 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHelix 1.0: An Open-Source Framework for Reproducible and Interpretable Machine Learning on Tabular Scientific Data
Jul 23, 2025Helix is an open-source, extensible, Python-based software framework to facilitate reproducible and interpretable machine learning workflows for tabular data. It addresses the growing need for transparent experimental data analytics provenance, ensuring that the entire analytical process -- including decisions around data transformation and methodological choices -- is documented, accessible, reproducible, and comprehensible to relevant stakeholders. The platform comprises modules for standardised data preprocessing, visualisation, machine learning model training, evaluation, interpretation, results inspection, and model prediction for unseen data. To further empower researchers without formal training in data science to derive meaningful and actionable insights, Helix features a user-friendly interface that enables the design of computational experiments, inspection of outcomes, including a novel interpretation approach to machine learning decisions using linguistic terms all within an integrated environment. Released under the MIT licence, Helix is accessible via GitHub and PyPI, supporting community-driven development and promoting adherence to the FAIR principles.
Towards Privacy-Preserving Affect Recognition: A Two-Level Deep Learning Architecture
Nov 14, 2021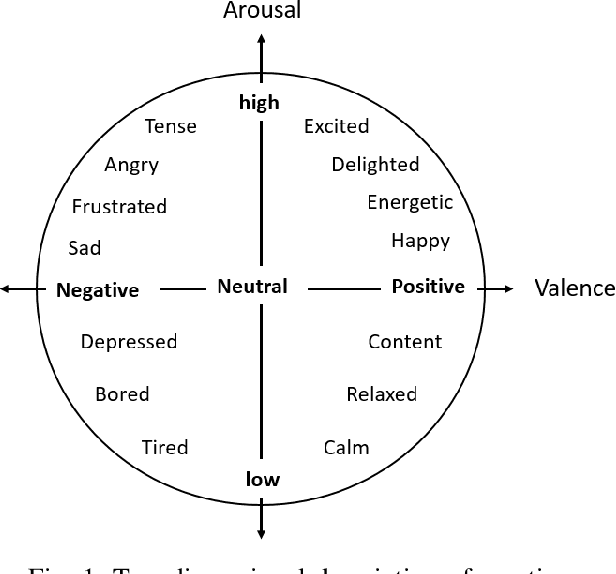
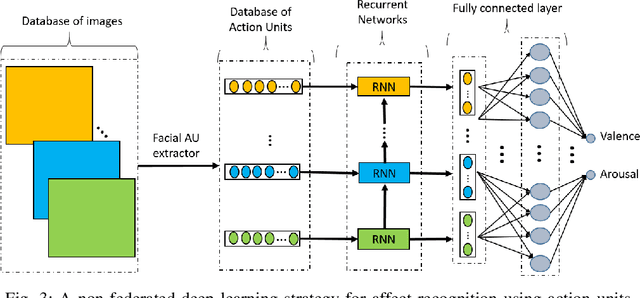
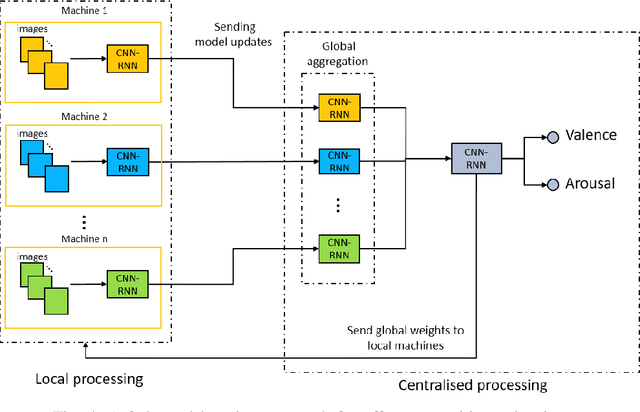
Automatically understanding and recognising human affective states using images and computer vision can improve human-computer and human-robot interaction. However, privacy has become an issue of great concern, as the identities of people used to train affective models can be exposed in the process. For instance, malicious individuals could exploit images from users and assume their identities. In addition, affect recognition using images can lead to discriminatory and algorithmic bias, as certain information such as race, gender, and age could be assumed based on facial features. Possible solutions to protect the privacy of users and avoid misuse of their identities are to: (1) extract anonymised facial features, namely action units (AU) from a database of images, discard the images and use AUs for processing and training, and (2) federated learning (FL) i.e. process raw images in users' local machines (local processing) and send the locally trained models to the main processing machine for aggregation (central processing). In this paper, we propose a two-level deep learning architecture for affect recognition that uses AUs in level 1 and FL in level 2 to protect users' identities. The architecture consists of recurrent neural networks to capture the temporal relationships amongst the features and predict valence and arousal affective states. In our experiments, we evaluate the performance of our privacy-preserving architecture using different variations of recurrent neural networks on RECOLA, a comprehensive multimodal affective database. Our results show state-of-the-art performance of $0.426$ for valence and $0.401$ for arousal using the Concordance Correlation Coefficient evaluation metric, demonstrating the feasibility of developing models for affect recognition that are both accurate and ensure privacy.
Mechanistic Interpretation of Machine Learning Inference: A Fuzzy Feature Importance Fusion Approach
Oct 22, 2021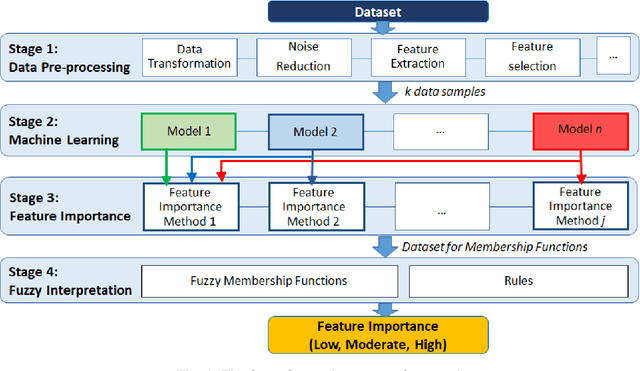
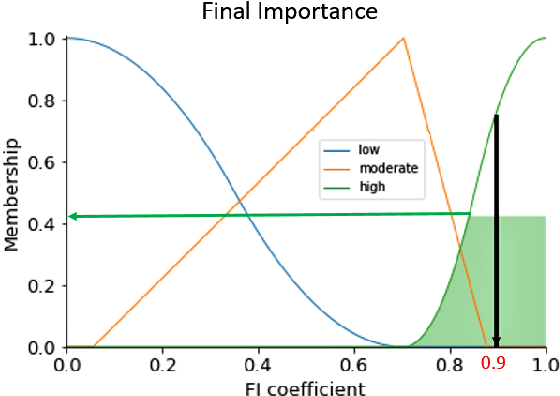
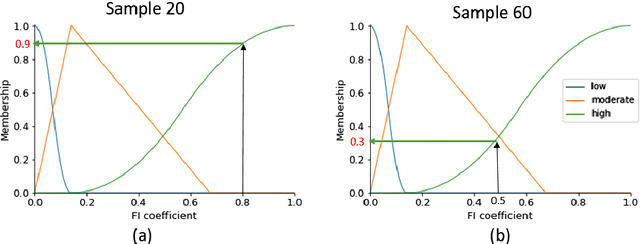
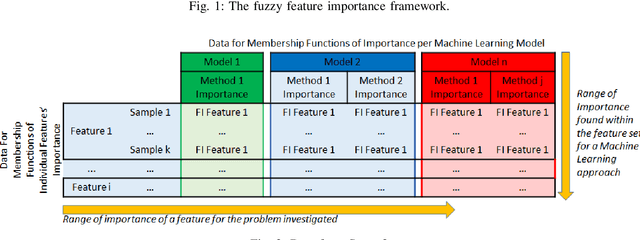
With the widespread use of machine learning to support decision-making, it is increasingly important to verify and understand the reasons why a particular output is produced. Although post-training feature importance approaches assist this interpretation, there is an overall lack of consensus regarding how feature importance should be quantified, making explanations of model predictions unreliable. In addition, many of these explanations depend on the specific machine learning approach employed and on the subset of data used when calculating feature importance. A possible solution to improve the reliability of explanations is to combine results from multiple feature importance quantifiers from different machine learning approaches coupled with re-sampling. Current state-of-the-art ensemble feature importance fusion uses crisp techniques to fuse results from different approaches. There is, however, significant loss of information as these approaches are not context-aware and reduce several quantifiers to a single crisp output. More importantly, their representation of 'importance' as coefficients is misleading and incomprehensible to end-users and decision makers. Here we show how the use of fuzzy data fusion methods can overcome some of the important limitations of crisp fusion methods.