 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd to End AI System for Surgical Gesture Sequence Recognition and Clinical Outcome Prediction
Nov 14, 2025Fine-grained analysis of intraoperative behavior and its impact on patient outcomes remain a longstanding challenge. We present Frame-to-Outcome (F2O), an end-to-end system that translates tissue dissection videos into gesture sequences and uncovers patterns associated with postoperative outcomes. Leveraging transformer-based spatial and temporal modeling and frame-wise classification, F2O robustly detects consecutive short (~2 seconds) gestures in the nerve-sparing step of robot-assisted radical prostatectomy (AUC: 0.80 frame-level; 0.81 video-level). F2O-derived features (gesture frequency, duration, and transitions) predicted postoperative outcomes with accuracy comparable to human annotations (0.79 vs. 0.75; overlapping 95% CI). Across 25 shared features, effect size directions were concordant with small differences (~ 0.07), and strong correlation (r = 0.96, p < 1e-14). F2O also captured key patterns linked to erectile function recovery, including prolonged tissue peeling and reduced energy use. By enabling automatic interpretable assessment, F2O establishes a foundation for data-driven surgical feedback and prospective clinical decision support.
MrRegNet: Multi-resolution Mask Guided Convolutional Neural Network for Medical Image Registration with Large Deformations
May 16, 2024



Deformable image registration (alignment) is highly sought after in numerous clinical applications, such as computer aided diagnosis and disease progression analysis. Deep Convolutional Neural Network (DCNN)-based image registration methods have demonstrated advantages in terms of registration accuracy and computational speed. However, while most methods excel at global alignment, they often perform worse in aligning local regions. To address this challenge, this paper proposes a mask-guided encoder-decoder DCNN-based image registration method, named as MrRegNet. This approach employs a multi-resolution encoder for feature extraction and subsequently estimates multi-resolution displacement fields in the decoder to handle the substantial deformation of images. Furthermore, segmentation masks are employed to direct the model's attention toward aligning local regions. The results show that the proposed method outperforms traditional methods like Demons and a well-known deep learning method, VoxelMorph, on a public 3D brain MRI dataset (OASIS) and a local 2D brain MRI dataset with large deformations. Importantly, the image alignment accuracies are significantly improved at local regions guided by segmentation masks. Github link:https://github.com/ruizhe-l/MrRegNet.
Gradient-based Fuzzy System Optimisation via Automatic Differentiation -- FuzzyR as a Use Case
Mar 18, 2024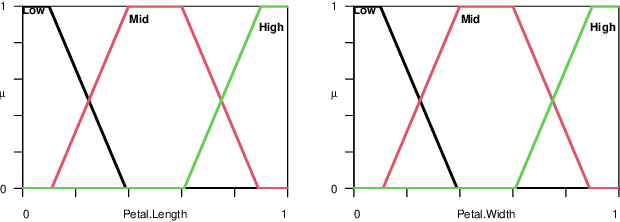
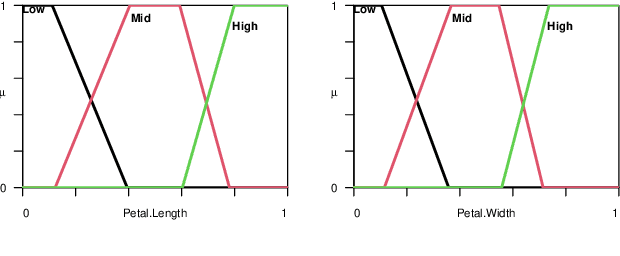

Since their introduction, fuzzy sets and systems have become an important area of research known for its versatility in modelling, knowledge representation and reasoning, and increasingly its potential within the context explainable AI. While the applications of fuzzy systems are diverse, there has been comparatively little advancement in their design from a machine learning perspective. In other words, while representations such as neural networks have benefited from a boom in learning capability driven by an increase in computational performance in combination with advances in their training mechanisms and available tool, in particular gradient descent, the impact on fuzzy system design has been limited. In this paper, we discuss gradient-descent-based optimisation of fuzzy systems, focussing in particular on automatic differentiation -- crucial to neural network learning -- with a view to free fuzzy system designers from intricate derivative computations, allowing for more focus on the functional and explainability aspects of their design. As a starting point, we present a use case in FuzzyR which demonstrates how current fuzzy inference system implementations can be adjusted to leverage powerful features of automatic differentiation tools sets, discussing its potential for the future of fuzzy system design.
The Energy Prediction Smart-Meter Dataset: Analysis of Previous Competitions and Beyond
Nov 07, 2023



This paper presents the real-world smart-meter dataset and offers an analysis of solutions derived from the Energy Prediction Technical Challenges, focusing primarily on two key competitions: the IEEE Computational Intelligence Society (IEEE-CIS) Technical Challenge on Energy Prediction from Smart Meter data in 2020 (named EP) and its follow-up challenge at the IEEE International Conference on Fuzzy Systems (FUZZ-IEEE) in 2021 (named as XEP). These competitions focus on accurate energy consumption forecasting and the importance of interpretability in understanding the underlying factors. The challenge aims to predict monthly and yearly estimated consumption for households, addressing the accurate billing problem with limited historical smart meter data. The dataset comprises 3,248 smart meters, with varying data availability ranging from a minimum of one month to a year. This paper delves into the challenges, solutions and analysing issues related to the provided real-world smart meter data, developing accurate predictions at the household level, and introducing evaluation criteria for assessing interpretability. Additionally, this paper discusses aspects beyond the competitions: opportunities for energy disaggregation and pattern detection applications at the household level, significance of communicating energy-driven factors for optimised billing, and emphasising the importance of responsible AI and data privacy considerations. These aspects provide insights into the broader implications and potential advancements in energy consumption prediction. Overall, these competitions provide a dataset for residential energy research and serve as a catalyst for exploring accurate forecasting, enhancing interpretability, and driving progress towards the discussion of various aspects such as energy disaggregation, demand response programs or behavioural interventions.
The Joint Weighted Average (JWA) Operator
Feb 23, 2023Information aggregation is a vital tool for human and machine decision making, especially in the presence of noise and uncertainty. Traditionally, approaches to aggregation broadly diverge into two categories, those which attribute a worth or weight to information sources and those which attribute said worth to the evidence arising from said sources. The latter is pervasive in particular in the physical sciences, underpinning linear order statistics and enabling non-linear aggregation. The former is popular in the social sciences, providing interpretable insight on the sources. Thus far, limited work has sought to integrate both approaches, applying either approach to a different degree. In this paper, we put forward an approach which integrates--rather than partially applies--both approaches, resulting in a novel joint weighted averaging operator. We show how this operator provides a systematic approach to integrating a priori beliefs about the worth of both source and evidence by leveraging compositional geometry--producing results unachievable by traditional operators. We conclude and highlight the potential of the operator across disciplines, from machine learning to psychology.
Quantification of Robotic Surgeries with Vision-Based Deep Learning
May 06, 2022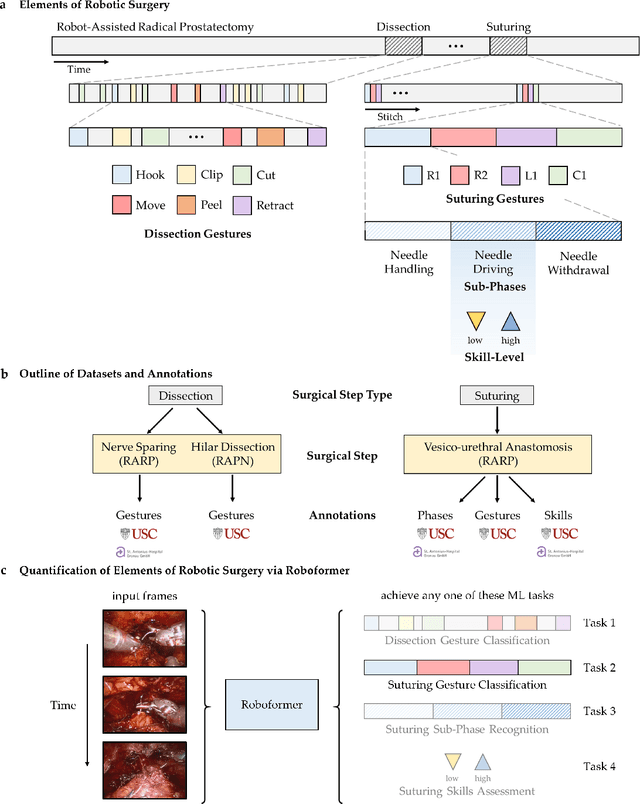
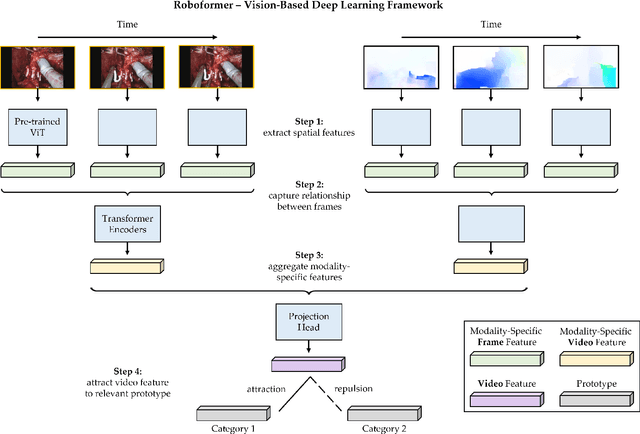
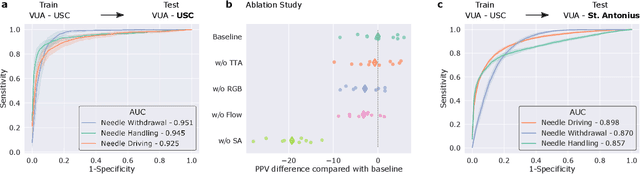
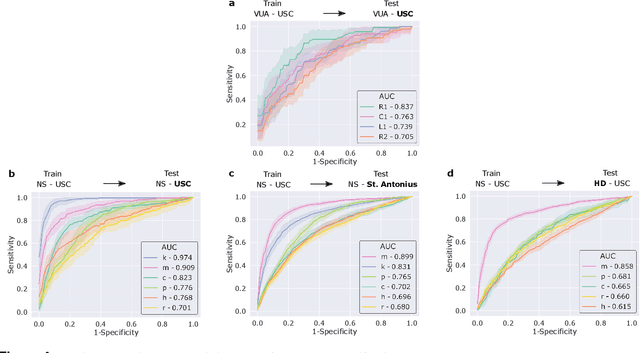
Surgery is a high-stakes domain where surgeons must navigate critical anatomical structures and actively avoid potential complications while achieving the main task at hand. Such surgical activity has been shown to affect long-term patient outcomes. To better understand this relationship, whose mechanics remain unknown for the majority of surgical procedures, we hypothesize that the core elements of surgery must first be quantified in a reliable, objective, and scalable manner. We believe this is a prerequisite for the provision of surgical feedback and modulation of surgeon performance in pursuit of improved patient outcomes. To holistically quantify surgeries, we propose a unified deep learning framework, entitled Roboformer, which operates exclusively on videos recorded during surgery to independently achieve multiple tasks: surgical phase recognition (the what of surgery), gesture classification and skills assessment (the how of surgery). We validated our framework on four video-based datasets of two commonly-encountered types of steps (dissection and suturing) within minimally-invasive robotic surgeries. We demonstrated that our framework can generalize well to unseen videos, surgeons, medical centres, and surgical procedures. We also found that our framework, which naturally lends itself to explainable findings, identified relevant information when achieving a particular task. These findings are likely to instill surgeons with more confidence in our framework's behaviour, increasing the likelihood of clinical adoption, and thus paving the way for more targeted surgical feedback.
Image Augmentation Using a Task Guided Generative Adversarial Network for Age Estimation on Brain MRI
Aug 03, 2021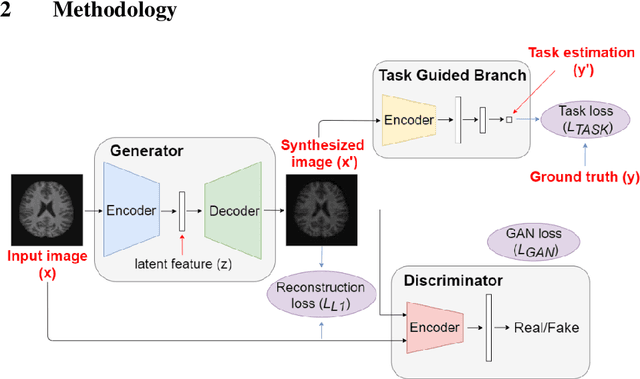


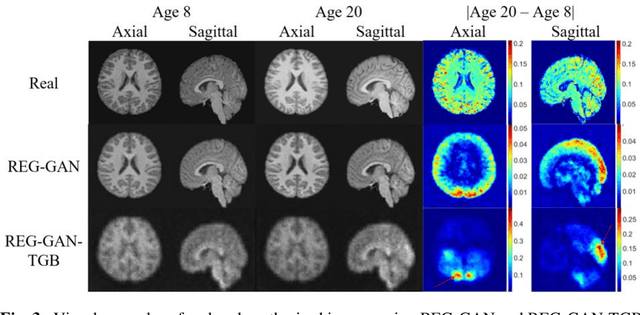
Brain age estimation based on magnetic resonance imaging (MRI) is an active research area in early diagnosis of some neurodegenerative diseases (e.g. Alzheimer, Parkinson, Huntington, etc.) for elderly people or brain underdevelopment for the young group. Deep learning methods have achieved the state-of-the-art performance in many medical image analysis tasks, including brain age estimation. However, the performance and generalisability of the deep learning model are highly dependent on the quantity and quality of the training data set. Both collecting and annotating brain MRI data are extremely time-consuming. In this paper, to overcome the data scarcity problem, we propose a generative adversarial network (GAN) based image synthesis method. Different from the existing GAN-based methods, we integrate a task-guided branch (a regression model for age estimation) to the end of the generator in GAN. By adding a task-guided loss to the conventional GAN loss, the learned low-dimensional latent space and the synthesised images are more task-specific. It helps to boost the performance of the down-stream task by combining the synthesised images and real images for model training. The proposed method was evaluated on a public brain MRI data set for age estimation. Our proposed method outperformed (statistically significant) a deep convolutional neural network based regression model and the GAN-based image synthesis method without the task-guided branch. More importantly, it enables the identification of age-related brain regions in the image space. The code is available on GitHub (https://github.com/ruizhe-l/tgb-gan).
Towards Handling Uncertainty-at-Source in AI -- A Review and Next Steps for Interval Regression
Apr 15, 2021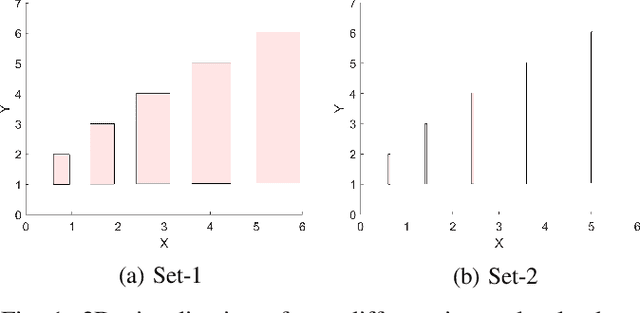
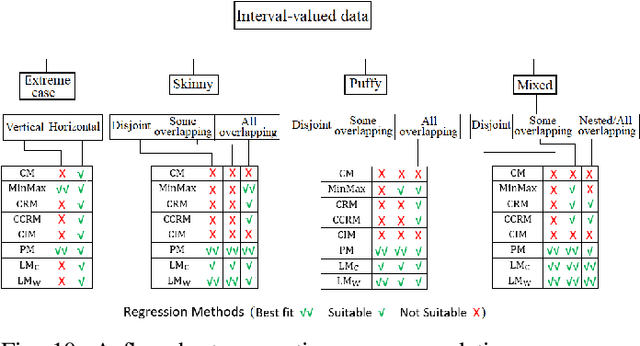
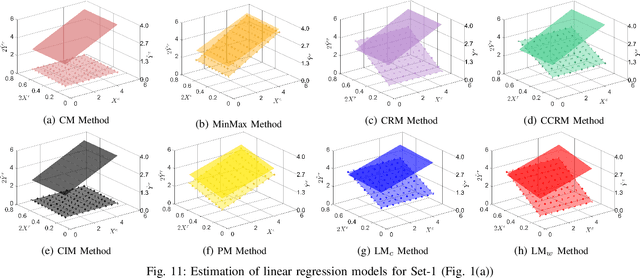
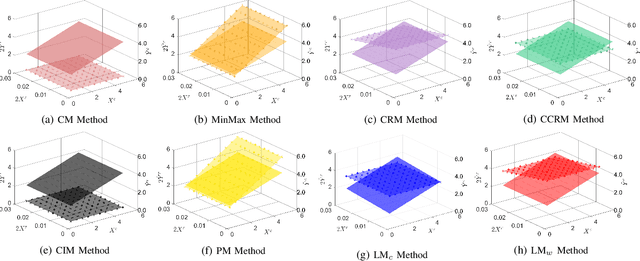
Most of statistics and AI draw insights through modelling discord or variance between sources of information (i.e., inter-source uncertainty). Increasingly, however, research is focusing upon uncertainty arising at the level of individual measurements (i.e., within- or intra-source), such as for a given sensor output or human response. Here, adopting intervals rather than numbers as the fundamental data-type provides an efficient, powerful, yet challenging way forward -- offering systematic capture of uncertainty-at-source, increasing informational capacity, and ultimately potential for insight. Following recent progress in the capture of interval-valued data, including from human participants, conducting machine learning directly upon intervals is a crucial next step. This paper focuses on linear regression for interval-valued data as a recent growth area, providing an essential foundation for broader use of intervals in AI. We conduct an in-depth analysis of state-of-the-art methods, elucidating their behaviour, advantages, and pitfalls when applied to datasets with different properties. Specific emphasis is given to the challenge of preserving mathematical coherence -- i.e., ensuring that models maintain fundamental mathematical properties of intervals throughout -- and the paper puts forward extensions to an existing approach to guarantee this. Carefully designed experiments, using both synthetic and real-world data, are conducted -- with findings presented alongside novel visualizations for interval-valued regression outputs, designed to maximise model interpretability. Finally, the paper makes recommendations concerning method suitability for data sets with specific properties and highlights remaining challenges and important next steps for developing AI with the capacity to handle uncertainty-at-source.
A generic ensemble based deep convolutional neural network for semi-supervised medical image segmentation
Apr 16, 2020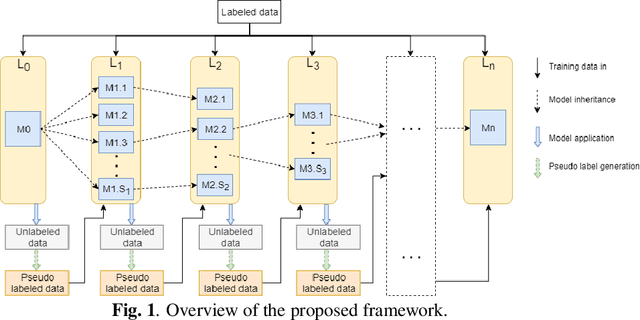
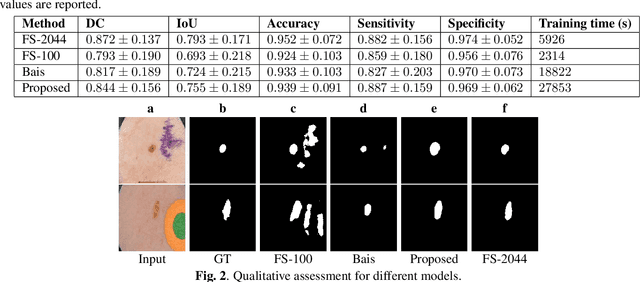
Deep learning based image segmentation has achieved the state-of-the-art performance in many medical applications such as lesion quantification, organ detection, etc. However, most of the methods rely on supervised learning, which require a large set of high-quality labeled data. Data annotation is generally an extremely time-consuming process. To address this problem, we propose a generic semi-supervised learning framework for image segmentation based on a deep convolutional neural network (DCNN). An encoder-decoder based DCNN is initially trained using a few annotated training samples. This initially trained model is then copied into sub-models and improved iteratively using random subsets of unlabeled data with pseudo labels generated from models trained in the previous iteration. The number of sub-models is gradually decreased to one in the final iteration. We evaluate the proposed method on a public grand-challenge dataset for skin lesion segmentation. Our method is able to significantly improve beyond fully supervised model learning by incorporating unlabeled data.
* Accepted for publication at IEEE International Symposium on Biomedical Imaging (ISBI) 2020
Autonomous robotic nanofabrication with reinforcement learning
Feb 27, 2020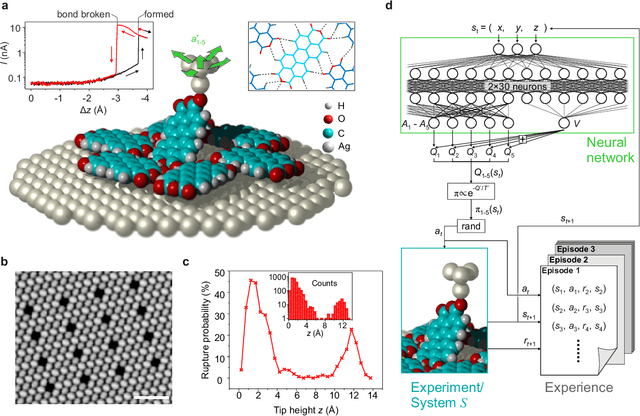
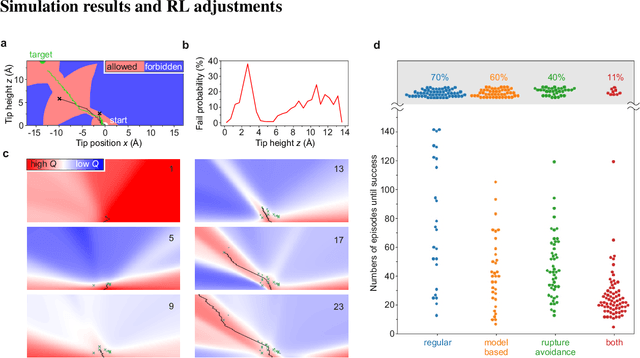
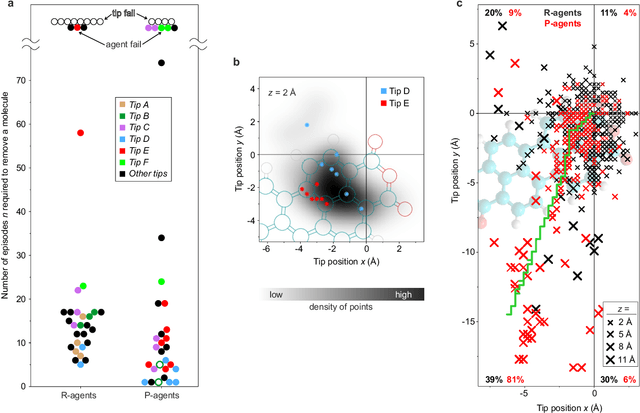
The ability to handle single molecules as effectively as macroscopic building-blocks would enable the construction of complex supramolecular structures that are not accessible by self-assembly. The fundamental challenges on the way towards this goal are the uncontrolled variability and poor observability of atomic-scale conformations. Here, we present a strategy to work around both obstacles, and demonstrate autonomous robotic nanofabrication by manipulating single molecules. Our approach employs reinforcement learning (RL), which is able to learn solution strategies even in the face of large uncertainty and with sparse feedback. However, to be useful for autonomous nanofabrication, standard RL algorithms need to be adapted to cope with the limited training opportunities available. We demonstrate the potential of our RL approach by applying it to an exemplary task of subtractive manufacturing, the removal of individual molecules from a molecular layer using a scanning probe microscope (SPM). Our RL agent reaches an excellent performance level, enabling us to automate a task which previously had to be performed by a human. We anticipate that our work opens the way towards autonomous agents for the robotic construction of functional supramolecular structures with speed, precision and perseverance beyond our current capabilities.