 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREGAIN: REconciliation GAIN-driven Auxiliary Direction Learning
Jun 03, 2026Forecast reconciliation usually starts from a fixed measurement system and asks how forecasts should be projected onto a coherent space. We ask a different question: which additional linear measurements should be forecast and included in the reconciliation system? We propose REGAIN, a reconciliation-gain framework that learns normalized auxiliary directions, forecasts the induced series with a frozen forecasting oracle, and selects directions by their target-weighted loss reduction after augmented generalized least-squares reconciliation. Unlike variance-based components or predictability-based auxiliary selection, REGAIN optimizes the downstream effect of an auxiliary measurement on the final reconciled forecasts. We provide a statistical characterization showing that useful auxiliary directions must provide complementary information about unresolved target uncertainty, rather than merely being easy to forecast. The analysis also clarifies the covariance-risk reduction mechanism, the role of bias changes in realized quadratic risk, and the stability of estimated gain signals. A stagewise learning algorithm with held-out gain screening is developed, together with an optional joint refinement step. Experiments on Beijing PM2.5 and Australian Tourism data show that gain-selected measurements can improve both ordinary multivariate and hierarchical forecasts, especially when they reveal residual uncertainty not captured by the original measurement system.
Infinite forecast combinations based on Dirichlet process
Nov 24, 2023Forecast combination integrates information from various sources by consolidating multiple forecast results from the target time series. Instead of the need to select a single optimal forecasting model, this paper introduces a deep learning ensemble forecasting model based on the Dirichlet process. Initially, the learning rate is sampled with three basis distributions as hyperparameters to convert the infinite mixture into a finite one. All checkpoints are collected to establish a deep learning sub-model pool, and weight adjustment and diversity strategies are developed during the combination process. The main advantage of this method is its ability to generate the required base learners through a single training process, utilizing the decaying strategy to tackle the challenge posed by the stochastic nature of gradient descent in determining the optimal learning rate. To ensure the method's generalizability and competitiveness, this paper conducts an empirical analysis using the weekly dataset from the M4 competition and explores sensitivity to the number of models to be combined. The results demonstrate that the ensemble model proposed offers substantial improvements in prediction accuracy and stability compared to a single benchmark model.
Probabilistic Forecast Reconciliation with Kullback-Leibler Divergence Regularization
Nov 21, 2023As the popularity of hierarchical point forecast reconciliation methods increases, there is a growing interest in probabilistic forecast reconciliation. Many studies have utilized machine learning or deep learning techniques to implement probabilistic forecasting reconciliation and have made notable progress. However, these methods treat the reconciliation step as a fixed and hard post-processing step, leading to a trade-off between accuracy and coherency. In this paper, we propose a new approach for probabilistic forecast reconciliation. Unlike existing approaches, our proposed approach fuses the prediction step and reconciliation step into a deep learning framework, making the reconciliation step more flexible and soft by introducing the Kullback-Leibler divergence regularization term into the loss function. The approach is evaluated using three hierarchical time series datasets, which shows the advantages of our approach over other probabilistic forecast reconciliation methods.
Forecasting large collections of time series: feature-based methods
Sep 25, 2023

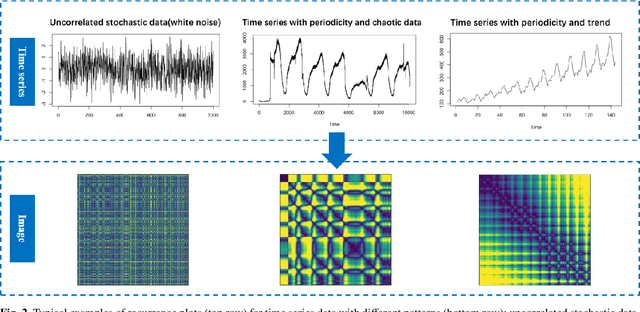
In economics and many other forecasting domains, the real world problems are too complex for a single model that assumes a specific data generation process. The forecasting performance of different methods changes depending on the nature of the time series. When forecasting large collections of time series, two lines of approaches have been developed using time series features, namely feature-based model selection and feature-based model combination. This chapter discusses the state-of-the-art feature-based methods, with reference to open-source software implementations.
Comparison and Evaluation of Methods for a Predict+Optimize Problem in Renewable Energy
Dec 21, 2022
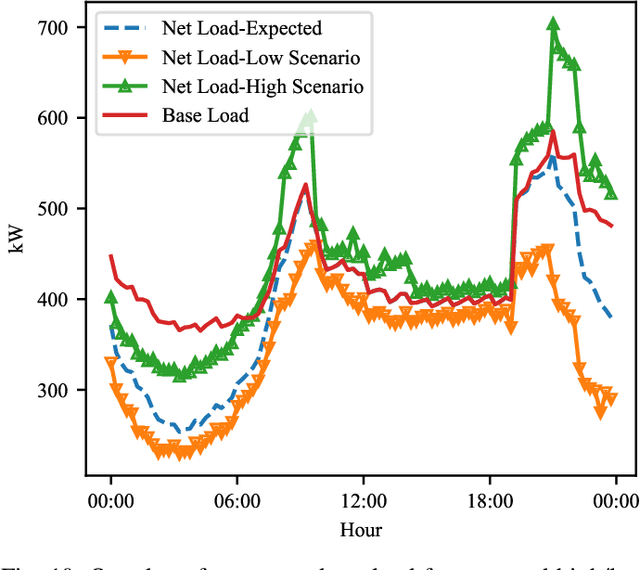
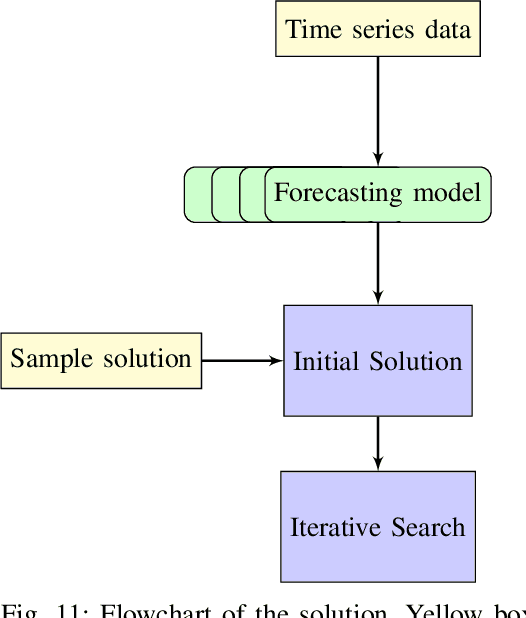
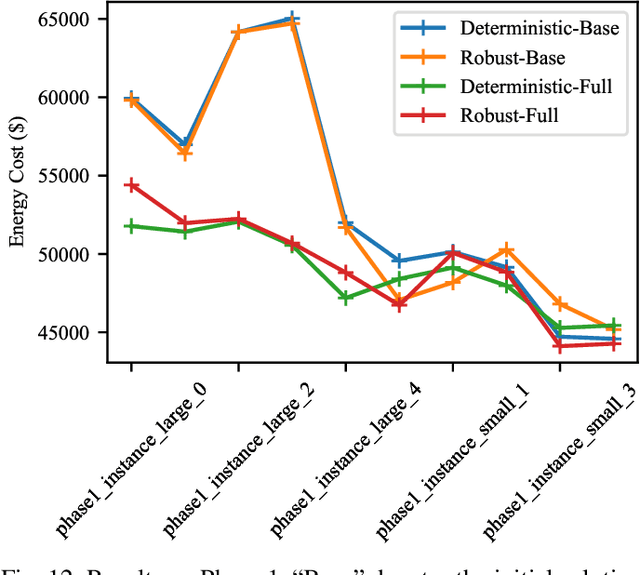
Algorithms that involve both forecasting and optimization are at the core of solutions to many difficult real-world problems, such as in supply chains (inventory optimization), traffic, and in the transition towards carbon-free energy generation in battery/load/production scheduling in sustainable energy systems. Typically, in these scenarios we want to solve an optimization problem that depends on unknown future values, which therefore need to be forecast. As both forecasting and optimization are difficult problems in their own right, relatively few research has been done in this area. This paper presents the findings of the ``IEEE-CIS Technical Challenge on Predict+Optimize for Renewable Energy Scheduling," held in 2021. We present a comparison and evaluation of the seven highest-ranked solutions in the competition, to provide researchers with a benchmark problem and to establish the state of the art for this benchmark, with the aim to foster and facilitate research in this area. The competition used data from the Monash Microgrid, as well as weather data and energy market data. It then focused on two main challenges: forecasting renewable energy production and demand, and obtaining an optimal schedule for the activities (lectures) and on-site batteries that lead to the lowest cost of energy. The most accurate forecasts were obtained by gradient-boosted tree and random forest models, and optimization was mostly performed using mixed integer linear and quadratic programming. The winning method predicted different scenarios and optimized over all scenarios jointly using a sample average approximation method.
Forecast combinations: an over 50-year review
May 09, 2022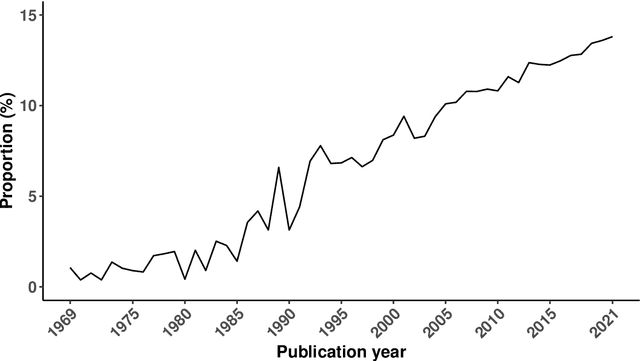
Forecast combinations have flourished remarkably in the forecasting community and, in recent years, have become part of the mainstream of forecasting research and activities. Combining multiple forecasts produced from the single (target) series is now widely used to improve accuracy through the integration of information gleaned from different sources, thereby mitigating the risk of identifying a single "best" forecast. Combination schemes have evolved from simple combination methods without estimation, to sophisticated methods involving time-varying weights, nonlinear combinations, correlations among components, and cross-learning. They include combining point forecasts, and combining probabilistic forecasts. This paper provides an up-to-date review of the extensive literature on forecast combinations, together with reference to available open-source software implementations. We discuss the potential and limitations of various methods and highlight how these ideas have developed over time. Some important issues concerning the utility of forecast combinations are also surveyed. Finally, we conclude with current research gaps and potential insights for future research.
Optimal reconciliation with immutable forecasts
Apr 20, 2022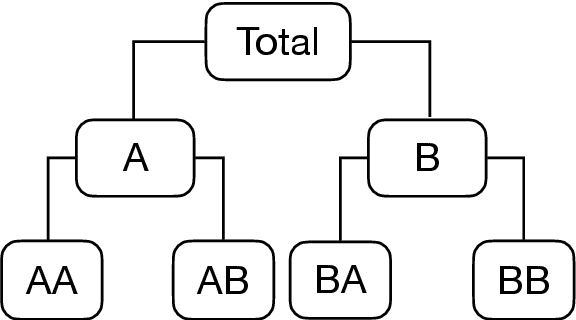

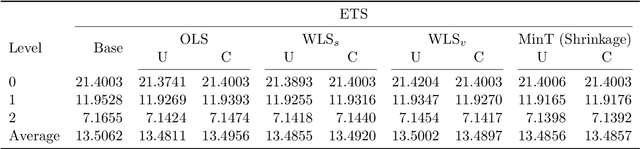
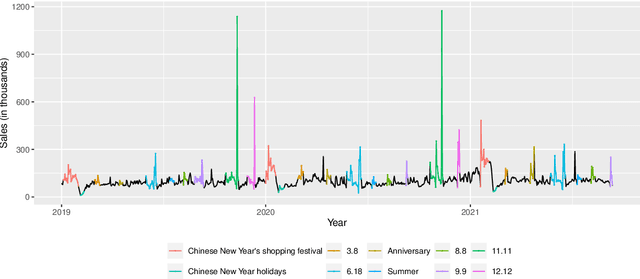
The practical importance of coherent forecasts in hierarchical forecasting has inspired many studies on forecast reconciliation. Under this approach, so-called base forecasts are produced for every series in the hierarchy and are subsequently adjusted to be coherent in a second reconciliation step. Reconciliation methods have been shown to improve forecast accuracy, but will, in general, adjust the base forecast of every series. However, in an operational context, it is sometimes necessary or beneficial to keep forecasts of some variables unchanged after forecast reconciliation. In this paper, we formulate reconciliation methodology that keeps forecasts of a pre-specified subset of variables unchanged or "immutable". In contrast to existing approaches, these immutable forecasts need not all come from the same level of a hierarchy, and our method can also be applied to grouped hierarchies. We prove that our approach preserves unbiasedness in base forecasts. Our method can also account for correlations between base forecasting errors and ensure non-negativity of forecasts. We also perform empirical experiments, including an application to sales of a large scale online retailer, to assess the impacts of our proposed methodology.
Enhancing the Diversity of Predictions Combination by Negative Correlation Learning
Apr 06, 2021

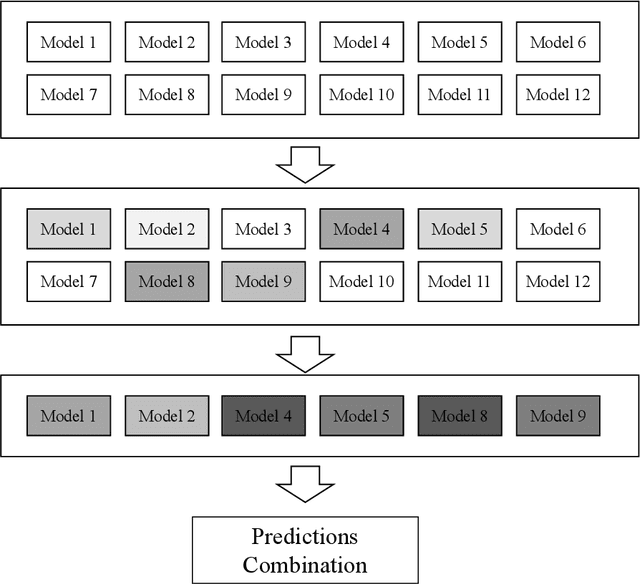
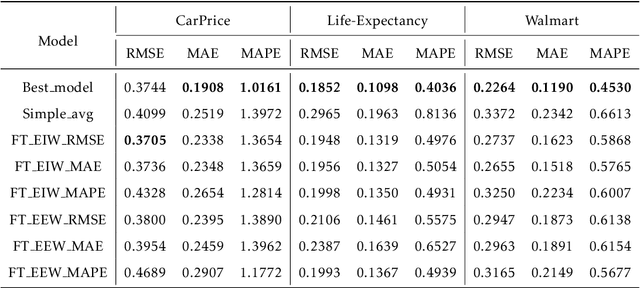
Predictions combination, as a combination model approach with adjustments in the output space, has flourished in recent years in research and competitions. Simple average is intuitive and robust, and is often used as a benchmark in predictions combination. However, some poorly performing sub-models can reduce the overall accuracy because the sub-models are not selected in advance. Even though some studies have selected the top sub-models for the combination after ranking them by mean square error, the covariance of them causes this approach to not yield much benefit. In this paper, we suggest to consider the diversity of sub-models in the predictions combination, which can be adopted to assist in selecting the most diverse model subset in the model pool using negative correlation learning. Three publicly available datasets are applied to evaluate the approach. The experimental results not only show the diversity of sub-models in the predictions combination incorporating negative correlation learning, but also produce predictions with accuracy far exceeding that of the simple average benchmark and some weighted average methods. Furthermore, by adjusting the penalty strength for negative correlation, the predictions combination also outperform the best sub-model. The value of this paper lies in its ease of use and effectiveness, allowing the predictions combination to embrace both diversity and accuracy.
Exploring the representativeness of the M5 competition data
Mar 04, 2021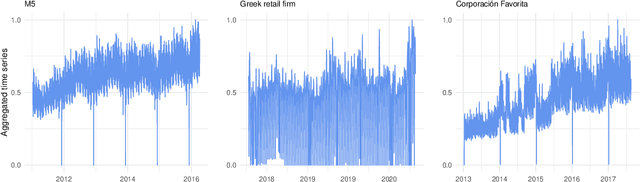

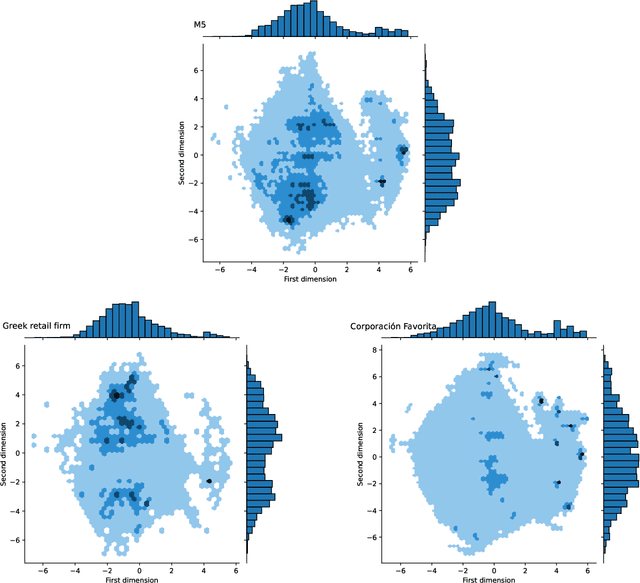
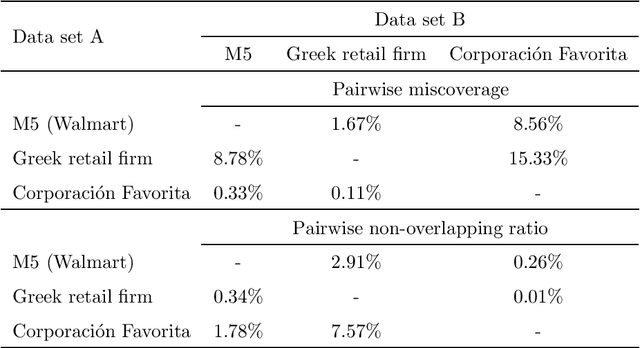
The main objective of the M5 competition, which focused on forecasting the hierarchical unit sales of Walmart, was to evaluate the accuracy and uncertainty of forecasting methods in the field in order to identify best practices and highlight their practical implications. However, whether the findings of the M5 competition can be generalized and exploited by retail firms to better support their decisions and operation depends on the extent to which the M5 data is representative of the reality, i.e., sufficiently represent the unit sales data of retailers that operate in different regions, sell different types of products, and consider different marketing strategies. To answer this question, we analyze the characteristics of the M5 time series and compare them with those of two grocery retailers, namely Corporaci\'on Favorita and a major Greek supermarket chain, using feature spaces. Our results suggest that there are only small discrepancies between the examined data sets, supporting the representativeness of the M5 data.
Exploring the social influence of Kaggle virtual community on the M5 competition
Feb 28, 2021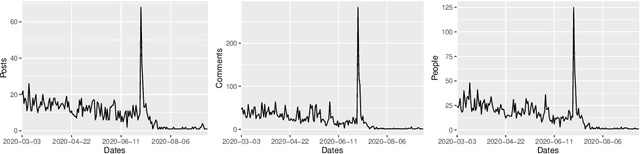
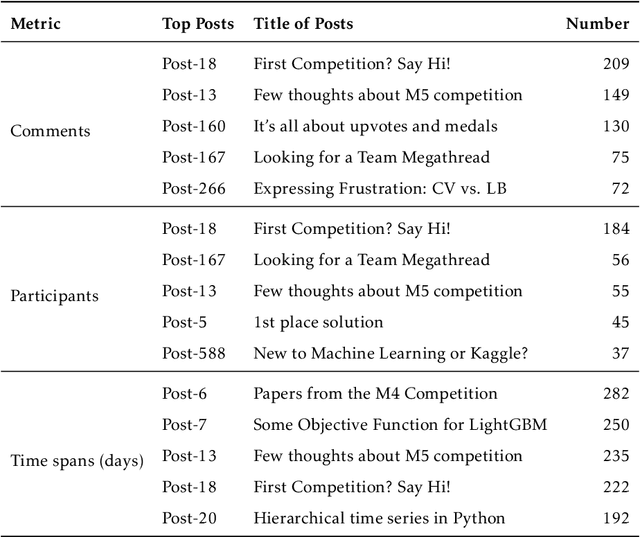
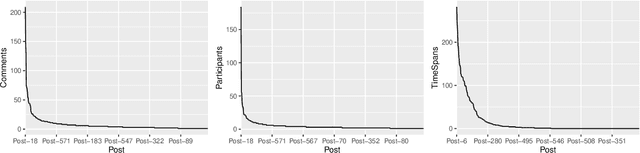

One of the most significant differences of M5 over previous forecasting competitions is that it was held on Kaggle, an online community of data scientists and machine learning practitioners. On the Kaggle platform, people can form virtual communities such as online notebooks and discussions to discuss their models, choice of features, loss functions, etc. This paper aims to study the social influence of virtual communities on the competition. We first study the content of the M5 virtual community by topic modeling and trend analysis. Further, we perform social media analysis to identify the potential relationship network of the virtual community. We find some key roles in the network and study their roles in spreading the LightGBM related information within the network. Overall, this study provides in-depth insights into the dynamic mechanism of the virtual community influence on the participants and has potential implications for future online competitions.