 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEFI: A Toolbox for Feature Importance Fusion and Interpretation in Python
Aug 08, 2022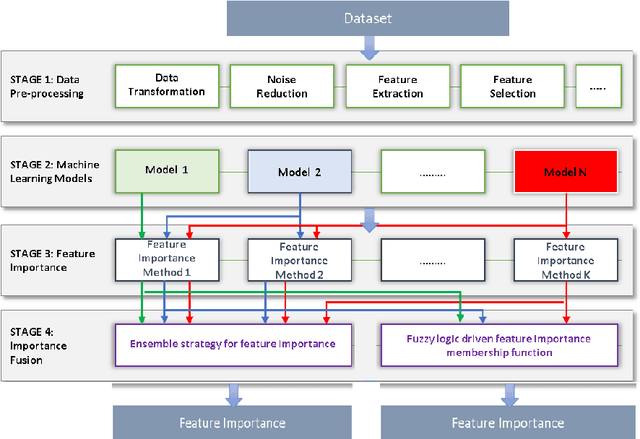
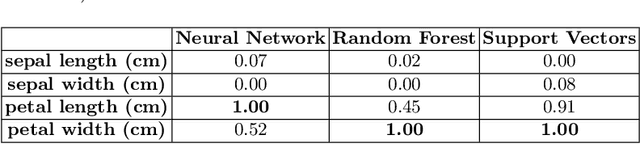
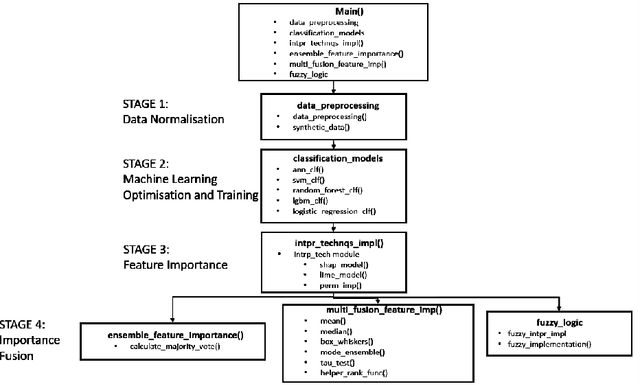

This paper presents an open-source Python toolbox called Ensemble Feature Importance (EFI) to provide machine learning (ML) researchers, domain experts, and decision makers with robust and accurate feature importance quantification and more reliable mechanistic interpretation of feature importance for prediction problems using fuzzy sets. The toolkit was developed to address uncertainties in feature importance quantification and lack of trustworthy feature importance interpretation due to the diverse availability of machine learning algorithms, feature importance calculation methods, and dataset dependencies. EFI merges results from multiple machine learning models with different feature importance calculation approaches using data bootstrapping and decision fusion techniques, such as mean, majority voting and fuzzy logic. The main attributes of the EFI toolbox are: (i) automatic optimisation of ML algorithms, (ii) automatic computation of a set of feature importance coefficients from optimised ML algorithms and feature importance calculation techniques, (iii) automatic aggregation of importance coefficients using multiple decision fusion techniques, and (iv) fuzzy membership functions that show the importance of each feature to the prediction task. The key modules and functions of the toolbox are described, and a simple example of their application is presented using the popular Iris dataset.
Mechanistic Interpretation of Machine Learning Inference: A Fuzzy Feature Importance Fusion Approach
Oct 22, 2021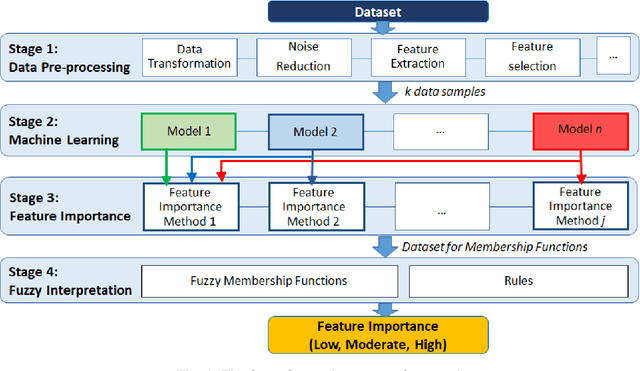
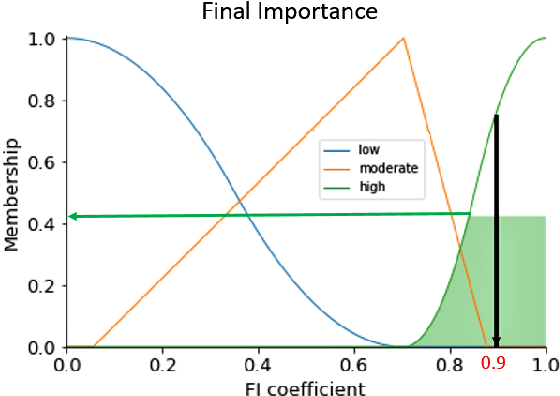
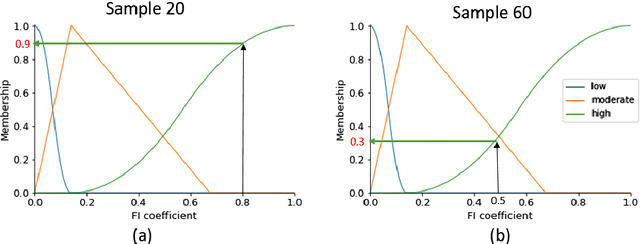
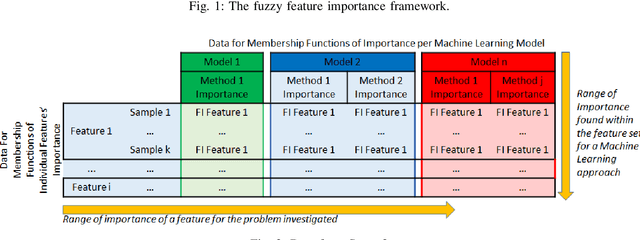
With the widespread use of machine learning to support decision-making, it is increasingly important to verify and understand the reasons why a particular output is produced. Although post-training feature importance approaches assist this interpretation, there is an overall lack of consensus regarding how feature importance should be quantified, making explanations of model predictions unreliable. In addition, many of these explanations depend on the specific machine learning approach employed and on the subset of data used when calculating feature importance. A possible solution to improve the reliability of explanations is to combine results from multiple feature importance quantifiers from different machine learning approaches coupled with re-sampling. Current state-of-the-art ensemble feature importance fusion uses crisp techniques to fuse results from different approaches. There is, however, significant loss of information as these approaches are not context-aware and reduce several quantifiers to a single crisp output. More importantly, their representation of 'importance' as coefficients is misleading and incomprehensible to end-users and decision makers. Here we show how the use of fuzzy data fusion methods can overcome some of the important limitations of crisp fusion methods.
Impressive computational acceleration by using machine learning for 2-dimensional super-lubricant materials discovery
Nov 20, 2019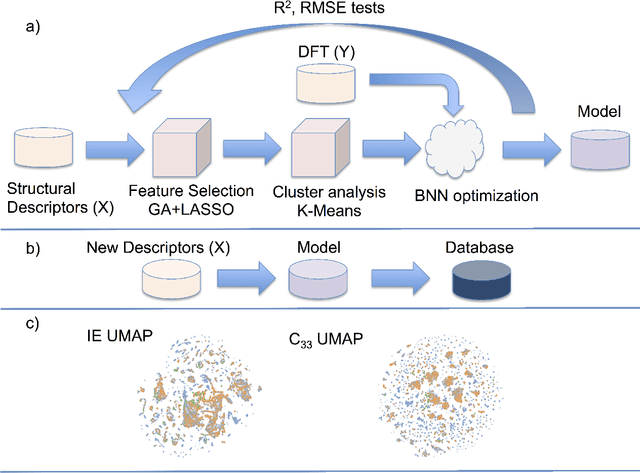
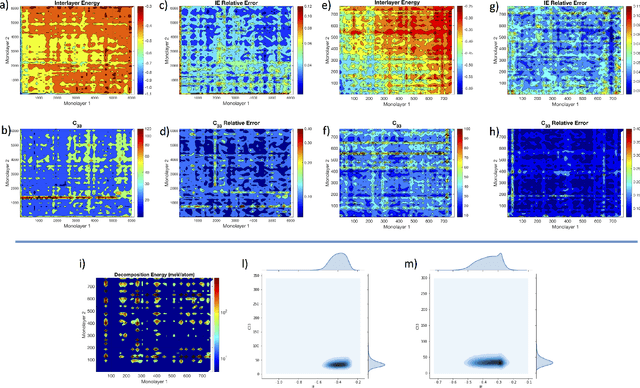

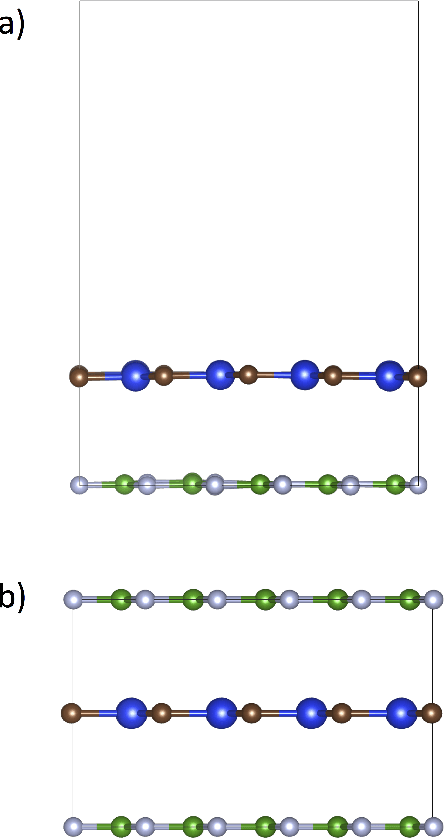
The screening of novel materials is an important topic in the field of materials science. Although traditional computational modeling, especially first-principles approaches, is a very useful and accurate tool to predict the properties of novel materials, it still demands extensive and expensive state-of-the-art computational resources. Additionally, they can be often extremely time consuming. We describe a time and resource-efficient machine learning approach to create a large dataset of structural properties of van der Waals layered structures. In particular, we focus on the interlayer energy and the elastic constant of layered materials composed of two different 2-dimensional (2D) structures, that are important for novel solid lubricant and super-lubricant materials. We show that machine learning models can recapitulate results of computationally expansive approaches (i.e. density functional theory) with high accuracy.