 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman strategies for correcting `human-robot' errors during a laundry sorting task
Apr 11, 2025



Mental models and expectations underlying human-human interaction (HHI) inform human-robot interaction (HRI) with domestic robots. To ease collaborative home tasks by improving domestic robot speech and behaviours for human-robot communication, we designed a study to understand how people communicated when failure occurs. To identify patterns of natural communication, particularly in response to robotic failures, participants instructed Laundrobot to move laundry into baskets using natural language and gestures. Laundrobot either worked error-free, or in one of two error modes. Participants were not advised Laundrobot would be a human actor, nor given information about error modes. Video analysis from 42 participants found speech patterns, included laughter, verbal expressions, and filler words, such as ``oh'' and ``ok'', also, sequences of body movements, including touching one's own face, increased pointing with a static finger, and expressions of surprise. Common strategies deployed when errors occurred, included correcting and teaching, taking responsibility, and displays of frustration. The strength of reaction to errors diminished with exposure, possibly indicating acceptance or resignation. Some used strategies similar to those used to communicate with other technologies, such as smart assistants. An anthropomorphic robot may not be ideally suited to this kind of task. Laundrobot's appearance, morphology, voice, capabilities, and recovery strategies may have impacted how it was perceived. Some participants indicated Laundrobot's actual skills were not aligned with expectations; this made it difficult to know what to expect and how much Laundrobot understood. Expertise, personality, and cultural differences may affect responses, however these were not assessed.
CzSL: A new learning paradigm for astronomical image classification with citizen science
Feb 01, 2023
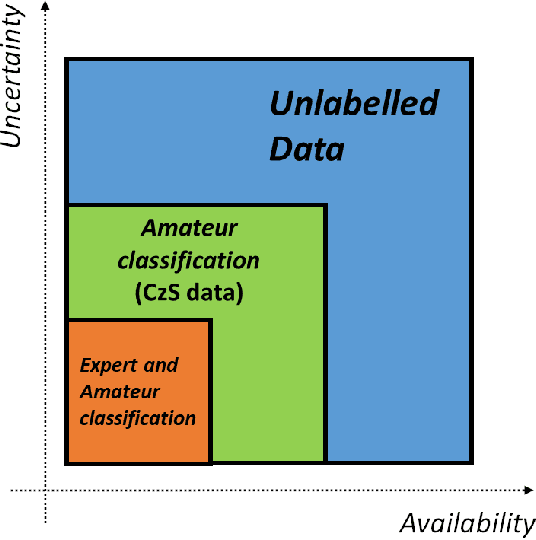

Citizen science is gaining popularity as a valuable tool for labelling large collections of astronomical images by the general public. This is often achieved at the cost of poorer quality classifications made by amateur participants, which are usually verified by employing smaller data sets labelled by professional astronomers. Despite its success, citizen science alone will not be able to handle the classification of current and upcoming surveys. To alleviate this issue, citizen science projects have been coupled with machine learning techniques in pursuit of a more robust automated classification. However, existing approaches have neglected the fact that, apart from the data labelled by amateurs, (limited) expert knowledge of the problem is also available along with vast amounts of unlabelled data that have not yet been exploited within a unified learning framework. This paper presents an innovative learning paradigm for citizen science capable of taking advantage of expert- and amateur-labelled data, and unlabelled data. The proposed methodology first learns from unlabelled data with a convolutional autoencoder and then exploits amateur and expert labels via the pre-training and fine-tuning of a convolutional neural network, respectively. We focus on the classification of galaxy images from the Galaxy Zoo project, from which we test binary, multi-class, and imbalanced classification scenarios. The results demonstrate that our solution is able to improve classification performance compared to a set of baseline approaches, deploying a promising methodology for learning from different confidence levels in data labelling.
EFI: A Toolbox for Feature Importance Fusion and Interpretation in Python
Aug 08, 2022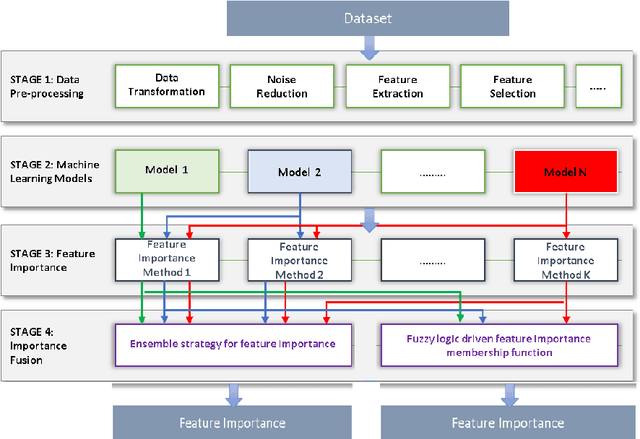
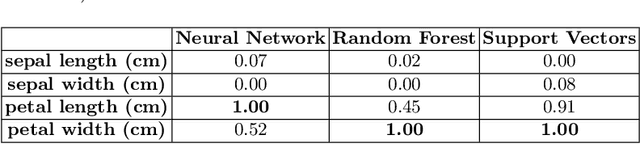
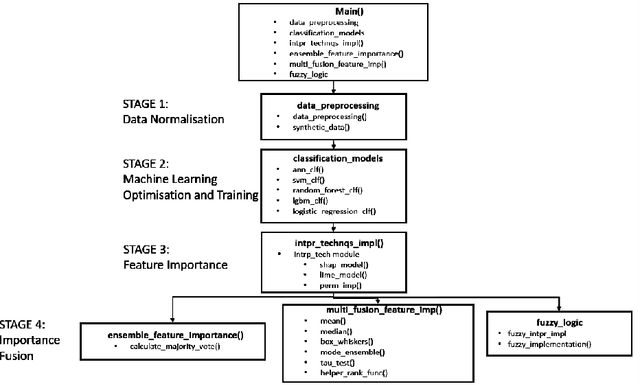

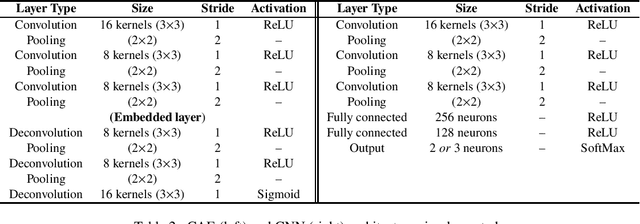
This paper presents an open-source Python toolbox called Ensemble Feature Importance (EFI) to provide machine learning (ML) researchers, domain experts, and decision makers with robust and accurate feature importance quantification and more reliable mechanistic interpretation of feature importance for prediction problems using fuzzy sets. The toolkit was developed to address uncertainties in feature importance quantification and lack of trustworthy feature importance interpretation due to the diverse availability of machine learning algorithms, feature importance calculation methods, and dataset dependencies. EFI merges results from multiple machine learning models with different feature importance calculation approaches using data bootstrapping and decision fusion techniques, such as mean, majority voting and fuzzy logic. The main attributes of the EFI toolbox are: (i) automatic optimisation of ML algorithms, (ii) automatic computation of a set of feature importance coefficients from optimised ML algorithms and feature importance calculation techniques, (iii) automatic aggregation of importance coefficients using multiple decision fusion techniques, and (iv) fuzzy membership functions that show the importance of each feature to the prediction task. The key modules and functions of the toolbox are described, and a simple example of their application is presented using the popular Iris dataset.
Contextual Intelligent Decisions: Expert Moderation of Machine Outputs for Fair Assessment of Commercial Driving
Feb 20, 2022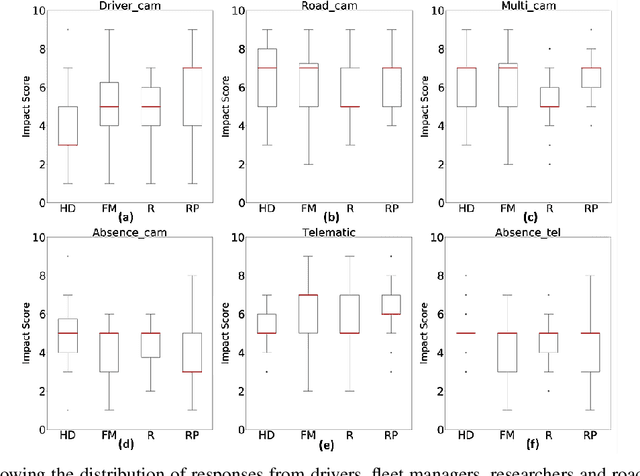
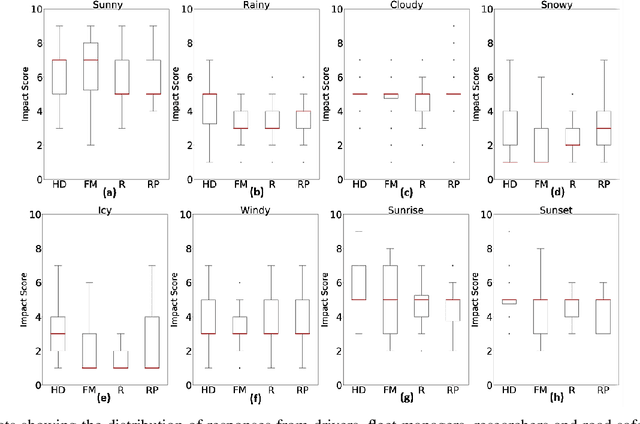

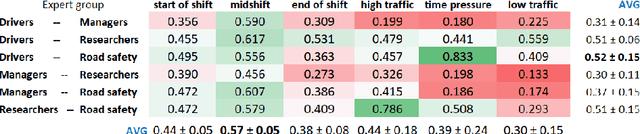
Commercial driving is a complex multifaceted task influenced by personal traits and external contextual factors, such as weather, traffic, road conditions, etc. Previous intelligent commercial driver-assessment systems do not consider these factors when analysing the impact of driving behaviours on road safety, potentially producing biased, inaccurate, and unfair assessments. In this paper, we introduce a methodology (Expert-centered Driver Assessment) towards a fairer automatic road safety assessment of drivers' behaviours, taking into consideration behaviours as a response to contextual factors. The contextual moderation embedded within the intelligent decision-making process is underpinned by expert input, comprising of a range of associated stakeholders in the industry. Guided by the literature and expert input, we identify critical factors affecting driving and develop an interval-valued response-format questionnaire to capture the uncertainty of the influence of factors and variance amongst experts' views. Questionnaire data are modelled and analysed using fuzzy sets, as they provide a suitable computational approach to be incorporated into decision-making systems with uncertainty. The methodology has allowed us to identify the factors that need to be considered when moderating driver sensor data, and to effectively capture experts' opinions about the effects of the factors. An example of our methodology using Heavy Goods Vehicles professionals input is provided to demonstrate how the expert-centred moderation can be embedded in intelligent driver assessment systems.
Towards Privacy-Preserving Affect Recognition: A Two-Level Deep Learning Architecture
Nov 14, 2021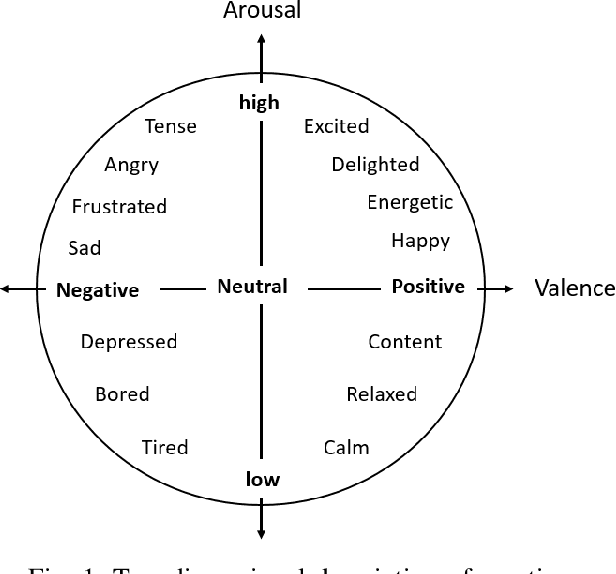
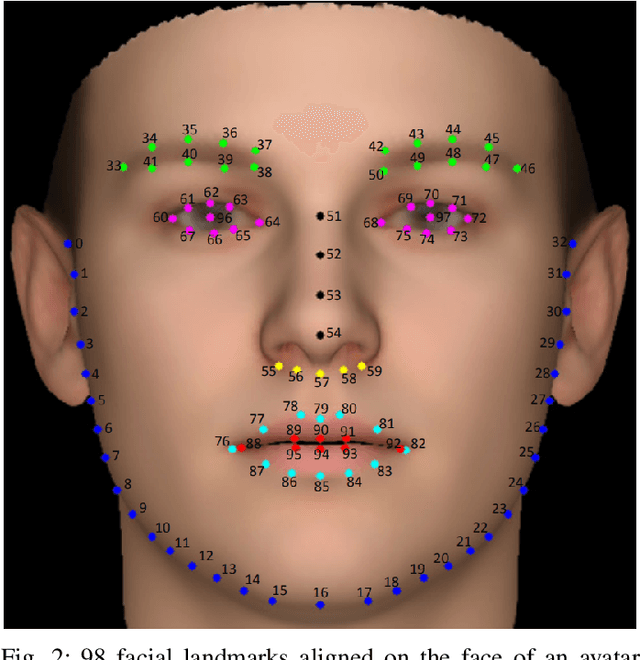
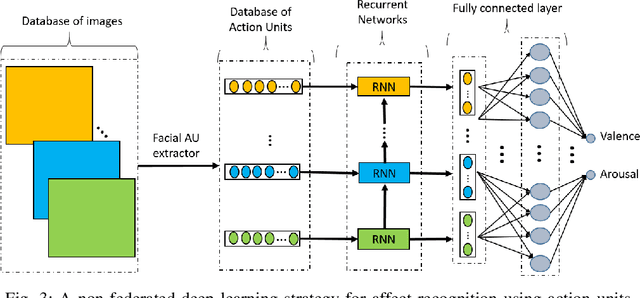
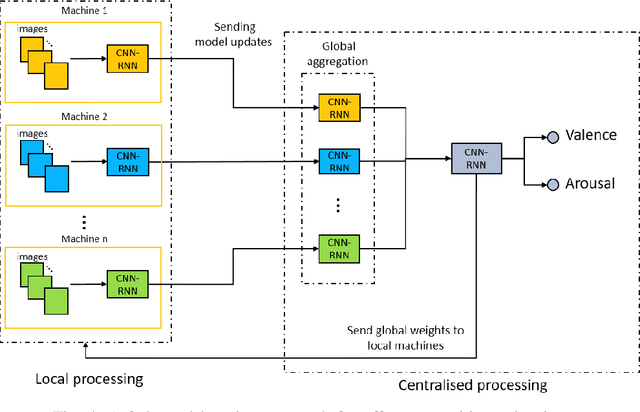
Automatically understanding and recognising human affective states using images and computer vision can improve human-computer and human-robot interaction. However, privacy has become an issue of great concern, as the identities of people used to train affective models can be exposed in the process. For instance, malicious individuals could exploit images from users and assume their identities. In addition, affect recognition using images can lead to discriminatory and algorithmic bias, as certain information such as race, gender, and age could be assumed based on facial features. Possible solutions to protect the privacy of users and avoid misuse of their identities are to: (1) extract anonymised facial features, namely action units (AU) from a database of images, discard the images and use AUs for processing and training, and (2) federated learning (FL) i.e. process raw images in users' local machines (local processing) and send the locally trained models to the main processing machine for aggregation (central processing). In this paper, we propose a two-level deep learning architecture for affect recognition that uses AUs in level 1 and FL in level 2 to protect users' identities. The architecture consists of recurrent neural networks to capture the temporal relationships amongst the features and predict valence and arousal affective states. In our experiments, we evaluate the performance of our privacy-preserving architecture using different variations of recurrent neural networks on RECOLA, a comprehensive multimodal affective database. Our results show state-of-the-art performance of $0.426$ for valence and $0.401$ for arousal using the Concordance Correlation Coefficient evaluation metric, demonstrating the feasibility of developing models for affect recognition that are both accurate and ensure privacy.
Mechanistic Interpretation of Machine Learning Inference: A Fuzzy Feature Importance Fusion Approach
Oct 22, 2021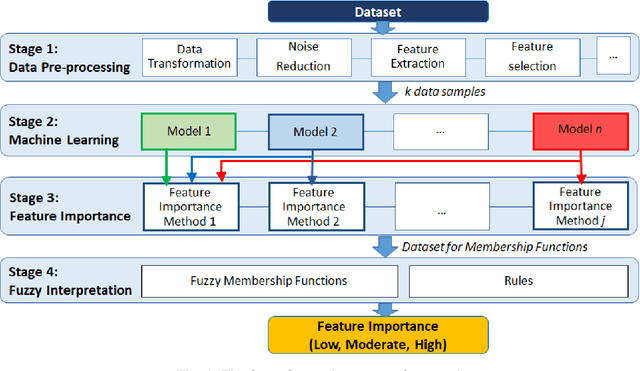
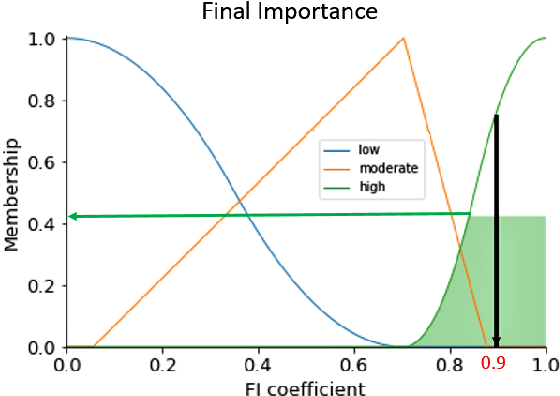
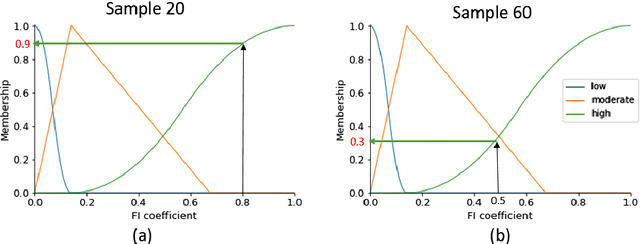
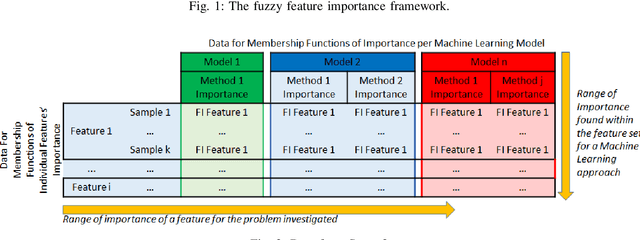
With the widespread use of machine learning to support decision-making, it is increasingly important to verify and understand the reasons why a particular output is produced. Although post-training feature importance approaches assist this interpretation, there is an overall lack of consensus regarding how feature importance should be quantified, making explanations of model predictions unreliable. In addition, many of these explanations depend on the specific machine learning approach employed and on the subset of data used when calculating feature importance. A possible solution to improve the reliability of explanations is to combine results from multiple feature importance quantifiers from different machine learning approaches coupled with re-sampling. Current state-of-the-art ensemble feature importance fusion uses crisp techniques to fuse results from different approaches. There is, however, significant loss of information as these approaches are not context-aware and reduce several quantifiers to a single crisp output. More importantly, their representation of 'importance' as coefficients is misleading and incomprehensible to end-users and decision makers. Here we show how the use of fuzzy data fusion methods can overcome some of the important limitations of crisp fusion methods.
L2AE-D: Learning to Aggregate Embeddings for Few-shot Learning with Meta-level Dropout
Apr 08, 2019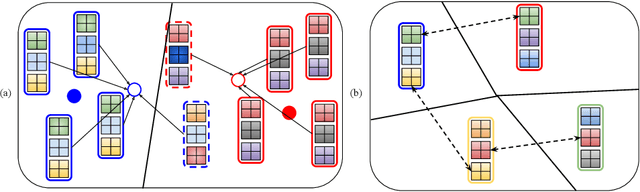
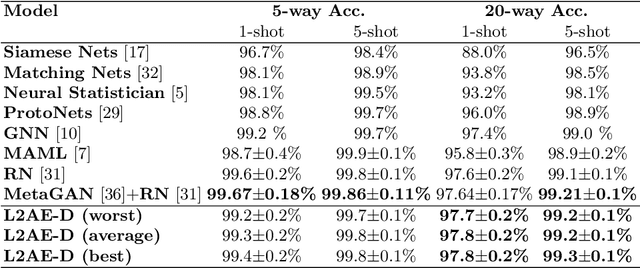
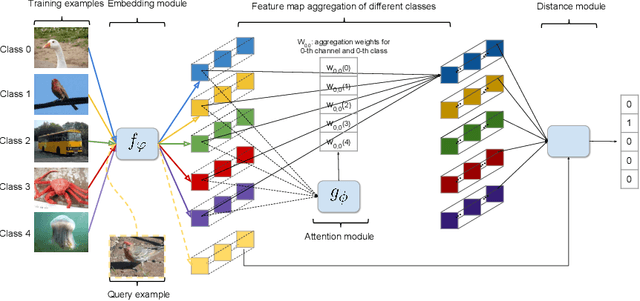
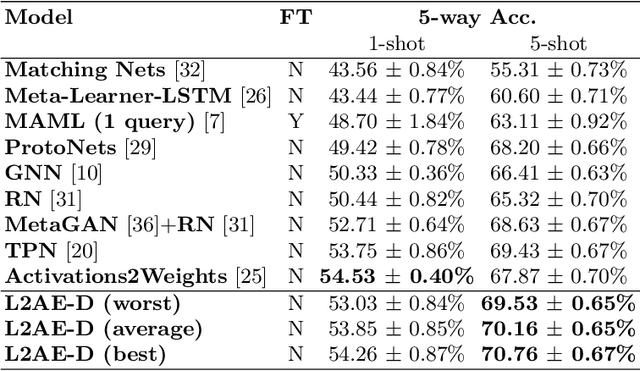
Few-shot learning focuses on learning a new visual concept with very limited labelled examples. A successful approach to tackle this problem is to compare the similarity between examples in a learned metric space based on convolutional neural networks. However, existing methods typically suffer from meta-level overfitting due to the limited amount of training tasks and do not normally consider the importance of the convolutional features of different examples within the same channel. To address these limitations, we make the following two contributions: (a) We propose a novel meta-learning approach for aggregating useful convolutional features and suppressing noisy ones based on a channel-wise attention mechanism to improve class representations. The proposed model does not require fine-tuning and can be trained in an end-to-end manner. The main novelty lies in incorporating a shared weight generation module that learns to assign different weights to the feature maps of different examples within the same channel. (b) We also introduce a simple meta-level dropout technique that reduces meta-level overfitting in several few-shot learning approaches. In our experiments, we find that this simple technique significantly improves the performance of the proposed method as well as various state-of-the-art meta-learning algorithms. Applying our method to few-shot image recognition using Omniglot and miniImageNet datasets shows that it is capable of delivering a state-of-the-art classification performance.
AVEC 2016 - Depression, Mood, and Emotion Recognition Workshop and Challenge
Nov 22, 2016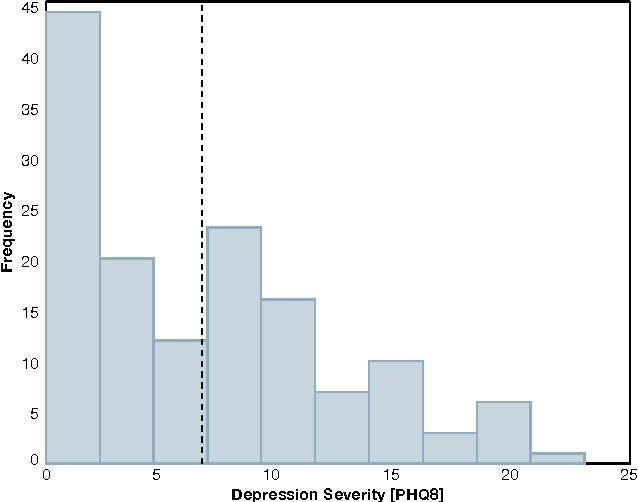
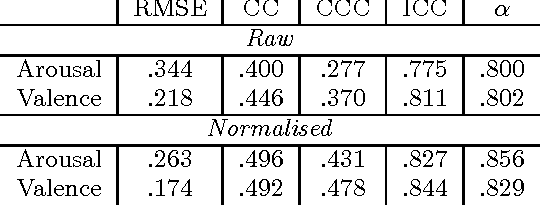
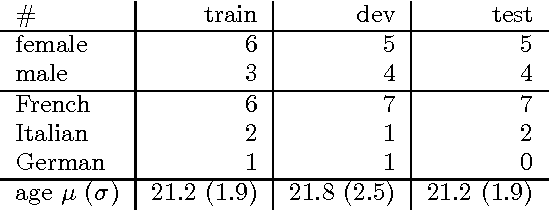
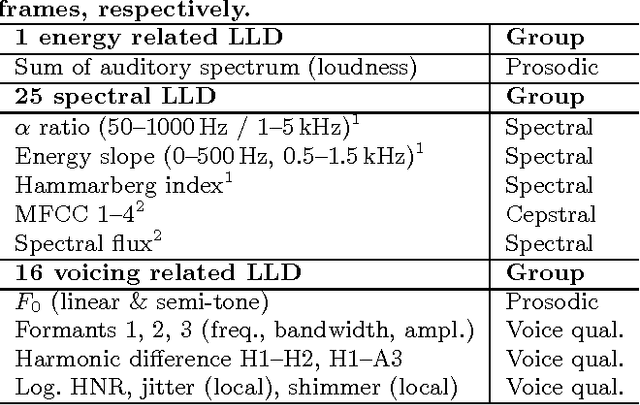
The Audio/Visual Emotion Challenge and Workshop (AVEC 2016) "Depression, Mood and Emotion" will be the sixth competition event aimed at comparison of multimedia processing and machine learning methods for automatic audio, visual and physiological depression and emotion analysis, with all participants competing under strictly the same conditions. The goal of the Challenge is to provide a common benchmark test set for multi-modal information processing and to bring together the depression and emotion recognition communities, as well as the audio, video and physiological processing communities, to compare the relative merits of the various approaches to depression and emotion recognition under well-defined and strictly comparable conditions and establish to what extent fusion of the approaches is possible and beneficial. This paper presents the challenge guidelines, the common data used, and the performance of the baseline system on the two tasks.