 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeESP-MedSAM: Efficient Self-Prompting SAM for Universal Domain-Generalized Medical Image Segmentation
Jul 19, 2024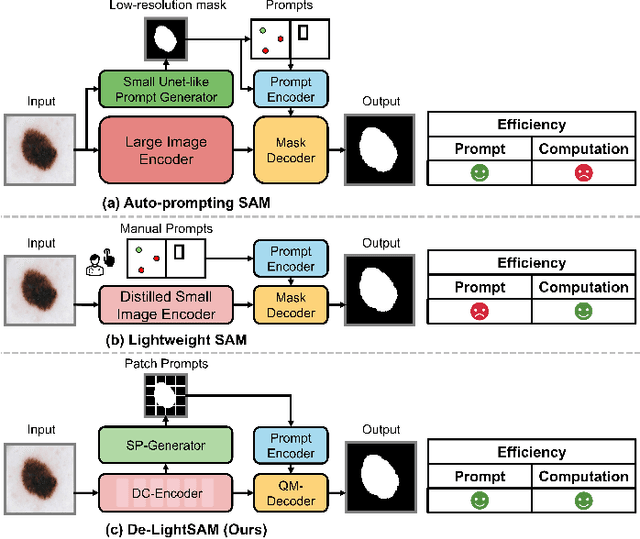
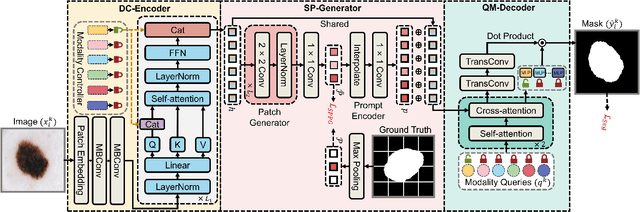
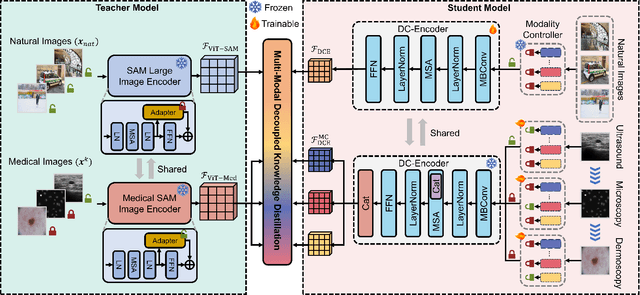
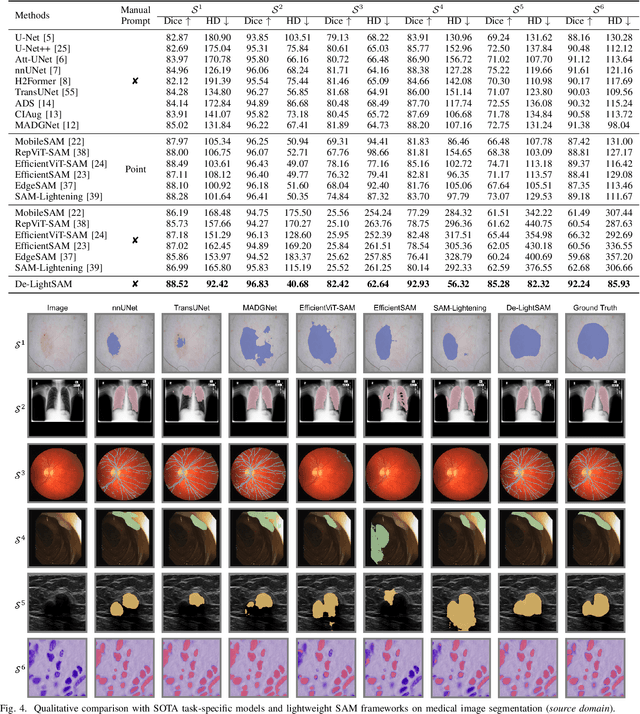
The Segment Anything Model (SAM) has demonstrated outstanding adaptation to medical image segmentation but still faces three major challenges. Firstly, the huge computational costs of SAM limit its real-world applicability. Secondly, SAM depends on manual annotations (e.g., points, boxes) as prompts, which are laborious and impractical in clinical scenarios. Thirdly, SAM handles all segmentation targets equally, which is suboptimal for diverse medical modalities with inherent heterogeneity. To address these issues, we propose an Efficient Self-Prompting SAM for universal medical image segmentation, named ESP-MedSAM. We devise a Multi-Modal Decoupled Knowledge Distillation (MMDKD) strategy to distil common image knowledge and domain-specific medical knowledge from the foundation model to train a lightweight image encoder and a modality controller. Further, they combine with the additionally introduced Self-Patch Prompt Generator (SPPG) and Query-Decoupled Modality Decoder (QDMD) to construct ESP-MedSAM. Specifically, SPPG aims to generate a set of patch prompts automatically and QDMD leverages a one-to-one strategy to provide an independent decoding channel for every modality. Extensive experiments indicate that ESP-MedSAM outperforms state-of-the-arts in diverse medical imaging segmentation takes, displaying superior zero-shot learning and modality transfer ability. Especially, our framework uses only 31.4% parameters compared to SAM-Base.
Gradient-based Fuzzy System Optimisation via Automatic Differentiation -- FuzzyR as a Use Case
Mar 18, 2024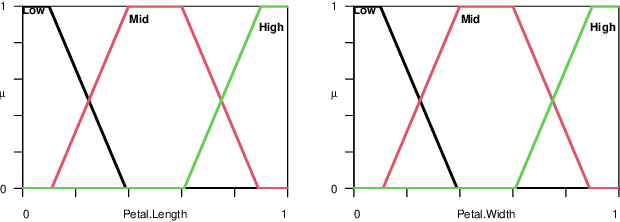
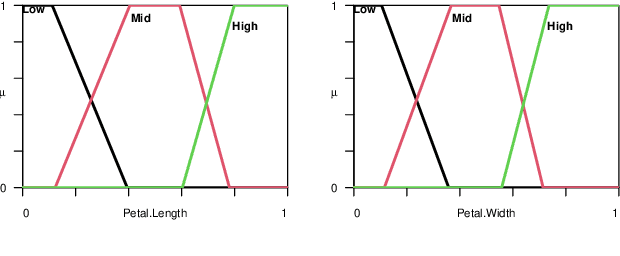
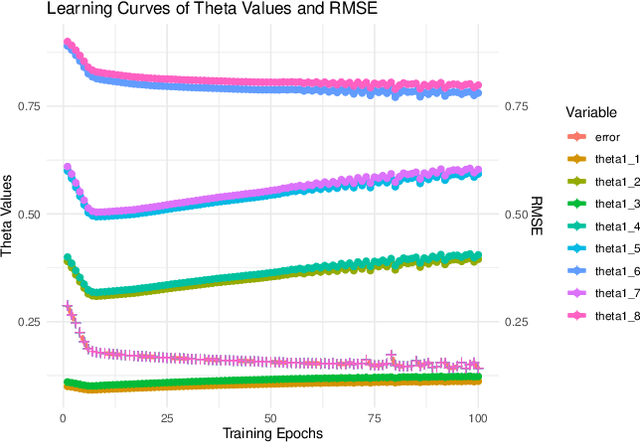

Since their introduction, fuzzy sets and systems have become an important area of research known for its versatility in modelling, knowledge representation and reasoning, and increasingly its potential within the context explainable AI. While the applications of fuzzy systems are diverse, there has been comparatively little advancement in their design from a machine learning perspective. In other words, while representations such as neural networks have benefited from a boom in learning capability driven by an increase in computational performance in combination with advances in their training mechanisms and available tool, in particular gradient descent, the impact on fuzzy system design has been limited. In this paper, we discuss gradient-descent-based optimisation of fuzzy systems, focussing in particular on automatic differentiation -- crucial to neural network learning -- with a view to free fuzzy system designers from intricate derivative computations, allowing for more focus on the functional and explainability aspects of their design. As a starting point, we present a use case in FuzzyR which demonstrates how current fuzzy inference system implementations can be adjusted to leverage powerful features of automatic differentiation tools sets, discussing its potential for the future of fuzzy system design.
A Recommender System Approach for Very Large-scale Multiobjective Optimization
Apr 08, 2023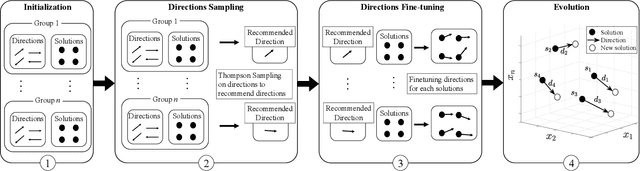
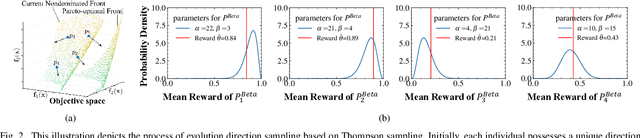
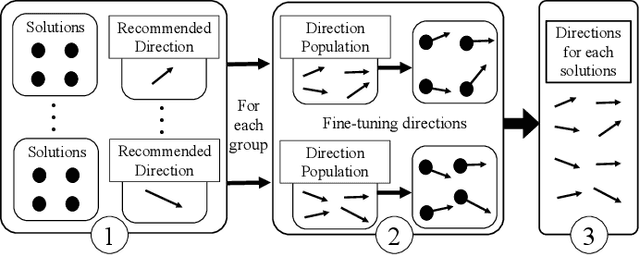
We define very large multi-objective optimization problems to be multiobjective optimization problems in which the number of decision variables is greater than 100,000 dimensions. This is an important class of problems as many real-world problems require optimizing hundreds of thousands of variables. Existing evolutionary optimization methods fall short of such requirements when dealing with problems at this very large scale. Inspired by the success of existing recommender systems to handle very large-scale items with limited historical interactions, in this paper we propose a method termed Very large-scale Multiobjective Optimization through Recommender Systems (VMORS). The idea of the proposed method is to transform the defined such very large-scale problems into a problem that can be tackled by a recommender system. In the framework, the solutions are regarded as users, and the different evolution directions are items waiting for the recommendation. We use Thompson sampling to recommend the most suitable items (evolutionary directions) for different users (solutions), in order to locate the optimal solution to a multiobjective optimization problem in a very large search space within acceptable time. We test our proposed method on different problems from 100,000 to 500,000 dimensions, and experimental results show that our method not only shows good performance but also significant improvement over existing methods.
A Novel Weighted Combination Method for Feature Selection using Fuzzy Sets
May 21, 2020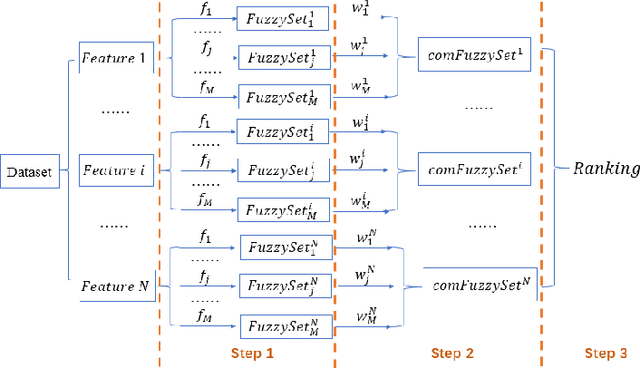

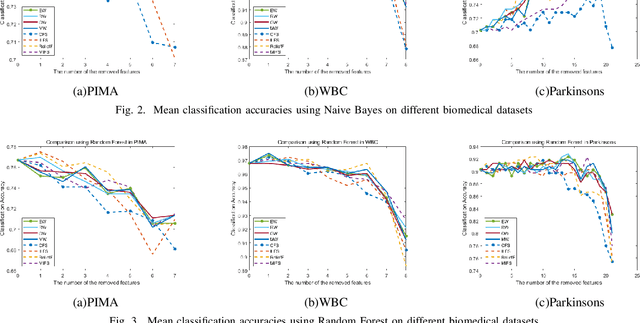

In this paper, we propose a novel weighted combination feature selection method using bootstrap and fuzzy sets. The proposed method mainly consists of three processes, including fuzzy sets generation using bootstrap, weighted combination of fuzzy sets and feature ranking based on defuzzification. We implemented the proposed method by combining four state-of-the-art feature selection methods and evaluated the performance based on three publicly available biomedical datasets using five-fold cross validation. Based on the feature selection results, our proposed method produced comparable (if not better) classification accuracies to the best of the individual feature selection methods for all evaluated datasets. More importantly, we also applied standard deviation and Pearson's correlation to measure the stability of the methods. Remarkably, our combination method achieved significantly higher stability than the four individual methods when variations and size reductions were introduced to the datasets.
Performance Optimization of a Fuzzy Entropy based Feature Selection and Classification Framework
May 21, 2020



In this paper, based on a fuzzy entropy feature selection framework, different methods have been implemented and compared to improve the key components of the framework. Those methods include the combinations of three ideal vector calculations, three maximal similarity classifiers and three fuzzy entropy functions. Different feature removal orders based on the fuzzy entropy values were also compared. The proposed method was evaluated on three publicly available biomedical datasets. From the experiments, we concluded the optimized combination of the ideal vector, similarity classifier and fuzzy entropy function for feature selection. The optimized framework was also compared with other six classical filter-based feature selection methods. The proposed method was ranked as one of the top performers together with the Correlation and ReliefF methods. More importantly, the proposed method achieved the most stable performance for all three datasets when the features being gradually removed. This indicates a better feature ranking performance than the other compared methods.
A Novel Meta Learning Framework for Feature Selection using Data Synthesis and Fuzzy Similarity
May 21, 2020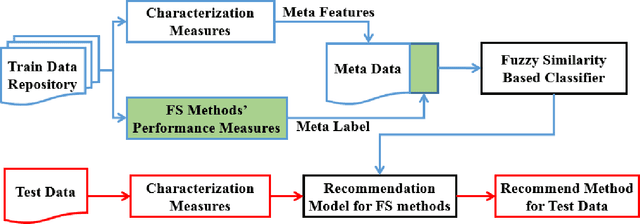

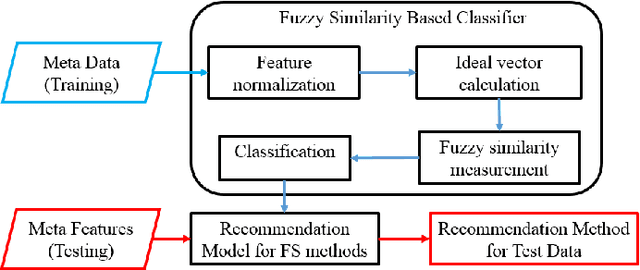
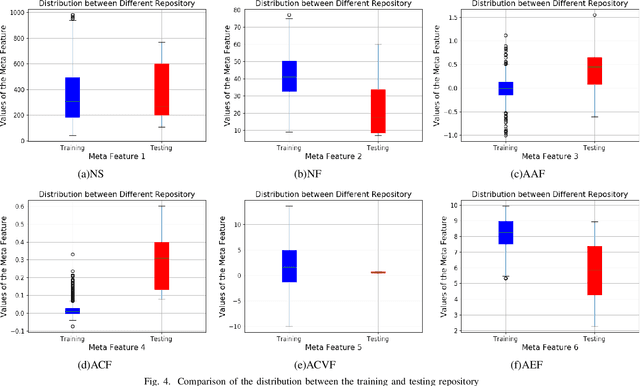
This paper presents a novel meta learning framework for feature selection (FS) based on fuzzy similarity. The proposed method aims to recommend the best FS method from four candidate FS methods for any given dataset. This is achieved by firstly constructing a large training data repository using data synthesis. Six meta features that represent the characteristics of the training dataset are then extracted. The best FS method for each of the training datasets is used as the meta label. Both the meta features and the corresponding meta labels are subsequently used to train a classification model using a fuzzy similarity measure based framework. Finally the trained model is used to recommend the most suitable FS method for a given unseen dataset. This proposed method was evaluated based on eight public datasets of real-world applications. It successfully recommended the best method for five datasets and the second best method for one dataset, which outperformed any of the four individual FS methods. Besides, the proposed method is computationally efficient for algorithm selection, leading to negligible additional time for the feature selection process. Thus, the paper contributes a novel method for effectively recommending which feature selection method to use for any new given dataset.
Relative Geometry-Aware Siamese Neural Network for 6DOF Camera Relocalization
Jan 21, 2019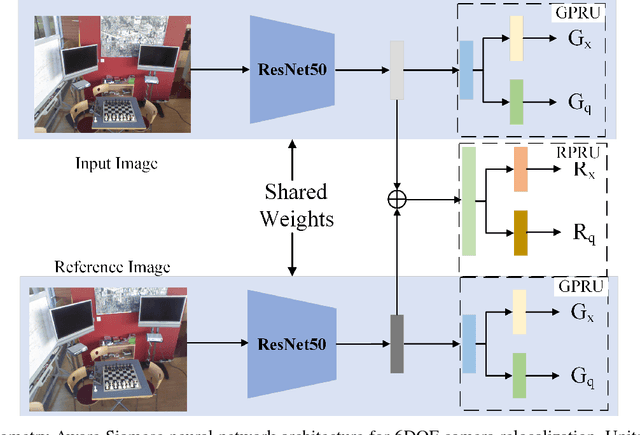
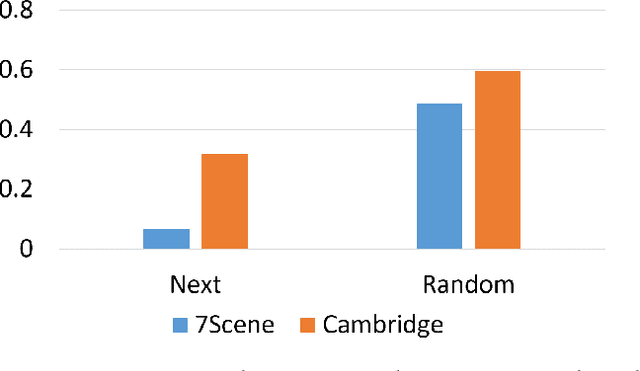
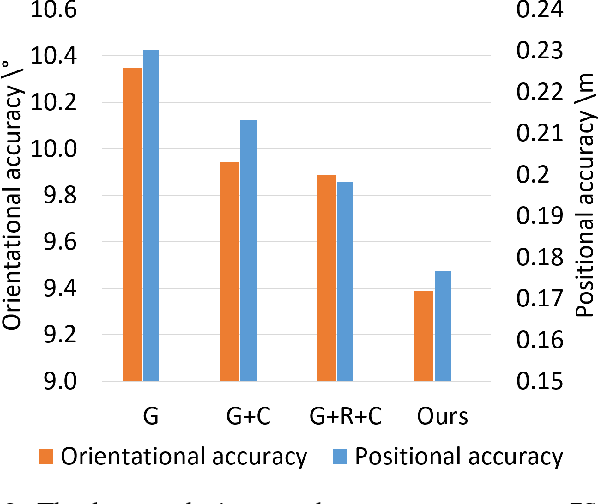
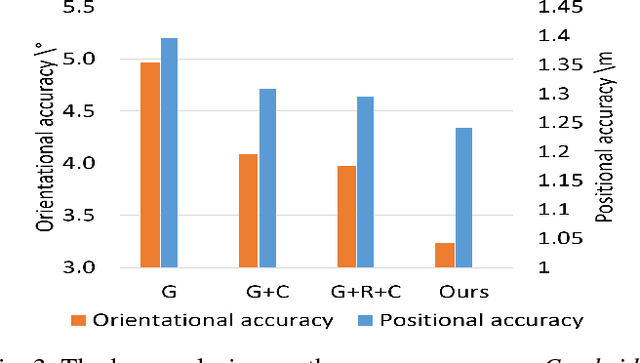
6DOF camera relocalization is an important component of autonomous driving and navigation. Deep learning has recently emerged as a promising technique to tackle this problem. In this paper, we present a novel relative geometry-aware Siamese neural network to enhance the performance of deep learning-based methods through explicitly exploiting the relative geometry constraints between images. We perform multi-task learning and predict the absolute and relative poses simultaneously. We regularize the shared-weight twin networks in both the pose and feature domains to ensure that the estimated poses are globally as well as locally correct. We employ metric learning and design a novel adaptive metric distance loss to learn a feature that is capable of distinguishing poses of visually similar images from different locations. We evaluate the proposed method on public indoor and outdoor benchmarks and the experimental results demonstrate that our method can significantly improve localization performance. Furthermore, extensive ablation evaluations are conducted to demonstrate the effectiveness of different terms of the loss function.
Modelling Cyber-Security Experts' Decision Making Processes using Aggregation Operators
Aug 30, 2016


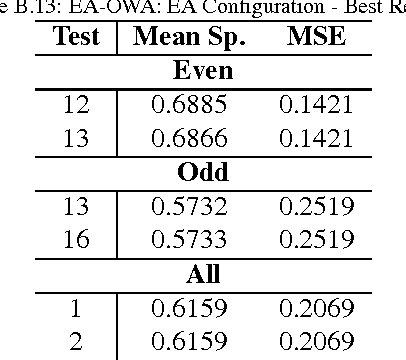
An important role carried out by cyber-security experts is the assessment of proposed computer systems, during their design stage. This task is fraught with difficulties and uncertainty, making the knowledge provided by human experts essential for successful assessment. Today, the increasing number of progressively complex systems has led to an urgent need to produce tools that support the expert-led process of system-security assessment. In this research, we use weighted averages (WAs) and ordered weighted averages (OWAs) with evolutionary algorithms (EAs) to create aggregation operators that model parts of the assessment process. We show how individual overall ratings for security components can be produced from ratings of their characteristics, and how these individual overall ratings can be aggregated to produce overall rankings of potential attacks on a system. As well as the identification of salient attacks and weak points in a prospective system, the proposed method also highlights which factors and security components contribute most to a component's difficulty and attack ranking respectively. A real world scenario is used in which experts were asked to rank a set of technical attacks, and to answer a series of questions about the security components that are the subject of the attacks. The work shows how finding good aggregation operators, and identifying important components and factors of a cyber-security problem can be automated. The resulting operators have the potential for use as decision aids for systems designers and cyber-security experts, increasing the amount of assessment that can be achieved with the limited resources available.
Supervised Adverse Drug Reaction Signalling Framework Imitating Bradford Hill's Causality Considerations
Jul 21, 2016
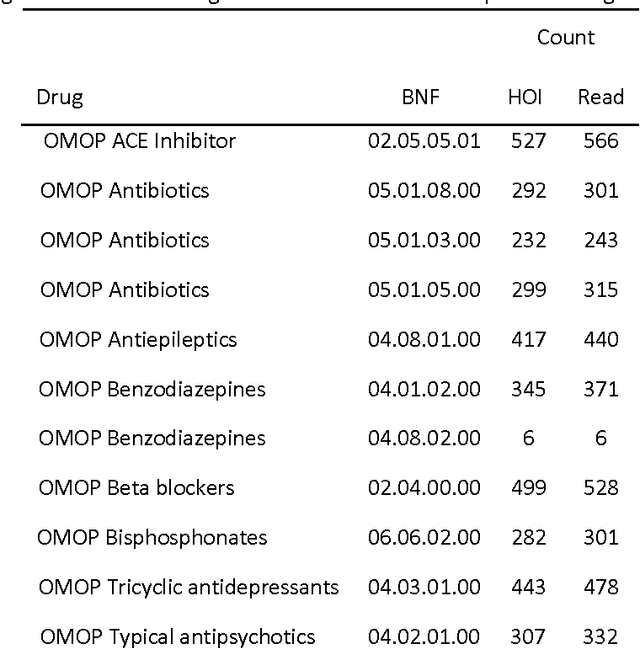

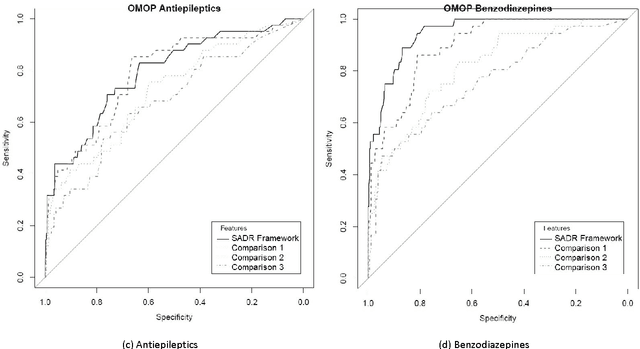
Big longitudinal observational medical data potentially hold a wealth of information and have been recognised as potential sources for gaining new drug safety knowledge. Unfortunately there are many complexities and underlying issues when analysing longitudinal observational data. Due to these complexities, existing methods for large-scale detection of negative side effects using observational data all tend to have issues distinguishing between association and causality. New methods that can better discriminate causal and non-causal relationships need to be developed to fully utilise the data. In this paper we propose using a set of causality considerations developed by the epidemiologist Bradford Hill as a basis for engineering features that enable the application of supervised learning for the problem of detecting negative side effects. The Bradford Hill considerations look at various perspectives of a drug and outcome relationship to determine whether it shows causal traits. We taught a classifier to find patterns within these perspectives and it learned to discriminate between association and causality. The novelty of this research is the combination of supervised learning and Bradford Hill's causality considerations to automate the Bradford Hill's causality assessment. We evaluated the framework on a drug safety gold standard know as the observational medical outcomes partnership's nonspecified association reference set. The methodology obtained excellent discriminate ability with area under the curves ranging between 0.792-0.940 (existing method optimal: 0.73) and a mean average precision of 0.640 (existing method optimal: 0.141). The proposed features can be calculated efficiently and be readily updated, making the framework suitable for big observational data.
Juxtaposition of System Dynamics and Agent-based Simulation for a Case Study in Immunosenescence
Jul 20, 2016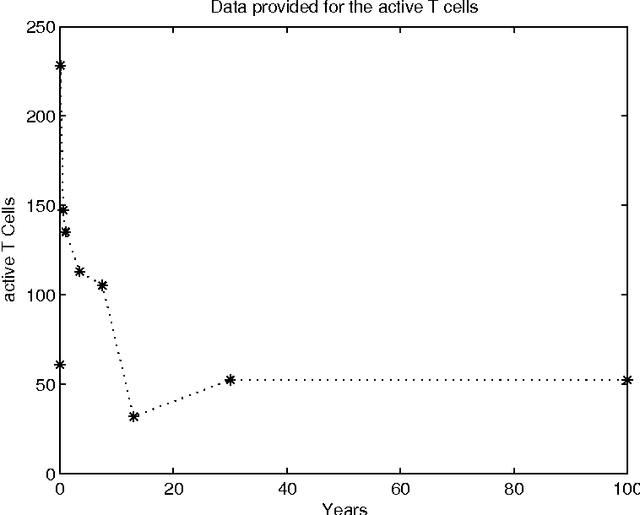

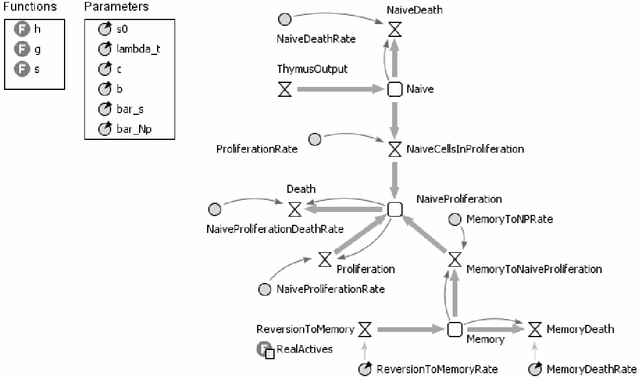

Advances in healthcare and in the quality of life significantly increase human life expectancy. With the ageing of populations, new un-faced challenges are brought to science. The human body is naturally selected to be well-functioning until the age of reproduction to keep the species alive. However, as the lifespan extends, unseen problems due to the body deterioration emerge. There are several age-related diseases with no appropriate treatment; therefore, the complex ageing phenomena needs further understanding. Immunosenescence, the ageing of the immune system, is highly correlated to the negative effects of ageing, such as the increase of auto-inflammatory diseases and decrease in responsiveness to new diseases. Besides clinical and mathematical tools, we believe there is opportunity to further exploit simulation tools to understand immunosenescence. Compared to real-world experimentation, benefits include time and cost effectiveness due to the laborious, resource-intensiveness of the biological environment and the possibility of conducting experiments without ethic restrictions. Contrasted with mathematical models, simulation modelling is more suitable for representing complex systems and emergence. In addition, there is the belief that simulation models are easier to communicate in interdisciplinary contexts. Our work investigates the usefulness of simulations to understand immunosenescence by employing two different simulation methods, agent-based and system dynamics simulation, to a case study of immune cells depletion with age.