 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed solar generation forecasting using attention-based deep neural networks for cloud movement prediction
Nov 17, 2024



Accurate forecasts of distributed solar generation are necessary to reduce negative impacts resulting from the increased uptake of distributed solar photovoltaic (PV) systems. However, the high variability of solar generation over short time intervals (seconds to minutes) caused by cloud movement makes this forecasting task difficult. To address this, using cloud images, which capture the second-to-second changes in cloud cover affecting solar generation, has shown promise. Recently, deep neural networks with "attention" that focus on important regions of an image have been applied with success in many computer vision applications. However, their use for forecasting cloud movement has not yet been extensively explored. In this work, we propose an attention-based convolutional long short-term memory network to forecast cloud movement and apply an existing self-attention-based method previously proposed for video prediction to forecast cloud movement. We investigate and discuss the impact of cloud forecasts from attention-based methods towards forecasting distributed solar generation, compared to cloud forecasts from non-attention-based methods. We further provide insights into the different solar forecast performances that can be achieved for high and low altitude clouds. We find that for clouds at high altitudes, the cloud predictions obtained using attention-based methods result in solar forecast skill score improvements of 5.86% or more compared to non-attention-based methods.
Day-ahead regional solar power forecasting with hierarchical temporal convolutional neural networks using historical power generation and weather data
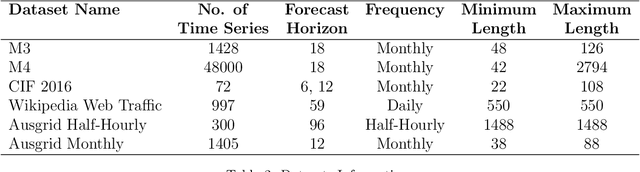
Mar 04, 2024Regional solar power forecasting, which involves predicting the total power generation from all rooftop photovoltaic systems in a region holds significant importance for various stakeholders in the energy sector. However, the vast amount of solar power generation and weather time series from geographically dispersed locations that need to be considered in the forecasting process makes accurate regional forecasting challenging. Therefore, previous work has limited the focus to either forecasting a single time series (i.e., aggregated time series) which is the addition of all solar generation time series in a region, disregarding the location-specific weather effects or forecasting solar generation time series of each PV site (i.e., individual time series) independently using location-specific weather data, resulting in a large number of forecasting models. In this work, we propose two deep-learning-based regional forecasting methods that can effectively leverage both types of time series (aggregated and individual) with weather data in a region. We propose two hierarchical temporal convolutional neural network architectures (HTCNN) and two strategies to adapt HTCNNs for regional solar power forecasting. At first, we explore generating a regional forecast using a single HTCNN. Next, we divide the region into multiple sub-regions based on weather information and train separate HTCNNs for each sub-region; the forecasts of each sub-region are then added to generate a regional forecast. The proposed work is evaluated using a large dataset collected over a year from 101 locations across Western Australia to provide a day ahead forecast. We compare our approaches with well-known alternative methods and show that the sub-region HTCNN requires fewer individual networks and achieves a forecast skill score of 40.2% reducing a statistically significant error by 6.5% compared to the best counterpart.
The Energy Prediction Smart-Meter Dataset: Analysis of Previous Competitions and Beyond
Nov 07, 2023



This paper presents the real-world smart-meter dataset and offers an analysis of solutions derived from the Energy Prediction Technical Challenges, focusing primarily on two key competitions: the IEEE Computational Intelligence Society (IEEE-CIS) Technical Challenge on Energy Prediction from Smart Meter data in 2020 (named EP) and its follow-up challenge at the IEEE International Conference on Fuzzy Systems (FUZZ-IEEE) in 2021 (named as XEP). These competitions focus on accurate energy consumption forecasting and the importance of interpretability in understanding the underlying factors. The challenge aims to predict monthly and yearly estimated consumption for households, addressing the accurate billing problem with limited historical smart meter data. The dataset comprises 3,248 smart meters, with varying data availability ranging from a minimum of one month to a year. This paper delves into the challenges, solutions and analysing issues related to the provided real-world smart meter data, developing accurate predictions at the household level, and introducing evaluation criteria for assessing interpretability. Additionally, this paper discusses aspects beyond the competitions: opportunities for energy disaggregation and pattern detection applications at the household level, significance of communicating energy-driven factors for optimised billing, and emphasising the importance of responsible AI and data privacy considerations. These aspects provide insights into the broader implications and potential advancements in energy consumption prediction. Overall, these competitions provide a dataset for residential energy research and serve as a catalyst for exploring accurate forecasting, enhancing interpretability, and driving progress towards the discussion of various aspects such as energy disaggregation, demand response programs or behavioural interventions.
Handling Concept Drift in Global Time Series Forecasting
Apr 04, 2023



Machine learning (ML) based time series forecasting models often require and assume certain degrees of stationarity in the data when producing forecasts. However, in many real-world situations, the data distributions are not stationary and they can change over time while reducing the accuracy of the forecasting models, which in the ML literature is known as concept drift. Handling concept drift in forecasting is essential for many ML methods in use nowadays, however, the prior work only proposes methods to handle concept drift in the classification domain. To fill this gap, we explore concept drift handling methods in particular for Global Forecasting Models (GFM) which recently have gained popularity in the forecasting domain. We propose two new concept drift handling methods, namely: Error Contribution Weighting (ECW) and Gradient Descent Weighting (GDW), based on a continuous adaptive weighting concept. These methods use two forecasting models which are separately trained with the most recent series and all series, and finally, the weighted average of the forecasts provided by the two models are considered as the final forecasts. Using LightGBM as the underlying base learner, in our evaluation on three simulated datasets, the proposed models achieve significantly higher accuracy than a set of statistical benchmarks and LightGBM baselines across four evaluation metrics.
A Hybrid Statistical-Machine Learning Approach for Analysing Online Customer Behavior: An Empirical Study
Dec 01, 2022
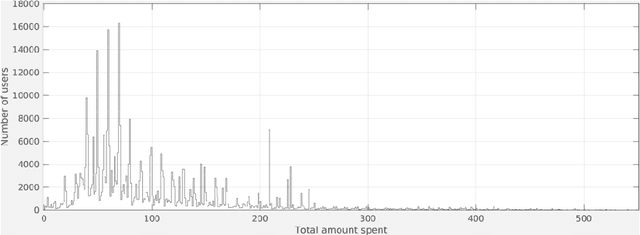


We apply classical statistical methods in conjunction with the state-of-the-art machine learning techniques to develop a hybrid interpretable model to analyse 454,897 online customers' behavior for a particular product category at the largest online retailer in China, that is JD. While most mere machine learning methods are plagued by the lack of interpretability in practice, our novel hybrid approach will address this practical issue by generating explainable output. This analysis involves identifying what features and characteristics have the most significant impact on customers' purchase behavior, thereby enabling us to predict future sales with a high level of accuracy, and identify the most impactful variables. Our results reveal that customers' product choice is insensitive to the promised delivery time, but this factor significantly impacts customers' order quantity. We also show that the effectiveness of various discounting methods depends on the specific product and the discount size. We identify product classes for which certain discounting approaches are more effective and provide recommendations on better use of different discounting tools. Customers' choice behavior across different product classes is mostly driven by price, and to a lesser extent, by customer demographics. The former finding asks for exercising care in deciding when and how much discount should be offered, whereas the latter identifies opportunities for personalized ads and targeted marketing. Further, to curb customers' batch ordering behavior and avoid the undesirable Bullwhip effect, JD should improve its logistics to ensure faster delivery of orders.
Multi-Resolution, Multi-Horizon Distributed Solar PV Power Forecasting with Forecast Combinations
Jun 22, 2022
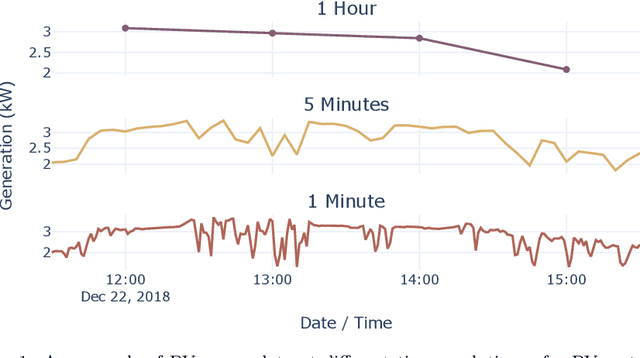
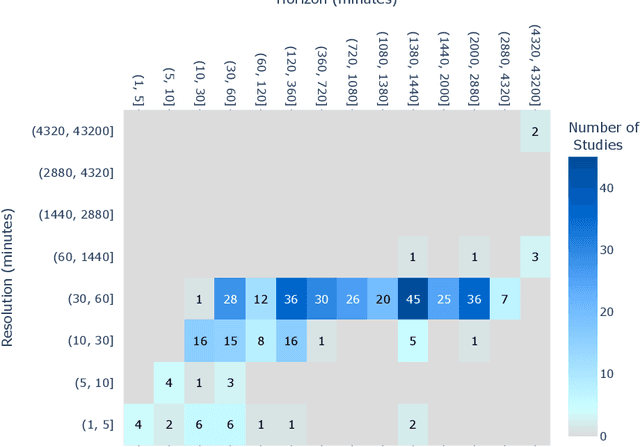
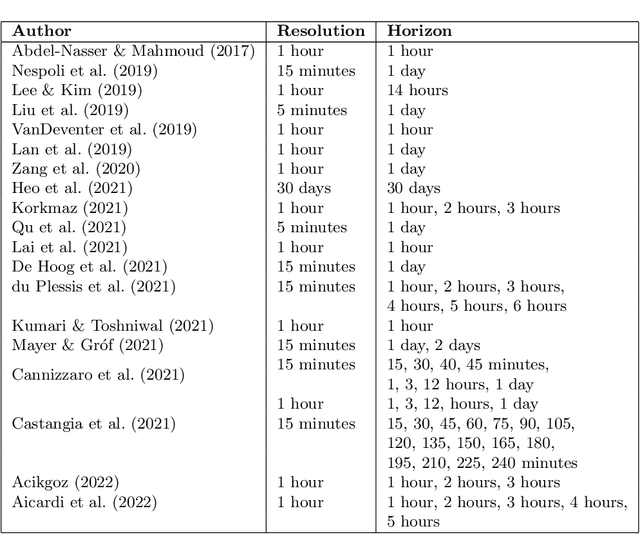
Distributed, small-scale solar photovoltaic (PV) systems are being installed at a rapidly increasing rate. This can cause major impacts on distribution networks and energy markets. As a result, there is a significant need for improved forecasting of the power generation of these systems at different time resolutions and horizons. However, the performance of forecasting models depends on the resolution and horizon. Forecast combinations (ensembles), that combine the forecasts of multiple models into a single forecast may be robust in such cases. Therefore, in this paper, we provide comparisons and insights into the performance of five state-of-the-art forecast models and existing forecast combinations at multiple resolutions and horizons. We propose a forecast combination approach based on particle swarm optimization (PSO) that will enable a forecaster to produce accurate forecasts for the task at hand by weighting the forecasts produced by individual models. Furthermore, we compare the performance of the proposed combination approach with existing forecast combination approaches. A comprehensive evaluation is conducted using a real-world residential PV power data set measured at 25 houses located in three locations in the United States. The results across four different resolutions and four different horizons show that the PSO-based forecast combination approach outperforms the use of any individual forecast model and other forecast combination counterparts, with an average Mean Absolute Scaled Error reduction by 3.81% compared to the best performing individual model. Our approach enables a solar forecaster to produce accurate forecasts for their application regardless of the forecast resolution or horizon.
Ensembles of Localised Models for Time Series Forecasting
Dec 30, 2020

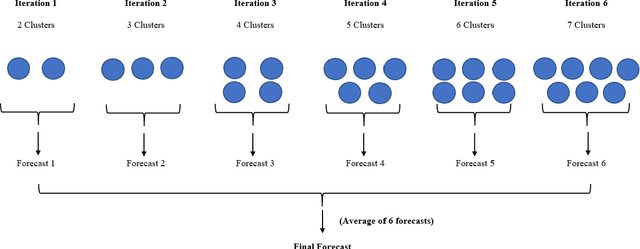
With large quantities of data typically available nowadays, forecasting models that are trained across sets of time series, known as Global Forecasting Models (GFM), are regularly outperforming traditional univariate forecasting models that work on isolated series. As GFMs usually share the same set of parameters across all time series, they often have the problem of not being localised enough to a particular series, especially in situations where datasets are heterogeneous. We study how ensembling techniques can be used with generic GFMs and univariate models to solve this issue. Our work systematises and compares relevant current approaches, namely clustering series and training separate submodels per cluster, the so-called ensemble of specialists approach, and building heterogeneous ensembles of global and local models. We fill some gaps in the approaches and generalise them to different underlying GFM model types. We then propose a new methodology of clustered ensembles where we train multiple GFMs on different clusters of series, obtained by changing the number of clusters and cluster seeds. Using Feed-forward Neural Networks, Recurrent Neural Networks, and Pooled Regression models as the underlying GFMs, in our evaluation on six publicly available datasets, the proposed models are able to achieve significantly higher accuracy than baseline GFM models and univariate forecasting methods.
Global Models for Time Series Forecasting: A Simulation Study
Dec 23, 2020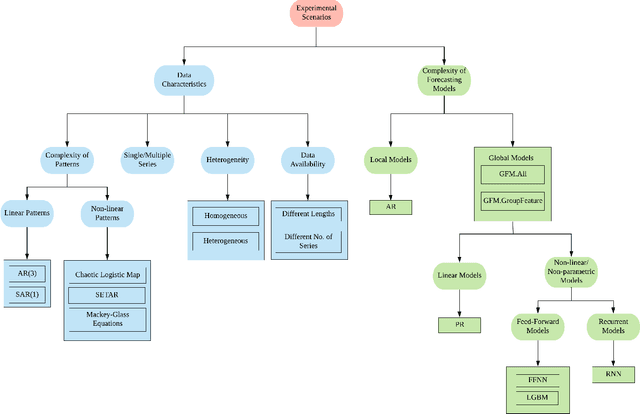
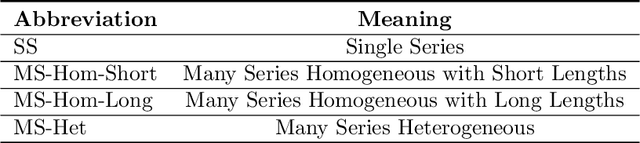
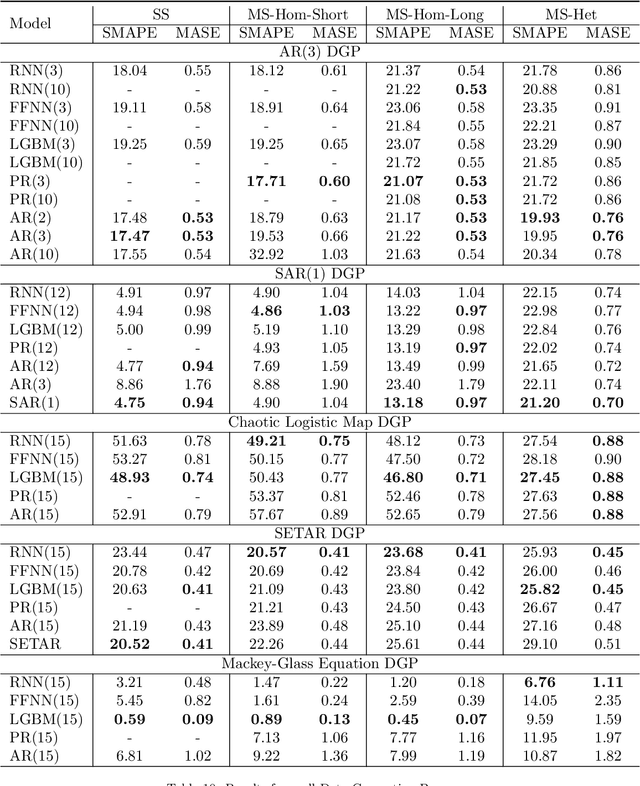
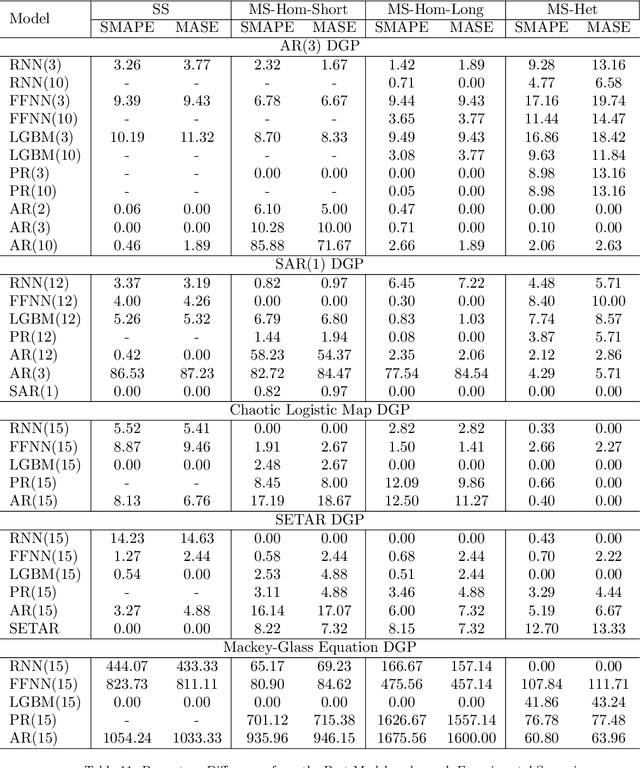
In the current context of Big Data, the nature of many forecasting problems has changed from predicting isolated time series to predicting many time series from similar sources. This has opened up the opportunity to develop competitive global forecasting models that simultaneously learn from many time series. But, it still remains unclear when global forecasting models can outperform the univariate benchmarks, especially along the dimensions of the homogeneity/heterogeneity of series, the complexity of patterns in the series, the complexity of forecasting models, and the lengths/number of series. Our study attempts to address this problem through investigating the effect from these factors, by simulating a number of datasets that have controllable time series characteristics. Specifically, we simulate time series from simple data generating processes (DGP), such as Auto Regressive (AR) and Seasonal AR, to complex DGPs, such as Chaotic Logistic Map, Self-Exciting Threshold Auto-Regressive, and Mackey-Glass Equations. The data heterogeneity is introduced by mixing time series generated from several DGPs into a single dataset. The lengths and the number of series in the dataset are varied in different scenarios. We perform experiments on these datasets using global forecasting models including Recurrent Neural Networks (RNN), Feed-Forward Neural Networks, Pooled Regression (PR) models and Light Gradient Boosting Models (LGBM), and compare their performance against standard statistical univariate forecasting techniques. Our experiments demonstrate that when trained as global forecasting models, techniques such as RNNs and LGBMs, which have complex non-linear modelling capabilities, are competitive methods in general under challenging forecasting scenarios such as series having short lengths, datasets with heterogeneous series and having minimal prior knowledge of the patterns of the series.
Improving the Accuracy of Global Forecasting Models using Time Series Data Augmentation
Aug 06, 2020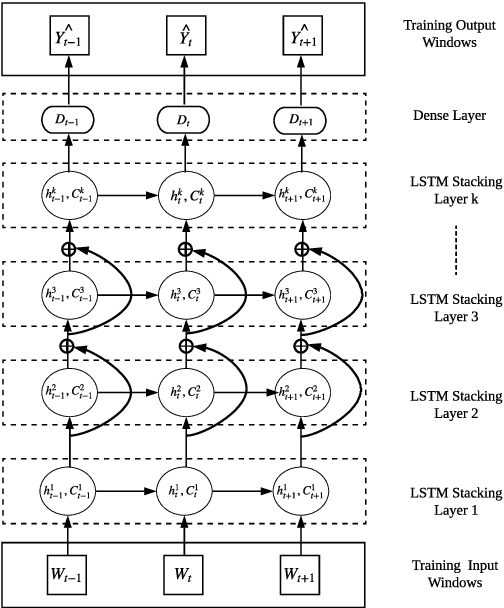
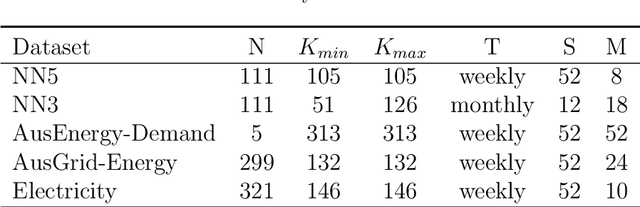
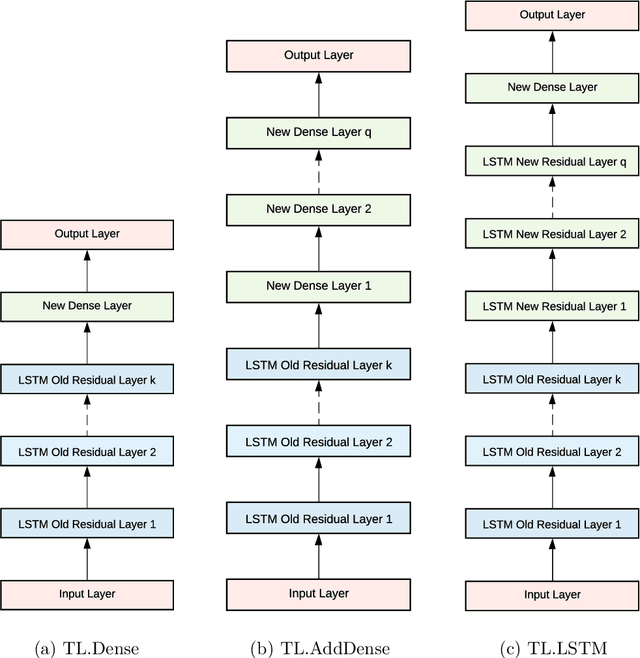

Forecasting models that are trained across sets of many time series, known as Global Forecasting Models (GFM), have shown recently promising results in forecasting competitions and real-world applications, outperforming many state-of-the-art univariate forecasting techniques. In most cases, GFMs are implemented using deep neural networks, and in particular Recurrent Neural Networks (RNN), which require a sufficient amount of time series to estimate their numerous model parameters. However, many time series databases have only a limited number of time series. In this study, we propose a novel, data augmentation based forecasting framework that is capable of improving the baseline accuracy of the GFM models in less data-abundant settings. We use three time series augmentation techniques: GRATIS, moving block bootstrap (MBB), and dynamic time warping barycentric averaging (DBA) to synthetically generate a collection of time series. The knowledge acquired from these augmented time series is then transferred to the original dataset using two different approaches: the pooled approach and the transfer learning approach. When building GFMs, in the pooled approach, we train a model on the augmented time series alongside the original time series dataset, whereas in the transfer learning approach, we adapt a pre-trained model to the new dataset. In our evaluation on competition and real-world time series datasets, our proposed variants can significantly improve the baseline accuracy of GFM models and outperform state-of-the-art univariate forecasting methods.
Towards Accurate Predictions and Causal 'What-if' Analyses for Planning and Policy-making: A Case Study in Emergency Medical Services Demand
Apr 25, 2020


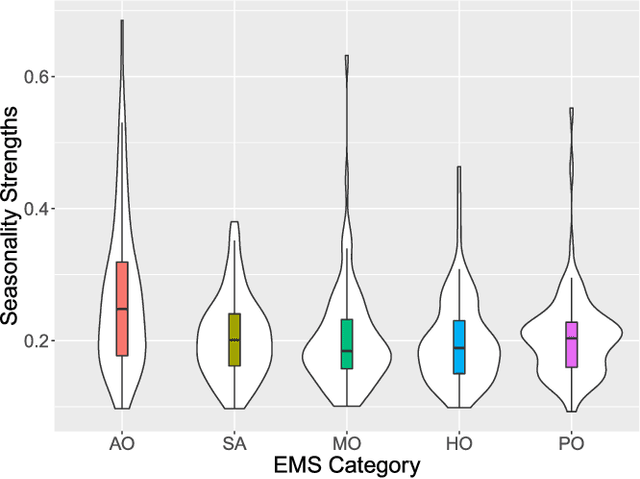
Emergency Medical Services (EMS) demand load has become a considerable burden for many government authorities, and EMS demand is often an early indicator for stress in communities, a warning sign of emerging problems. In this paper, we introduce Deep Planning and Policy Making Net (DeepPPMNet), a Long Short-Term Memory network based, global forecasting and inference framework to forecast the EMS demand, analyse causal relationships, and perform `what-if' analyses for policy-making across multiple local government areas. Unless traditional univariate forecasting techniques, the proposed method follows the global forecasting methodology, where a model is trained across all the available EMS demand time series to exploit the potential cross-series information available. DeepPPMNet also uses seasonal decomposition techniques, incorporated in two different training paradigms into the framework, to suit various characteristics of the EMS related time series data. We then explore causal relationships using the notion of Granger Causality, where the global forecasting framework enables us to perform `what-if' analyses that could be used for the national policy-making process. We empirically evaluate our method, using a set of EMS datasets related to alcohol, drug use and self-harm in Australia. The proposed framework is able to outperform many state-of-the-art techniques and achieve competitive results in terms of forecasting accuracy. We finally illustrate its use for policy-making in an example regarding alcohol outlet licenses.