmented 30-secs dyadic interaction clips originally recorded as part of the NOXI and RECOLA datasets, encouraging participants to develop and benchmark Machine Learning (ML) models that can generate multiple appropriate facial reactions (including facial image sequences and their attributes) given an input conversational partner's stimulus under various dyadic video conference scenarios. This paper presents: (i) the guidelines of the REACT 2024 challenge; (ii) the dataset utilized in the challenge; and (iii) the performance of the baseline systems on the two proposed sub-challenges: Offline Multiple Appropriate Facial Reaction Generation and Online Multiple Appropriate Facial Reaction Generation, respectively. The challenge baseline code is publicly available at https://github.com/reactmultimodalchallenge/baseline_react2024.
REACT2023: the first Multi-modal Multiple Appropriate Facial Reaction Generation Challenge
Jun 11, 2023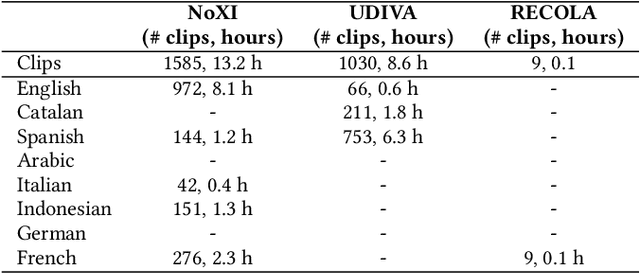
The Multi-modal Multiple Appropriate Facial Reaction Generation Challenge (REACT2023) is the first competition event focused on evaluating multimedia processing and machine learning techniques for generating human-appropriate facial reactions in various dyadic interaction scenarios, with all participants competing strictly under the same conditions. The goal of the challenge is to provide the first benchmark test set for multi-modal information processing and to foster collaboration among the audio, visual, and audio-visual affective computing communities, to compare the relative merits of the approaches to automatic appropriate facial reaction generation under different spontaneous dyadic interaction conditions. This paper presents: (i) novelties, contributions and guidelines of the REACT2023 challenge; (ii) the dataset utilized in the challenge; and (iii) the performance of baseline systems on the two proposed sub-challenges: Offline Multiple Appropriate Facial Reaction Generation and Online Multiple Appropriate Facial Reaction Generation, respectively. The challenge baseline code is publicly available at \url{https://github.com/reactmultimodalchallenge/baseline_react2023}.
Are 3D Face Shapes Expressive Enough for Recognising Continuous Emotions and Action Unit Intensities?
Jul 03, 2022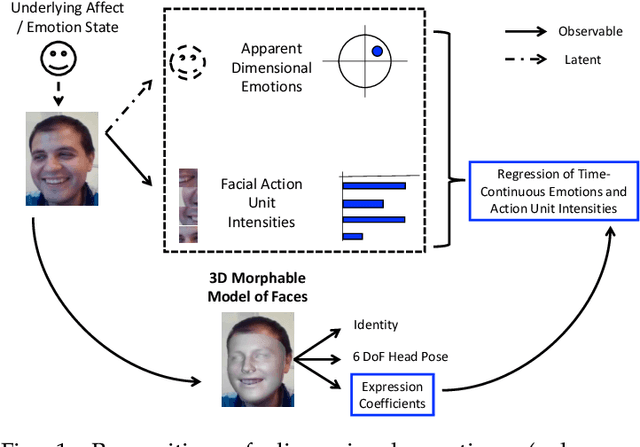
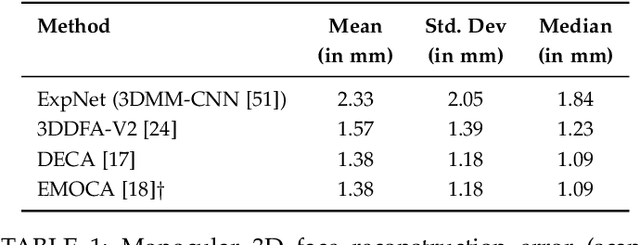
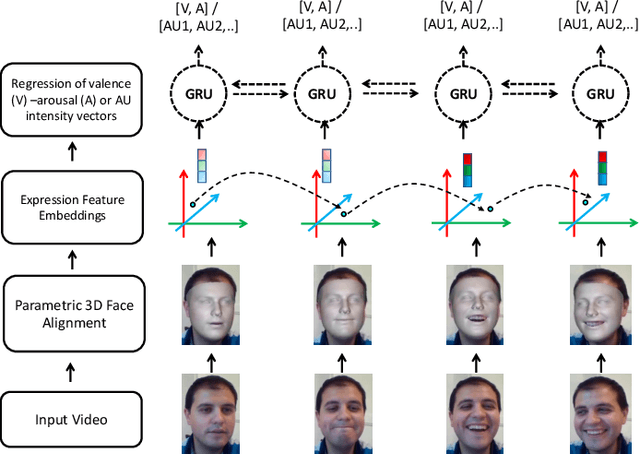
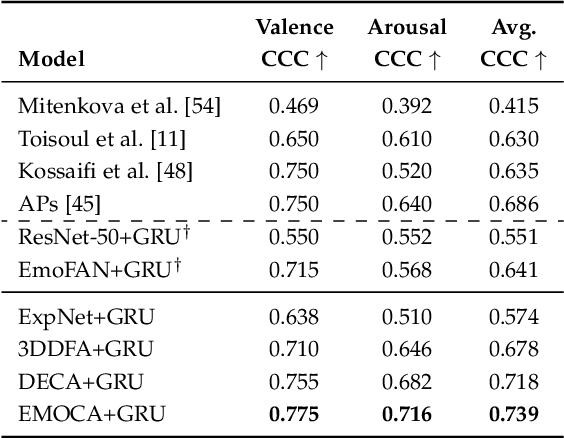
Recognising continuous emotions and action unit (AU) intensities from face videos requires a spatial and temporal understanding of expression dynamics. Existing works primarily rely on 2D face appearances to extract such dynamics. This work focuses on a promising alternative based on parametric 3D face shape alignment models, which disentangle different factors of variation, including expression-induced shape variations. We aim to understand how expressive 3D face shapes are in estimating valence-arousal and AU intensities compared to the state-of-the-art 2D appearance-based models. We benchmark four recent 3D face alignment models: ExpNet, 3DDFA-V2, DECA, and EMOCA. In valence-arousal estimation, expression features of 3D face models consistently surpassed previous works and yielded an average concordance correlation of .739 and .574 on SEWA and AVEC 2019 CES corpora, respectively. We also study how 3D face shapes performed on AU intensity estimation on BP4D and DISFA datasets, and report that 3D face features were on par with 2D appearance features in AUs 4, 6, 10, 12, and 25, but not the entire set of AUs. To understand this discrepancy, we conduct a correspondence analysis between valence-arousal and AUs, which points out that accurate prediction of valence-arousal may require the knowledge of only a few AUs.
COLD Fusion: Calibrated and Ordinal Latent Distribution Fusion for Uncertainty-Aware Multimodal Emotion Recognition
Jun 12, 2022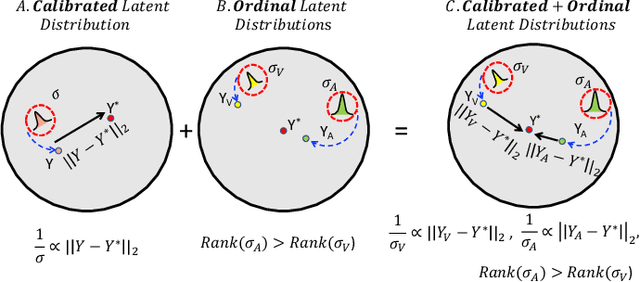

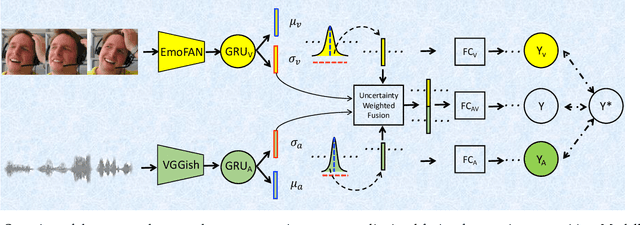

Automatically recognising apparent emotions from face and voice is hard, in part because of various sources of uncertainty, including in the input data and the labels used in a machine learning framework. This paper introduces an uncertainty-aware audiovisual fusion approach that quantifies modality-wise uncertainty towards emotion prediction. To this end, we propose a novel fusion framework in which we first learn latent distributions over audiovisual temporal context vectors separately, and then constrain the variance vectors of unimodal latent distributions so that they represent the amount of information each modality provides w.r.t. emotion recognition. In particular, we impose Calibration and Ordinal Ranking constraints on the variance vectors of audiovisual latent distributions. When well-calibrated, modality-wise uncertainty scores indicate how much their corresponding predictions may differ from the ground truth labels. Well-ranked uncertainty scores allow the ordinal ranking of different frames across the modalities. To jointly impose both these constraints, we propose a softmax distributional matching loss. In both classification and regression settings, we compare our uncertainty-aware fusion model with standard model-agnostic fusion baselines. Our evaluation on two emotion recognition corpora, AVEC 2019 CES and IEMOCAP, shows that audiovisual emotion recognition can considerably benefit from well-calibrated and well-ranked latent uncertainty measures.
Continuous-Time Audiovisual Fusion with Recurrence vs. Attention for In-The-Wild Affect Recognition
Mar 29, 2022
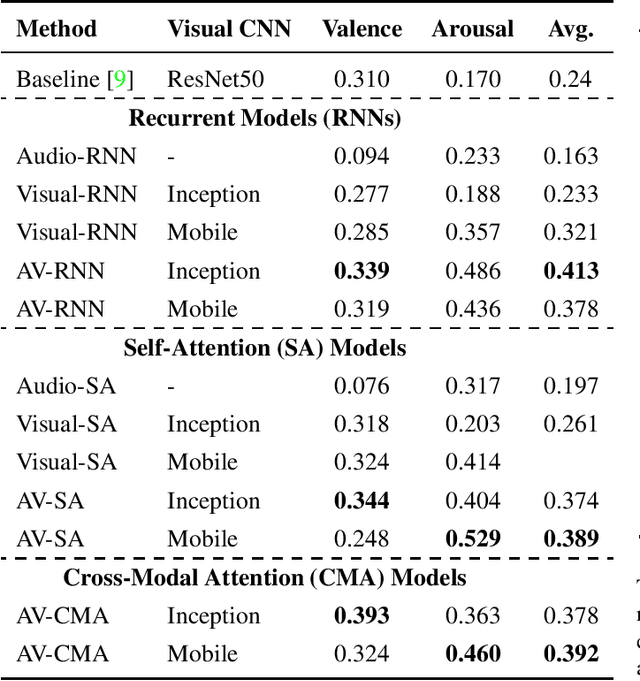
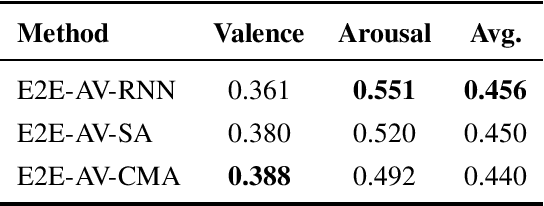
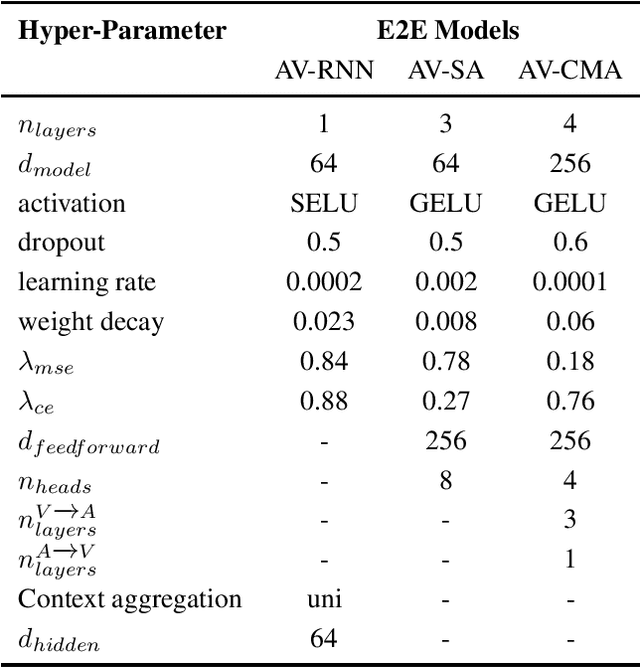
In this paper, we present our submission to 3rd Affective Behavior Analysis in-the-wild (ABAW) challenge. Learningcomplex interactions among multimodal sequences is critical to recognise dimensional affect from in-the-wild audiovisual data. Recurrence and attention are the two widely used sequence modelling mechanisms in the literature. To clearly understand the performance differences between recurrent and attention models in audiovisual affect recognition, we present a comprehensive evaluation of fusion models based on LSTM-RNNs, self-attention and cross-modal attention, trained for valence and arousal estimation. Particularly, we study the impact of some key design choices: the modelling complexity of CNN backbones that provide features to the the temporal models, with and without end-to-end learning. We trained the audiovisual affect recognition models on in-the-wild ABAW corpus by systematically tuning the hyper-parameters involved in the network architecture design and training optimisation. Our extensive evaluation of the audiovisual fusion models shows that LSTM-RNNs can outperform the attention models when coupled with low-complex CNN backbones and trained in an end-to-end fashion, implying that attention models may not necessarily be the optimal choice for continuous-time multimodal emotion recognition.
Two-stage Temporal Modelling Framework for Video-based Depression Recognition using Graph Representation
Nov 30, 2021

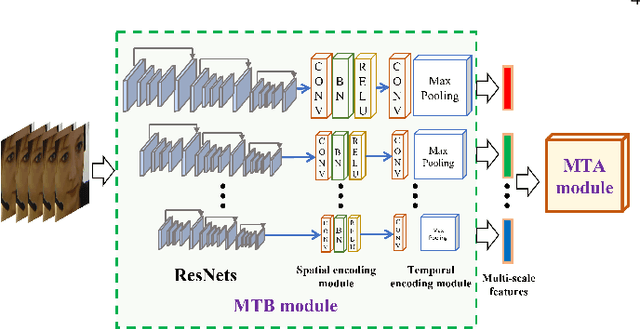

Video-based automatic depression analysis provides a fast, objective and repeatable self-assessment solution, which has been widely developed in recent years. While depression clues may be reflected by human facial behaviours of various temporal scales, most existing approaches either focused on modelling depression from short-term or video-level facial behaviours. In this sense, we propose a two-stage framework that models depression severity from multi-scale short-term and video-level facial behaviours. The short-term depressive behaviour modelling stage first deep learns depression-related facial behavioural features from multiple short temporal scales, where a Depression Feature Enhancement (DFE) module is proposed to enhance the depression-related clues for all temporal scales and remove non-depression noises. Then, the video-level depressive behaviour modelling stage proposes two novel graph encoding strategies, i.e., Sequential Graph Representation (SEG) and Spectral Graph Representation (SPG), to re-encode all short-term features of the target video into a video-level graph representation, summarizing depression-related multi-scale video-level temporal information. As a result, the produced graph representations predict depression severity using both short-term and long-term facial beahviour patterns. The experimental results on AVEC 2013 and AVEC 2014 datasets show that the proposed DFE module constantly enhanced the depression severity estimation performance for various CNN models while the SPG is superior than other video-level modelling methods. More importantly, the result achieved for the proposed two-stage framework shows its promising and solid performance compared to widely-used one-stage modelling approaches.
Learning Graph Representation of Person-specific Cognitive Processes from Audio-visual Behaviours for Automatic Personality Recognition
Oct 27, 2021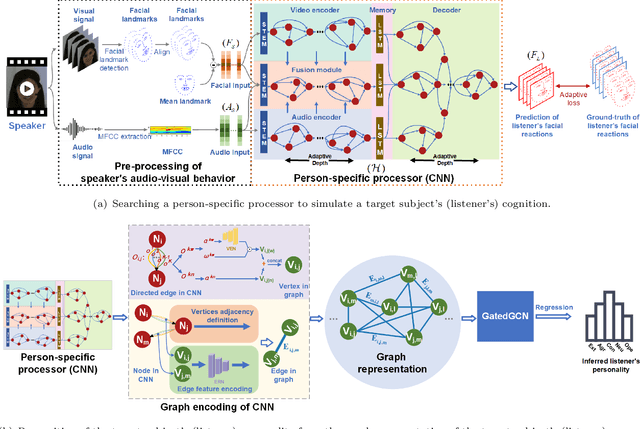
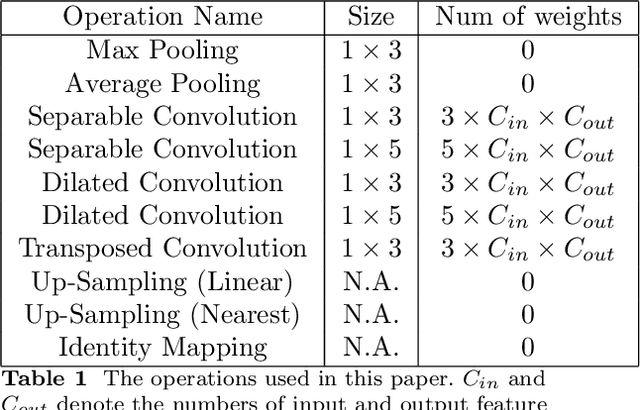
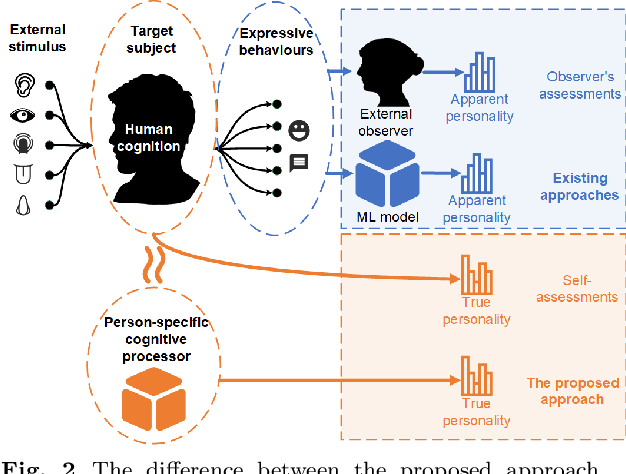
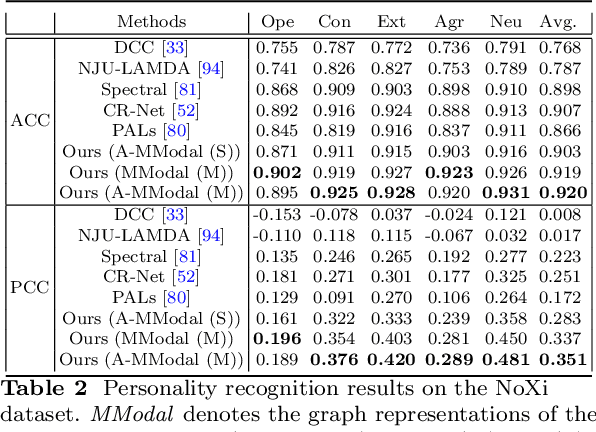
This approach builds on two following findings in cognitive science: (i) human cognition partially determines expressed behaviour and is directly linked to true personality traits; and (ii) in dyadic interactions individuals' nonverbal behaviours are influenced by their conversational partner behaviours. In this context, we hypothesise that during a dyadic interaction, a target subject's facial reactions are driven by two main factors, i.e. their internal (person-specific) cognitive process, and the externalised nonverbal behaviours of their conversational partner. Consequently, we propose to represent the target subjects (defined as the listener) person-specific cognition in the form of a person-specific CNN architecture that has unique architectural parameters and depth, which takes audio-visual non-verbal cues displayed by the conversational partner (defined as the speaker) as input, and is able to reproduce the target subject's facial reactions. Each person-specific CNN is explored by the Neural Architecture Search (NAS) and a novel adaptive loss function, which is then represented as a graph representation for recognising the target subject's true personality. Experimental results not only show that the produced graph representations are well associated with target subjects' personality traits in both human-human and human-machine interaction scenarios, and outperform the existing approaches with significant advantages, but also demonstrate that the proposed novel strategies such as adaptive loss, and the end-to-end vertices/edges feature learning, help the proposed approach in learning more reliable personality representations.