 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEFI: A Toolbox for Feature Importance Fusion and Interpretation in Python
Aug 08, 2022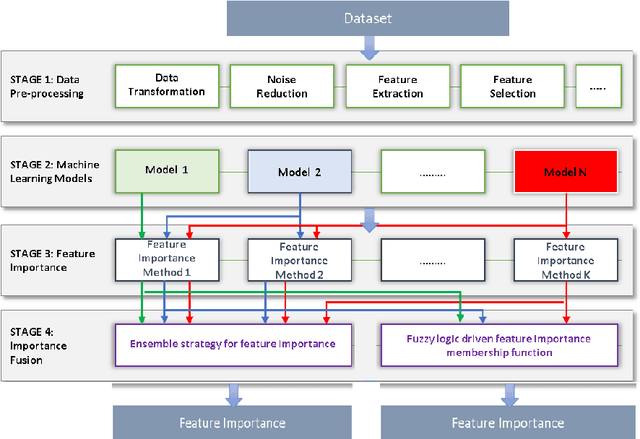
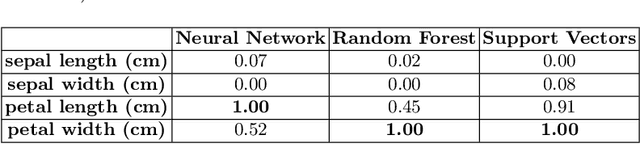
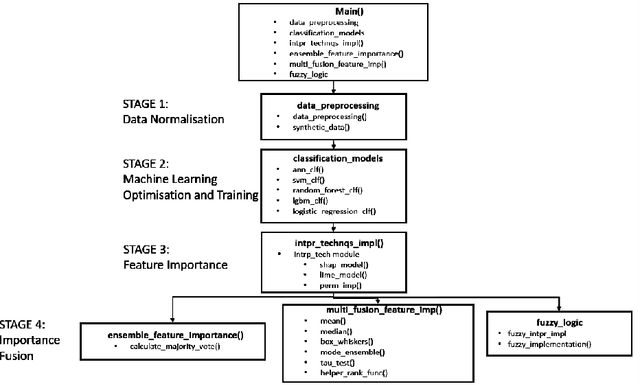

This paper presents an open-source Python toolbox called Ensemble Feature Importance (EFI) to provide machine learning (ML) researchers, domain experts, and decision makers with robust and accurate feature importance quantification and more reliable mechanistic interpretation of feature importance for prediction problems using fuzzy sets. The toolkit was developed to address uncertainties in feature importance quantification and lack of trustworthy feature importance interpretation due to the diverse availability of machine learning algorithms, feature importance calculation methods, and dataset dependencies. EFI merges results from multiple machine learning models with different feature importance calculation approaches using data bootstrapping and decision fusion techniques, such as mean, majority voting and fuzzy logic. The main attributes of the EFI toolbox are: (i) automatic optimisation of ML algorithms, (ii) automatic computation of a set of feature importance coefficients from optimised ML algorithms and feature importance calculation techniques, (iii) automatic aggregation of importance coefficients using multiple decision fusion techniques, and (iv) fuzzy membership functions that show the importance of each feature to the prediction task. The key modules and functions of the toolbox are described, and a simple example of their application is presented using the popular Iris dataset.
Contextual Intelligent Decisions: Expert Moderation of Machine Outputs for Fair Assessment of Commercial Driving
Feb 20, 2022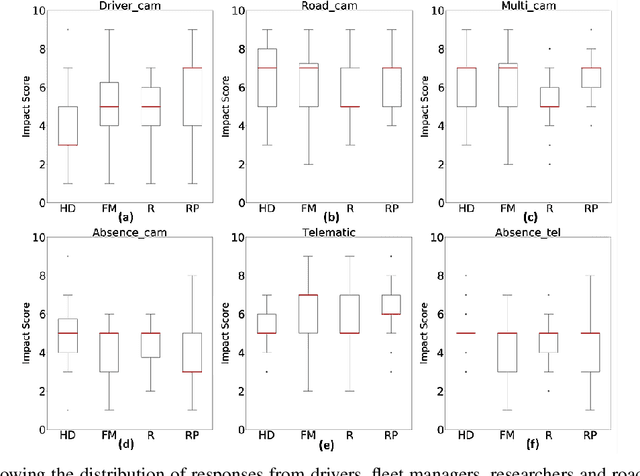
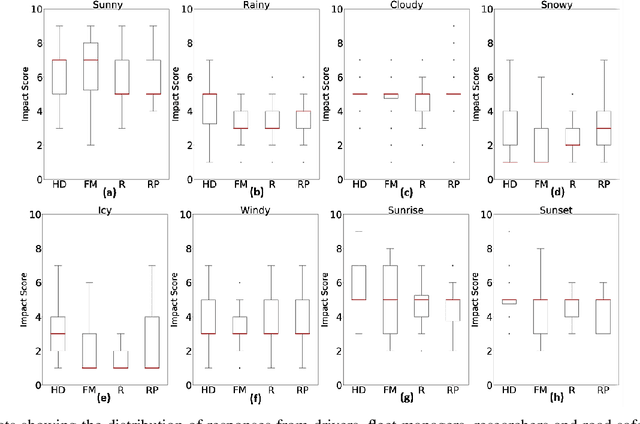

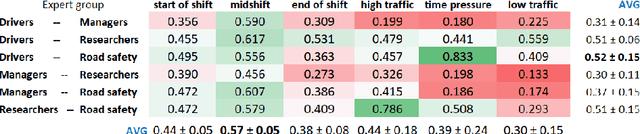
Commercial driving is a complex multifaceted task influenced by personal traits and external contextual factors, such as weather, traffic, road conditions, etc. Previous intelligent commercial driver-assessment systems do not consider these factors when analysing the impact of driving behaviours on road safety, potentially producing biased, inaccurate, and unfair assessments. In this paper, we introduce a methodology (Expert-centered Driver Assessment) towards a fairer automatic road safety assessment of drivers' behaviours, taking into consideration behaviours as a response to contextual factors. The contextual moderation embedded within the intelligent decision-making process is underpinned by expert input, comprising of a range of associated stakeholders in the industry. Guided by the literature and expert input, we identify critical factors affecting driving and develop an interval-valued response-format questionnaire to capture the uncertainty of the influence of factors and variance amongst experts' views. Questionnaire data are modelled and analysed using fuzzy sets, as they provide a suitable computational approach to be incorporated into decision-making systems with uncertainty. The methodology has allowed us to identify the factors that need to be considered when moderating driver sensor data, and to effectively capture experts' opinions about the effects of the factors. An example of our methodology using Heavy Goods Vehicles professionals input is provided to demonstrate how the expert-centred moderation can be embedded in intelligent driver assessment systems.
Towards Privacy-Preserving Affect Recognition: A Two-Level Deep Learning Architecture
Nov 14, 2021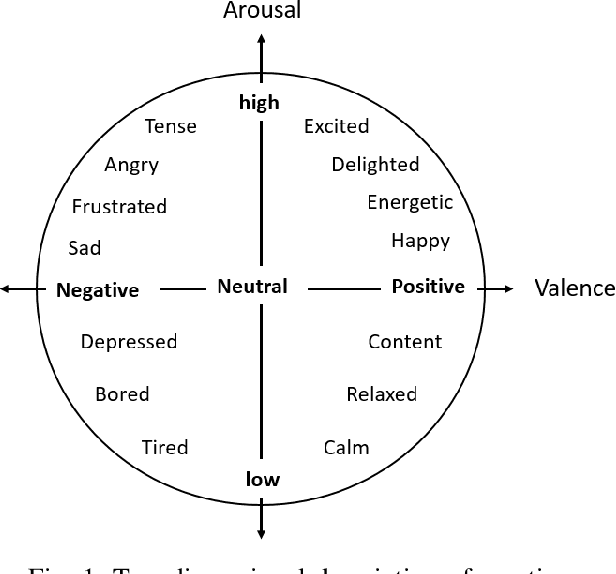
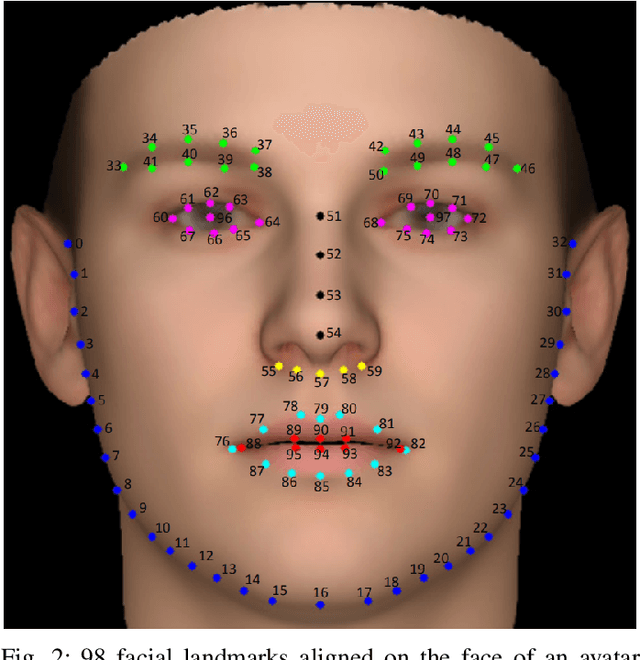
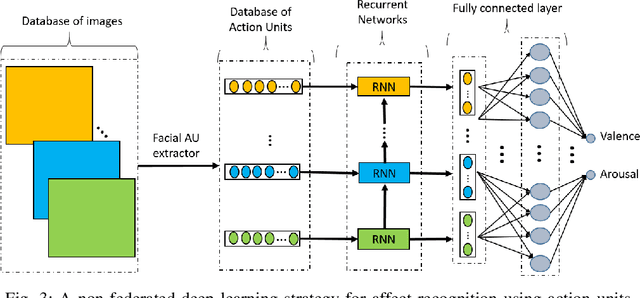
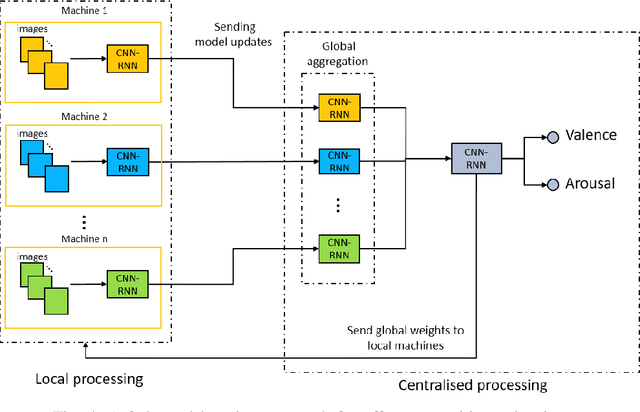
Automatically understanding and recognising human affective states using images and computer vision can improve human-computer and human-robot interaction. However, privacy has become an issue of great concern, as the identities of people used to train affective models can be exposed in the process. For instance, malicious individuals could exploit images from users and assume their identities. In addition, affect recognition using images can lead to discriminatory and algorithmic bias, as certain information such as race, gender, and age could be assumed based on facial features. Possible solutions to protect the privacy of users and avoid misuse of their identities are to: (1) extract anonymised facial features, namely action units (AU) from a database of images, discard the images and use AUs for processing and training, and (2) federated learning (FL) i.e. process raw images in users' local machines (local processing) and send the locally trained models to the main processing machine for aggregation (central processing). In this paper, we propose a two-level deep learning architecture for affect recognition that uses AUs in level 1 and FL in level 2 to protect users' identities. The architecture consists of recurrent neural networks to capture the temporal relationships amongst the features and predict valence and arousal affective states. In our experiments, we evaluate the performance of our privacy-preserving architecture using different variations of recurrent neural networks on RECOLA, a comprehensive multimodal affective database. Our results show state-of-the-art performance of $0.426$ for valence and $0.401$ for arousal using the Concordance Correlation Coefficient evaluation metric, demonstrating the feasibility of developing models for affect recognition that are both accurate and ensure privacy.
Mechanistic Interpretation of Machine Learning Inference: A Fuzzy Feature Importance Fusion Approach
Oct 22, 2021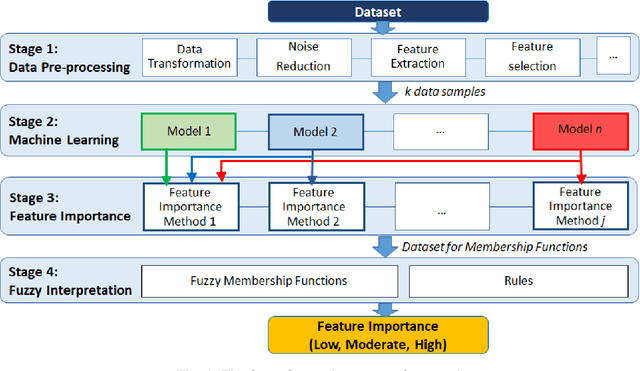
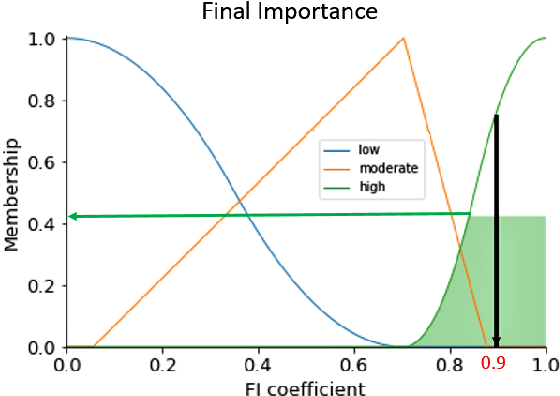
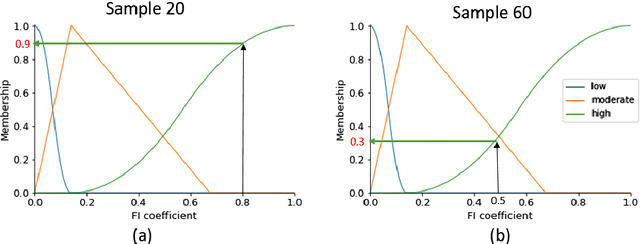
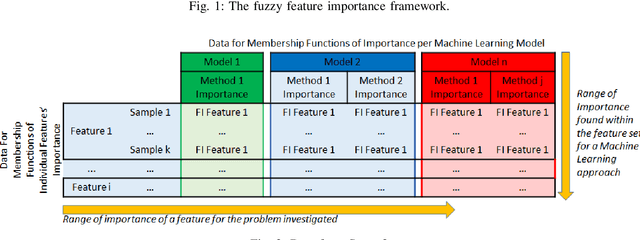
With the widespread use of machine learning to support decision-making, it is increasingly important to verify and understand the reasons why a particular output is produced. Although post-training feature importance approaches assist this interpretation, there is an overall lack of consensus regarding how feature importance should be quantified, making explanations of model predictions unreliable. In addition, many of these explanations depend on the specific machine learning approach employed and on the subset of data used when calculating feature importance. A possible solution to improve the reliability of explanations is to combine results from multiple feature importance quantifiers from different machine learning approaches coupled with re-sampling. Current state-of-the-art ensemble feature importance fusion uses crisp techniques to fuse results from different approaches. There is, however, significant loss of information as these approaches are not context-aware and reduce several quantifiers to a single crisp output. More importantly, their representation of 'importance' as coefficients is misleading and incomprehensible to end-users and decision makers. Here we show how the use of fuzzy data fusion methods can overcome some of the important limitations of crisp fusion methods.
Juxtaposition of System Dynamics and Agent-based Simulation for a Case Study in Immunosenescence
Jul 20, 2016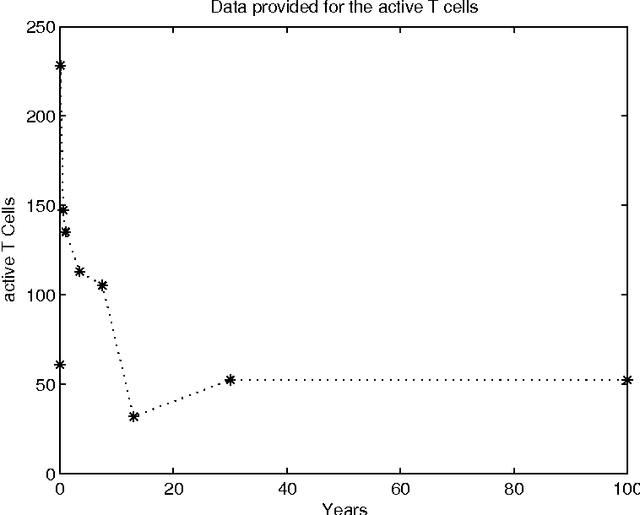

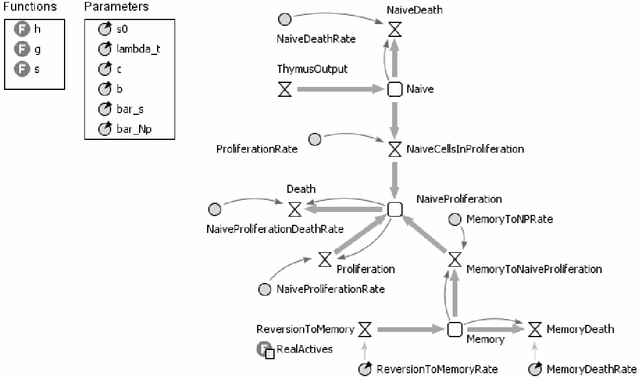

Advances in healthcare and in the quality of life significantly increase human life expectancy. With the ageing of populations, new un-faced challenges are brought to science. The human body is naturally selected to be well-functioning until the age of reproduction to keep the species alive. However, as the lifespan extends, unseen problems due to the body deterioration emerge. There are several age-related diseases with no appropriate treatment; therefore, the complex ageing phenomena needs further understanding. Immunosenescence, the ageing of the immune system, is highly correlated to the negative effects of ageing, such as the increase of auto-inflammatory diseases and decrease in responsiveness to new diseases. Besides clinical and mathematical tools, we believe there is opportunity to further exploit simulation tools to understand immunosenescence. Compared to real-world experimentation, benefits include time and cost effectiveness due to the laborious, resource-intensiveness of the biological environment and the possibility of conducting experiments without ethic restrictions. Contrasted with mathematical models, simulation modelling is more suitable for representing complex systems and emergence. In addition, there is the belief that simulation models are easier to communicate in interdisciplinary contexts. Our work investigates the usefulness of simulations to understand immunosenescence by employing two different simulation methods, agent-based and system dynamics simulation, to a case study of immune cells depletion with age.
Investigating Mathematical Models of Immuno-Interactions with Early-Stage Cancer under an Agent-Based Modelling Perspective
May 31, 2013
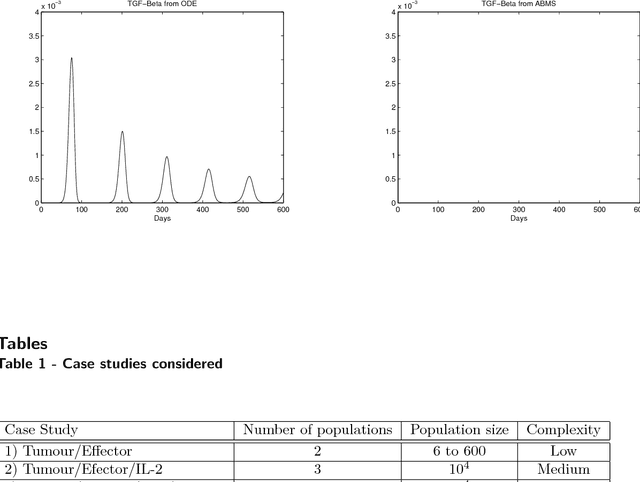

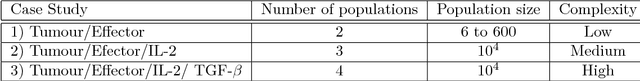
Many advances in research regarding immuno-interactions with cancer were developed with the help of ordinary differential equation (ODE) models. These models, however, are not effectively capable of representing problems involving individual localisation, memory and emerging properties, which are common characteristics of cells and molecules of the immune system. Agent-based modelling and simulation is an alternative paradigm to ODE models that overcomes these limitations. In this paper we investigate the potential contribution of agent-based modelling and simulation when compared to ODE modelling and simulation. We seek answers to the following questions: Is it possible to obtain an equivalent agent-based model from the ODE formulation? Do the outcomes differ? Are there any benefits of using one method compared to the other? To answer these questions, we have considered three case studies using established mathematical models of immune interactions with early-stage cancer. These case studies were re-conceptualised under an agent-based perspective and the simulation results were then compared with those from the ODE models. Our results show that it is possible to obtain equivalent agent-based models (i.e. implementing the same mechanisms); the simulation output of both types of models however might differ depending on the attributes of the system to be modelled. In some cases, additional insight from using agent-based modelling was obtained. Overall, we can confirm that agent-based modelling is a useful addition to the tool set of immunologists, as it has extra features that allow for simulations with characteristics that are closer to the biological phenomena.
Comparing System Dynamics and Agent-Based Simulation for Tumour Growth and its Interactions with Effector Cells
Aug 16, 2011
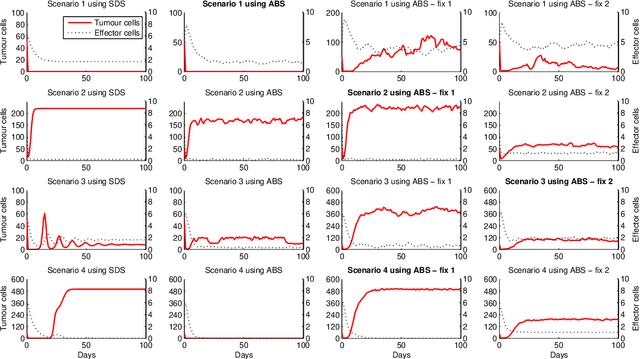
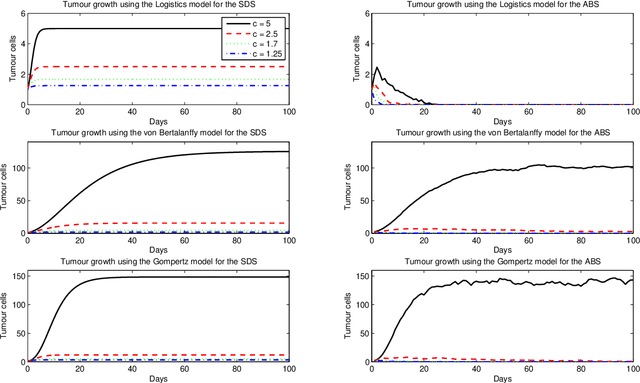
There is little research concerning comparisons and combination of System Dynamics Simulation (SDS) and Agent Based Simulation (ABS). ABS is a paradigm used in many levels of abstraction, including those levels covered by SDS. We believe that the establishment of frameworks for the choice between these two simulation approaches would contribute to the simulation research. Hence, our work aims for the establishment of directions for the choice between SDS and ABS approaches for immune system-related problems. Previously, we compared the use of ABS and SDS for modelling agents' behaviour in an environment with nomovement or interactions between these agents. We concluded that for these types of agents it is preferable to use SDS, as it takes up less computational resources and produces the same results as those obtained by the ABS model. In order to move this research forward, our next research question is: if we introduce interactions between these agents will SDS still be the most appropriate paradigm to be used? To answer this question for immune system simulation problems, we will use, as case studies, models involving interactions between tumour cells and immune effector cells. Experiments show that there are cases where SDS and ABS can not be used interchangeably, and therefore, their comparison is not straightforward.
* 8 pages, 8 figures, 2 tables, International Summer Computer Simulation Conference 2011
System Dynamics Modelling of the Processes Involving the Maintenance of the Naive T Cell Repertoire
Apr 29, 2010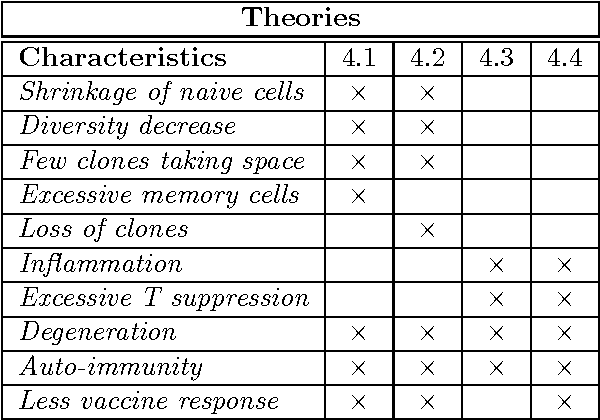
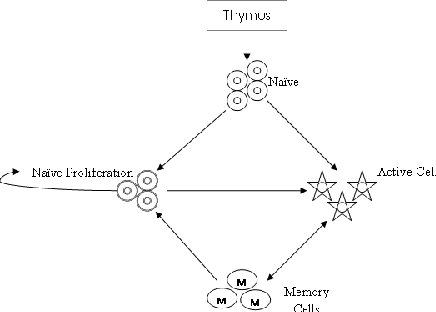
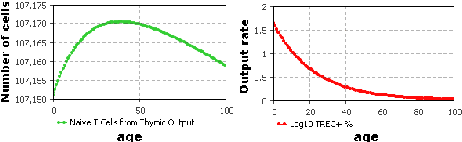
The study of immune system aging, i.e. immunosenescence, is a relatively new research topic. It deals with understanding the processes of immunodegradation that indicate signs of functionality loss possibly leading to death. Even though it is not possible to prevent immunosenescence, there is great benefit in comprehending its causes, which may help to reverse some of the damage done and thus improve life expectancy. One of the main factors influencing the process of immunosenescence is the number and phenotypical variety of naive T cells in an individual. This work presents a review of immunosenescence, proposes system dynamics modelling of the processes involving the maintenance of the naive T cell repertoire and presents some preliminary results.
* 6 pages, 2 figures, 1 table, 9th Annual Workshop on Computational Intelligence (UKCI 2009), Nottingham, UK