 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExAnte: A Benchmark for Ex-Ante Inference in Large Language Models
May 26, 2025



Large language models (LLMs) face significant challenges in ex-ante reasoning, where analysis, inference, or predictions must be made without access to information from future events. Even with explicit prompts enforcing temporal cutoffs, LLMs often generate outputs influenced by internalized knowledge of events beyond the specified cutoff. This paper introduces a novel task and benchmark designed to evaluate the ability of LLMs to reason while adhering to such temporal constraints. The benchmark includes a variety of tasks: stock prediction, Wikipedia event prediction, scientific publication prediction, and Question Answering (QA), designed to assess factual knowledge under temporal cutoff constraints. We use leakage rate to quantify models' reliance on future information beyond cutoff timestamps. Experimental results reveal that LLMs struggle to consistently adhere to temporal cutoffs across common prompting strategies and tasks, demonstrating persistent challenges in ex-ante reasoning. This benchmark provides a potential evaluation framework to advance the development of LLMs' temporal reasoning ability for time-sensitive applications.
Ranking & Reweighting Improves Group Distributional Robustness
May 09, 2023Recent work has shown that standard training via empirical risk minimization (ERM) can produce models that achieve high accuracy on average but low accuracy on underrepresented groups due to the prevalence of spurious features. A predominant approach to tackle this group robustness problem minimizes the worst group error (akin to a minimax strategy) on the training data, hoping it will generalize well on the testing data. However, this is often suboptimal, especially when the out-of-distribution (OOD) test data contains previously unseen groups. Inspired by ideas from the information retrieval and learning-to-rank literature, this paper first proposes to use Discounted Cumulative Gain (DCG) as a metric of model quality for facilitating better hyperparameter tuning and model selection. Being a ranking-based metric, DCG weights multiple poorly-performing groups (instead of considering just the group with the worst performance). As a natural next step, we build on our results to propose a ranking-based training method called Discounted Rank Upweighting (DRU), which differentially reweights a ranked list of poorly-performing groups in the training data to learn models that exhibit strong OOD performance on the test data. Results on several synthetic and real-world datasets highlight the superior generalization ability of our group-ranking-based (akin to soft-minimax) approach in selecting and learning models that are robust to group distributional shifts.
Modeling Dynamic User Interests: A Neural Matrix Factorization Approach
Feb 12, 2021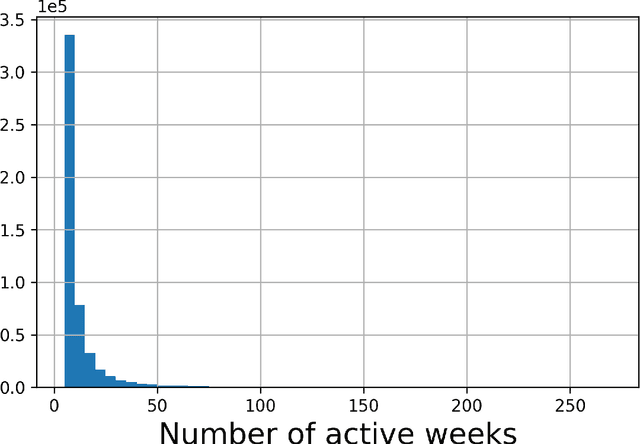
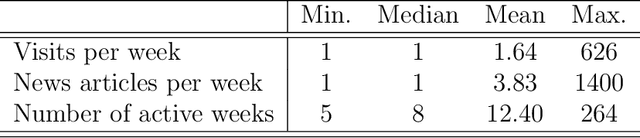
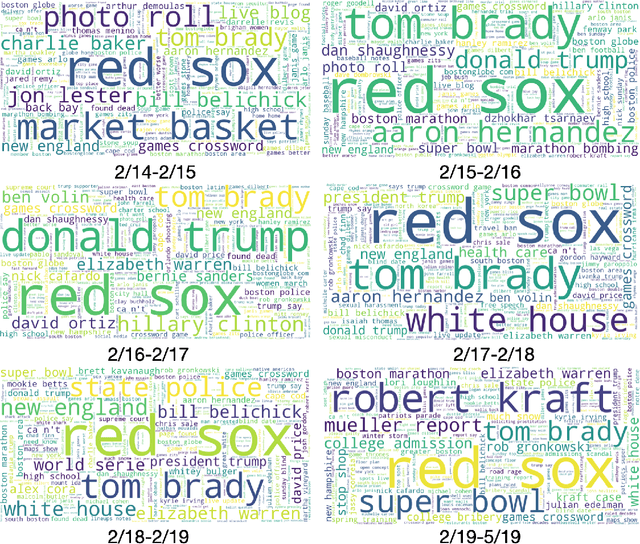
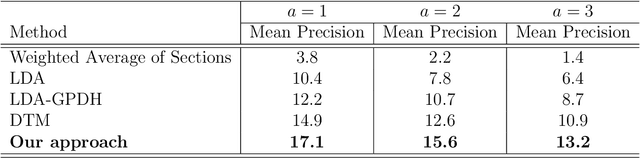
In recent years, there has been significant interest in understanding users' online content consumption patterns. But, the unstructured, high-dimensional, and dynamic nature of such data makes extracting valuable insights challenging. Here we propose a model that combines the simplicity of matrix factorization with the flexibility of neural networks to efficiently extract nonlinear patterns from massive text data collections relevant to consumers' online consumption patterns. Our model decomposes a user's content consumption journey into nonlinear user and content factors that are used to model their dynamic interests. This natural decomposition allows us to summarize each user's content consumption journey with a dynamic probabilistic weighting over a set of underlying content attributes. The model is fast to estimate, easy to interpret and can harness external data sources as an empirical prior. These advantages make our method well suited to the challenges posed by modern datasets. We use our model to understand the dynamic news consumption interests of Boston Globe readers over five years. Thorough qualitative studies, including a crowdsourced evaluation, highlight our model's ability to accurately identify nuanced and coherent consumption patterns. These results are supported by our model's superior and robust predictive performance over several competitive baseline methods.
Targeting for long-term outcomes
Oct 29, 2020
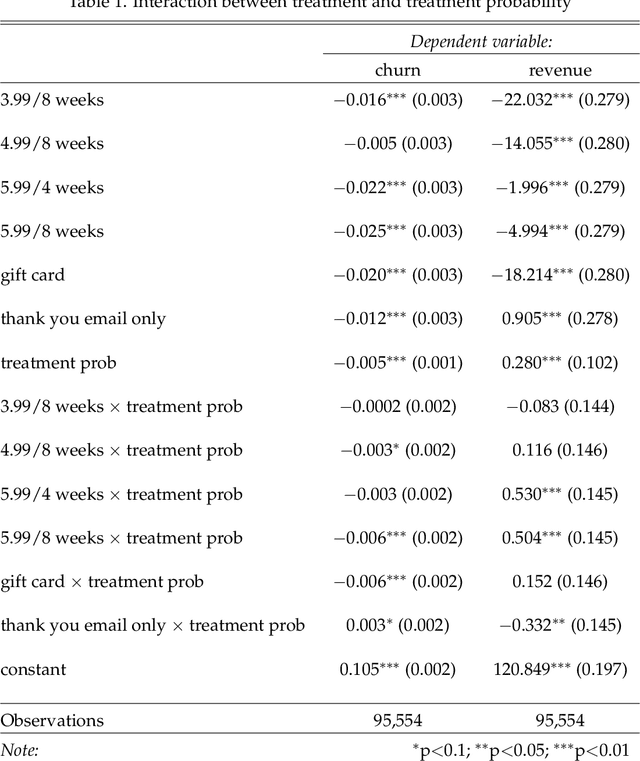
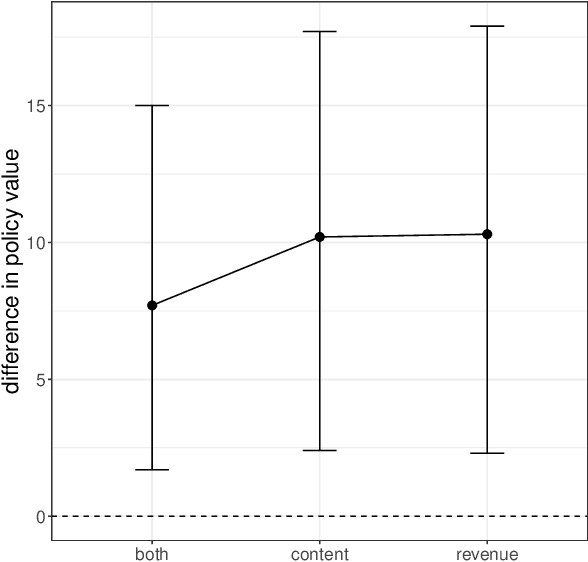
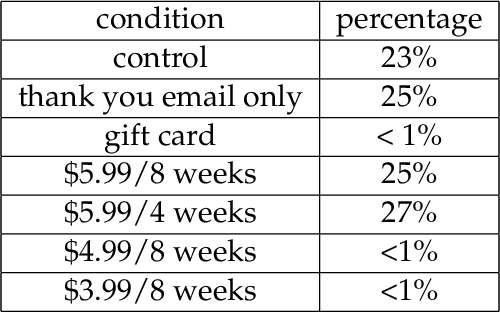
Decision-makers often want to target interventions (e.g., marketing campaigns) so as to maximize an outcome that is observed only in the long-term. This typically requires delaying decisions until the outcome is observed or relying on simple short-term proxies for the long-term outcome. Here we build on the statistical surrogacy and off-policy learning literature to impute the missing long-term outcomes and then approximate the optimal targeting policy on the imputed outcomes via a doubly-robust approach. We apply our approach in large-scale proactive churn management experiments at The Boston Globe by targeting optimal discounts to its digital subscribers to maximize their long-term revenue. We first show that conditions for validity of average treatment effect estimation with imputed outcomes are also sufficient for valid policy evaluation and optimization; furthermore, these conditions can be somewhat relaxed for policy optimization. We then validate this approach empirically by comparing it with a policy learned on the ground truth long-term outcomes and show that they are statistically indistinguishable. Our approach also outperforms a policy learned on short-term proxies for the long-term outcome. In a second field experiment, we implement the optimal targeting policy with additional randomized exploration, which allows us to update the optimal policy for each new cohort of customers to account for potential non-stationarity. Over three years, our approach had a net-positive revenue impact in the range of $4-5 million compared to The Boston Globe's current policies.
Two Step CCA: A new spectral method for estimating vector models of words
Jun 27, 2012


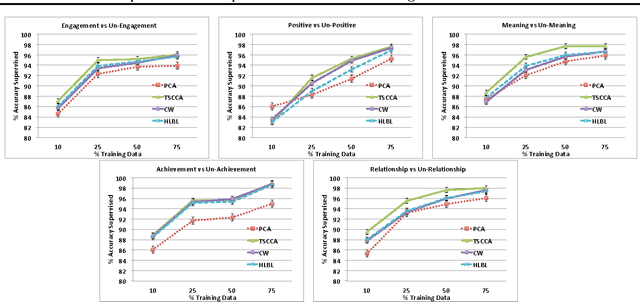
Unlabeled data is often used to learn representations which can be used to supplement baseline features in a supervised learner. For example, for text applications where the words lie in a very high dimensional space (the size of the vocabulary), one can learn a low rank "dictionary" by an eigen-decomposition of the word co-occurrence matrix (e.g. using PCA or CCA). In this paper, we present a new spectral method based on CCA to learn an eigenword dictionary. Our improved procedure computes two set of CCAs, the first one between the left and right contexts of the given word and the second one between the projections resulting from this CCA and the word itself. We prove theoretically that this two-step procedure has lower sample complexity than the simple single step procedure and also illustrate the empirical efficacy of our approach and the richness of representations learned by our Two Step CCA (TSCCA) procedure on the tasks of POS tagging and sentiment classification.