 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongLive-2.0: An NVFP4 Parallel Infrastructure for Long Video Generation
May 19, 2026We present LongLive-2.0, an NVFP4-based parallel infrastructure throughout the full training and inference workflow of long video generation, addressing speed and memory bottlenecks. For training, we introduce sequence-parallel autoregressive (AR) training, instantiated as Balanced SP, which co-designs the efficient teacher-forcing layout with SP execution by pairing clean-history and noisy-target temporal chunks on each rank, enabling a natural teacher-forcing mask with SP-aware chunked VAE encoding. Combined with NVFP4 precision, it reduces GPU memory cost and accelerates GEMM computation during training, the proportion of which increases as video length grows. Moreover, we show that a high-quality infrastructure and dataset enable a remarkably clean training pipeline. Unlike existing Self-Forcing series methods that rely on ODE initialization and subsequent distribution matching distillation (DMD), LongLive-2.0 directly tunes a diffusion model into a long, multi-shot, interactive auto-regressive (AR) diffusion model. It can be further converted to real-time generation (4 to 2 denoising steps) with standalone LoRA weights. For inference on Blackwell GPUs, we enable W4A4 NVFP4 inference, quantize KV cache into NVFP4 for memory savings, and boost end-to-end throughput with asynchronous streaming VAE decoding. On non-Blackwell GPU architectures, we deploy SP inference to match the speed on Blackwell GPUs, while the quantized KV cache can lower inter-GPU communication of SP. Experiments show up to 2.15x speedup in training, and 1.84x in inference. LongLive-2.0-5B achieves 45.7 FPS inference while attaining strong performance on benchmarks. To our knowledge, LongLive-2.0 is the first NVFP4 training and inference system for long video generation.
PACO: Proxy-Task Alignment and Online Calibration for On-the-Fly Category Discovery
Apr 13, 2026On-the-Fly Category Discovery (OCD) requires a model, trained on an offline support set, to recognize known classes while discovering new ones from an online streaming sequence. Existing methods focus heavily on offline training. They aim to learn discriminative representations on the support set so that novel classes can be separated at test time. However, their discovery mechanism at inference is typically reduced to a single threshold. We argue that this paradigm is fundamentally flawed as OCD is not a static classification problem, but a dynamic process. The model must continuously decide 1) whether a sample belongs to a known class, 2) matches an existing novel category, or 3) should initiate a new one. Moreover, prior methods treat the support set as fixed knowledge. They do not update their decision boundaries as new evidence arrives during inference. This leads to unstable and inconsistent category formation. Our experiments confirm these issues. With properly calibrated and adaptive thresholds, substantial improvements can be achieved, even without changing the representation. Motivated by this, we propose PACO, a support-set-calibrated, tree-structured online decision framework. The framework models inference as a sequence of hierarchical decisions, including known-class routing, birth-aware novel assignment, and attach-versus-create operations over a dynamic prototype memory. Furthermore, we simulate the proxy discovery process to initialize the thresholds during offline training to align with inference. Thresholds are continuously updated during inference using mature novel prototypes. Importantly, PACO requires no heavy training and no dataset-specific tuning. It can be directly integrated into existing OCD pipelines as an inference-time module. Extensive experiments show significant improvements over SOTA baselines across seven benchmarks.
Learning through Creation: A Hash-Free Framework for On-the-Fly Category Discovery
Mar 17, 2026On-the-Fly Category Discovery (OCD) aims to recognize known classes while simultaneously discovering emerging novel categories during inference, using supervision only from known classes during offline training. Existing approaches rely either on fixed label supervision or on diffusion-based augmentations to enhance the backbone, yet none of them explicitly train the model to perform the discovery task required at test time. It is fundamentally unreasonable to expect a model optimized on limited labeled data to carry out a qualitatively different discovery objective during inference. This mismatch creates a clear optimization misalignment between the offline learning stage and the online discovery stage. In addition, prior methods often depend on hash-based encodings or severe feature compression, which further limits representational capacity. To address these issues, we propose Learning through Creation (LTC), a fully feature-based and hash-free framework that injects novel-category awareness directly into offline learning. At its core is a lightweight, online pseudo-unknown generator driven by kernel-energy minimization and entropy maximization (MKEE). Unlike previous methods that generate synthetic samples once before training, our generator evolves jointly with the model dynamics and synthesizes pseudo-novel instances on the fly at negligible cost. These samples are incorporated through a dual max-margin objective with adaptive thresholding, strengthening the model's ability to delineate and detect unknown regions through explicit creation. Extensive experiments across seven benchmarks show that LTC consistently outperforms prior work, achieving improvements ranging from 1.5 percent to 13.1 percent in all-class accuracy. The code is available at https://github.com/brandinzhang/LTC
From Folding Mechanics to Robotic Function: A Unified Modeling Framework for Compliant Origami
Mar 16, 2026Origami inspired architectures offer a powerful route toward lightweight, reconfigurable, and programmable robotic systems. Yet, a unified mechanics framework capable of seamlessly bridging rigid folding, elastic deformation, and stability driven transitions in compliant origami remains lacking. Here, we introduce a geometry consistent modeling framework based on discrete differential geometry (DDG) that unifies panel elasticity and crease rotation within a single variational formulation. By embedding crease panel coupling directly into a mid edge geometric discretization, the framework naturally captures rigid folding limits, distributed bending, multistability, and nonlinear dynamic snap through within one mechanically consistent structure. This unified description enables programmable control of stability and deformation across rigid and compliant regimes, allowing origami structures to transition from static folding mechanisms to active robotic modules. An implicit dynamic formulation incorporating gravity, contact, friction, and magnetic actuation further supports strongly coupled multiphysics simulations. Through representative examples spanning single fold bifurcation, deployable Miura membranes, bistable Waterbomb modules, and Kresling based crawling robots, we demonstrate how geometry driven mechanics directly informs robotic functionality. This work establishes discrete differential geometry as a foundational design language for intelligent origami robotics, enabling predictive modeling, stability programming, and mechanics guided robotic actuation within a unified computational platform.
ContextBench: A Benchmark for Context Retrieval in Coding Agents
Feb 05, 2026LLM-based coding agents have shown strong performance on automated issue resolution benchmarks, yet existing evaluations largely focus on final task success, providing limited insight into how agents retrieve and use code context during problem solving. We introduce ContextBench, a process-oriented evaluation of context retrieval in coding agents. ContextBench consists of 1,136 issue-resolution tasks from 66 repositories across eight programming languages, each augmented with human-annotated gold contexts. We further implement an automated evaluation framework that tracks agent trajectories and measures context recall, precision, and efficiency throughout issue resolution. Using ContextBench, we evaluate four frontier LLMs and five coding agents. Our results show that sophisticated agent scaffolding yields only marginal gains in context retrieval ("The Bitter Lesson" of coding agents), LLMs consistently favor recall over precision, and substantial gaps exist between explored and utilized context. ContextBench augments existing end-to-end benchmarks with intermediate gold-context metrics that unbox the issue-resolution process. These contexts offer valuable intermediate signals for guiding LLM reasoning in software tasks. Data and code are available at: https://cioutn.github.io/context-bench/.
CoSA: Compressed Sensing-Based Adaptation of Large Language Models
Feb 05, 2026Parameter-Efficient Fine-Tuning (PEFT) has emerged as a practical paradigm for adapting large language models (LLMs) without updating all parameters. Most existing approaches, such as LoRA and PiSSA, rely on low-rank decompositions of weight updates. However, the low-rank assumption may restrict expressivity, particularly in task-specific adaptation scenarios where singular values are distributed relatively uniformly. To address this limitation, we propose CoSA (Compressed Sensing-Based Adaptation), a new PEFT method extended from compressed sensing theory. Instead of constraining weight updates to a low-rank subspace, CoSA expresses them through fixed random projection matrices and a compact learnable core. We provide a formal theoretical analysis of CoSA as a synthesis process, proving that weight updates can be compactly encoded into a low-dimensional space and mapped back through random projections. Extensive experimental results show that CoSA provides a principled perspective for efficient and expressive multi-scale model adaptation. Specifically, we evaluate CoSA on 10 diverse tasks, including natural language understanding and generation, employing 5 models of different scales from RoBERTa, Llama, and Qwen families. Across these settings, CoSA consistently matches or outperforms state-of-the-art PEFT methods.
Who Owns the Text? Design Patterns for Preserving Authorship in AI-Assisted Writing
Jan 15, 2026AI writing assistants can reduce effort and improve fluency, but they may also weaken writers' sense of authorship. We study this tension with an ownership-aware co-writing editor that offers on-demand, sentence-level suggestions and tests two common design choices: persona-based coaching and style personalization. In an online study (N=176), participants completed three professional writing tasks: an email without AI help, a proposal with generic AI suggestions, and a cover letter with persona-based coaching, while half received suggestions tailored to a brief sample of their prior writing. Across the two AI-assisted tasks, psychological ownership dropped relative to unassisted writing (about 0.85-1.0 points on a 7-point scale), even as cognitive load decreased (about 0.9 points) and quality ratings stayed broadly similar overall. Persona coaching did not prevent the ownership decline. Style personalization partially restored ownership (about +0.43) and increased AI incorporation in text (+5 percentage points). We distill five design patterns: on-demand initiation, micro-suggestions, voice anchoring, audience scaffolds, and point-of-decision provenance, to guide authorship-preserving writing tools.
Sparse-RL: Breaking the Memory Wall in LLM Reinforcement Learning via Stable Sparse Rollouts
Jan 15, 2026Reinforcement Learning (RL) has become essential for eliciting complex reasoning capabilities in Large Language Models (LLMs). However, the substantial memory overhead of storing Key-Value (KV) caches during long-horizon rollouts acts as a critical bottleneck, often prohibiting efficient training on limited hardware. While existing KV compression techniques offer a remedy for inference, directly applying them to RL training induces a severe policy mismatch, leading to catastrophic performance collapse. To address this, we introduce Sparse-RL empowers stable RL training under sparse rollouts. We show that instability arises from a fundamental policy mismatch among the dense old policy, the sparse sampler policy, and the learner policy. To mitigate this issue, Sparse-RL incorporates Sparsity-Aware Rejection Sampling and Importance-based Reweighting to correct the off-policy bias introduced by compression-induced information loss. Experimental results show that Sparse-RL reduces rollout overhead compared to dense baselines while preserving the performance. Furthermore, Sparse-RL inherently implements sparsity-aware training, significantly enhancing model robustness during sparse inference deployment.
Neural Networks Learn Generic Multi-Index Models Near Information-Theoretic Limit
Nov 19, 2025In deep learning, a central issue is to understand how neural networks efficiently learn high-dimensional features. To this end, we explore the gradient descent learning of a general Gaussian Multi-index model $f(\boldsymbol{x})=g(\boldsymbol{U}\boldsymbol{x})$ with hidden subspace $\boldsymbol{U}\in \mathbb{R}^{r\times d}$, which is the canonical setup to study representation learning. We prove that under generic non-degenerate assumptions on the link function, a standard two-layer neural network trained via layer-wise gradient descent can agnostically learn the target with $o_d(1)$ test error using $\widetilde{\mathcal{O}}(d)$ samples and $\widetilde{\mathcal{O}}(d^2)$ time. The sample and time complexity both align with the information-theoretic limit up to leading order and are therefore optimal. During the first stage of gradient descent learning, the proof proceeds via showing that the inner weights can perform a power-iteration process. This process implicitly mimics a spectral start for the whole span of the hidden subspace and eventually eliminates finite-sample noise and recovers this span. It surprisingly indicates that optimal results can only be achieved if the first layer is trained for more than $\mathcal{O}(1)$ steps. This work demonstrates the ability of neural networks to effectively learn hierarchical functions with respect to both sample and time efficiency.
ArchMap: Arch-Flattening and Knowledge-Guided Vision Language Model for Tooth Counting and Structured Dental Understanding
Nov 18, 2025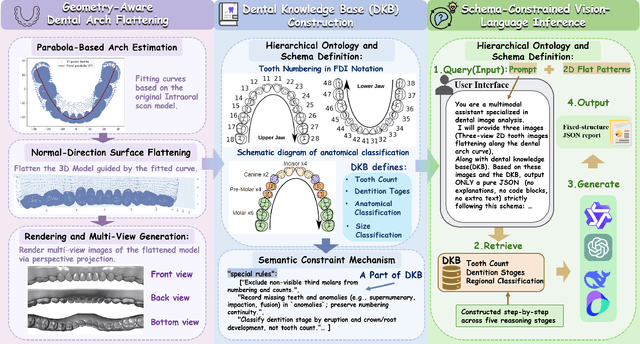
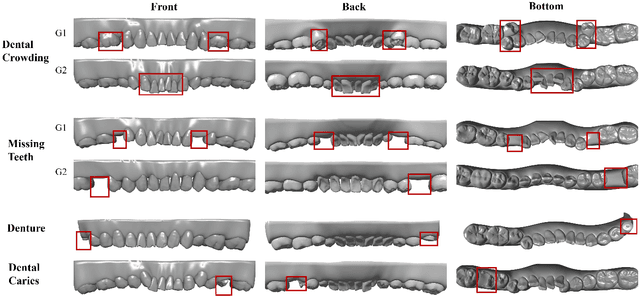
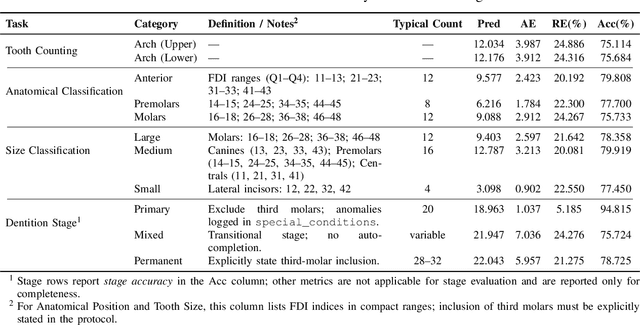
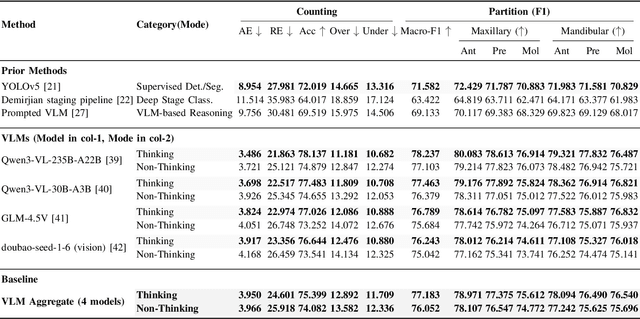
A structured understanding of intraoral 3D scans is essential for digital orthodontics. However, existing deep-learning approaches rely heavily on modality-specific training, large annotated datasets, and controlled scanning conditions, which limit generalization across devices and hinder deployment in real clinical workflows. Moreover, raw intraoral meshes exhibit substantial variation in arch pose, incomplete geometry caused by occlusion or tooth contact, and a lack of texture cues, making unified semantic interpretation highly challenging. To address these limitations, we propose ArchMap, a training-free and knowledge-guided framework for robust structured dental understanding. ArchMap first introduces a geometry-aware arch-flattening module that standardizes raw 3D meshes into spatially aligned, continuity-preserving multi-view projections. We then construct a Dental Knowledge Base (DKB) encoding hierarchical tooth ontology, dentition-stage policies, and clinical semantics to constrain the symbolic reasoning space. We validate ArchMap on 1060 pre-/post-orthodontic cases, demonstrating robust performance in tooth counting, anatomical partitioning, dentition-stage classification, and the identification of clinical conditions such as crowding, missing teeth, prosthetics, and caries. Compared with supervised pipelines and prompted VLM baselines, ArchMap achieves higher accuracy, reduced semantic drift, and superior stability under sparse or artifact-prone conditions. As a fully training-free system, ArchMap demonstrates that combining geometric normalization with ontology-guided multimodal reasoning offers a practical and scalable solution for the structured analysis of 3D intraoral scans in modern digital orthodontics.