 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing AI Negotiations: New Theory and Evidence from a Large-Scale Autonomous Negotiations Competition
Mar 09, 2025



Despite the rapid proliferation of artificial intelligence (AI) negotiation agents, there has been limited integration of computer science research and established negotiation theory to develop new theories of AI negotiation. To bridge this gap, we conducted an International AI Negotiations Competition in which participants iteratively designed and refined prompts for large language model (LLM) negotiation agents. We then facilitated over 120,000 negotiations between these agents across multiple scenarios with diverse characteristics and objectives. Our findings revealed that fundamental principles from established human-human negotiation theory remain crucial in AI-AI negotiations. Specifically, agents exhibiting high warmth fostered higher counterpart subjective value and reached deals more frequently, which enabled them to create and claim more value in integrative settings. However, conditional on reaching a deal, warm agents claimed less value while dominant agents claimed more value. These results align with classic negotiation theory emphasizing relationship-building, assertiveness, and preparation. Our analysis also revealed unique dynamics in AI-AI negotiations not fully explained by negotiation theory, particularly regarding the effectiveness of AI-specific strategies like chain-of-thought reasoning and prompt injection. The agent that won our competition implemented an approach that blended traditional negotiation preparation frameworks with AI-specific methods. Together, these results suggest the importance of establishing a new theory of AI negotiations that integrates established negotiation theory with AI-specific strategies to optimize agent performance. Our research suggests this new theory must account for the unique characteristics of autonomous agents and establish the conditions under which traditional negotiation theory applies in automated settings.
Teaching AI to Handle Exceptions: Supervised Fine-Tuning with Human-Aligned Judgment
Mar 04, 2025Large language models (LLMs), initially developed for generative AI, are now evolving into agentic AI systems, which make decisions in complex, real-world contexts. Unfortunately, while their generative capabilities are well-documented, their decision-making processes remain poorly understood. This is particularly evident when models are handling exceptions, a critical and challenging aspect of decision-making made relevant by the inherent incompleteness of contracts. Here we demonstrate that LLMs, even ones that excel at reasoning, deviate significantly from human judgments because they adhere strictly to policies, even when such adherence is impractical, suboptimal, or even counterproductive. We then evaluate three approaches to tuning AI agents to handle exceptions: ethical framework prompting, chain-of-thought reasoning, and supervised fine-tuning. We find that while ethical framework prompting fails and chain-of-thought prompting provides only slight improvements, supervised fine-tuning, specifically with human explanations, yields markedly better results. Surprisingly, in our experiments, supervised fine-tuning even enabled models to generalize human-like decision-making to novel scenarios, demonstrating transfer learning of human-aligned decision-making across contexts. Furthermore, fine-tuning with explanations, not just labels, was critical for alignment, suggesting that aligning LLMs with human judgment requires explicit training on how decisions are made, not just which decisions are made. These findings highlight the need to address LLMs' shortcomings in handling exceptions in order to guide the development of agentic AI toward models that can effectively align with human judgment and simultaneously adapt to novel contexts.
Modeling Dynamic User Interests: A Neural Matrix Factorization Approach
Feb 12, 2021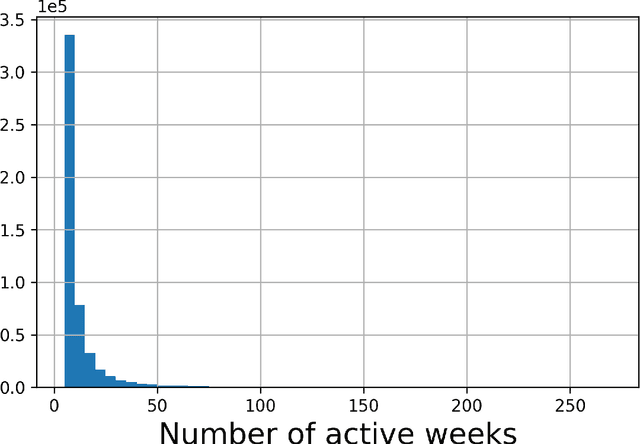
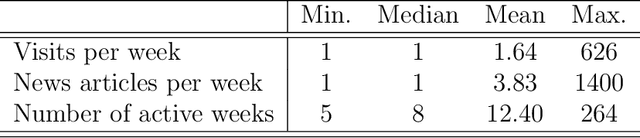
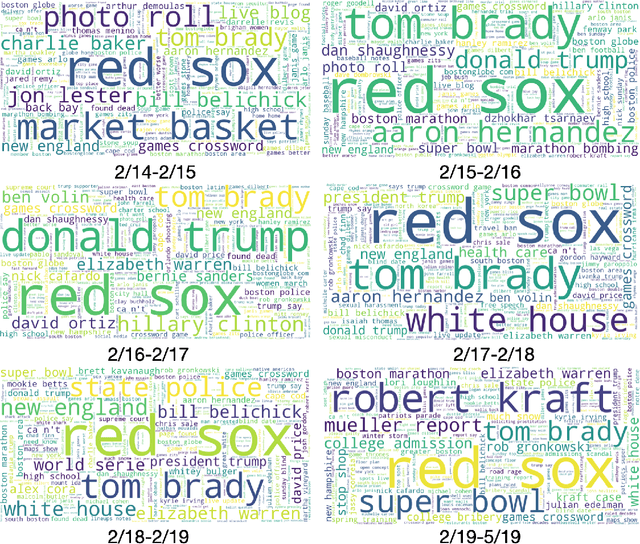
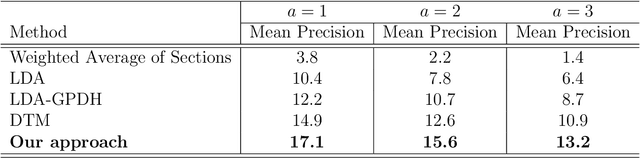
In recent years, there has been significant interest in understanding users' online content consumption patterns. But, the unstructured, high-dimensional, and dynamic nature of such data makes extracting valuable insights challenging. Here we propose a model that combines the simplicity of matrix factorization with the flexibility of neural networks to efficiently extract nonlinear patterns from massive text data collections relevant to consumers' online consumption patterns. Our model decomposes a user's content consumption journey into nonlinear user and content factors that are used to model their dynamic interests. This natural decomposition allows us to summarize each user's content consumption journey with a dynamic probabilistic weighting over a set of underlying content attributes. The model is fast to estimate, easy to interpret and can harness external data sources as an empirical prior. These advantages make our method well suited to the challenges posed by modern datasets. We use our model to understand the dynamic news consumption interests of Boston Globe readers over five years. Thorough qualitative studies, including a crowdsourced evaluation, highlight our model's ability to accurately identify nuanced and coherent consumption patterns. These results are supported by our model's superior and robust predictive performance over several competitive baseline methods.
Targeting for long-term outcomes
Oct 29, 2020
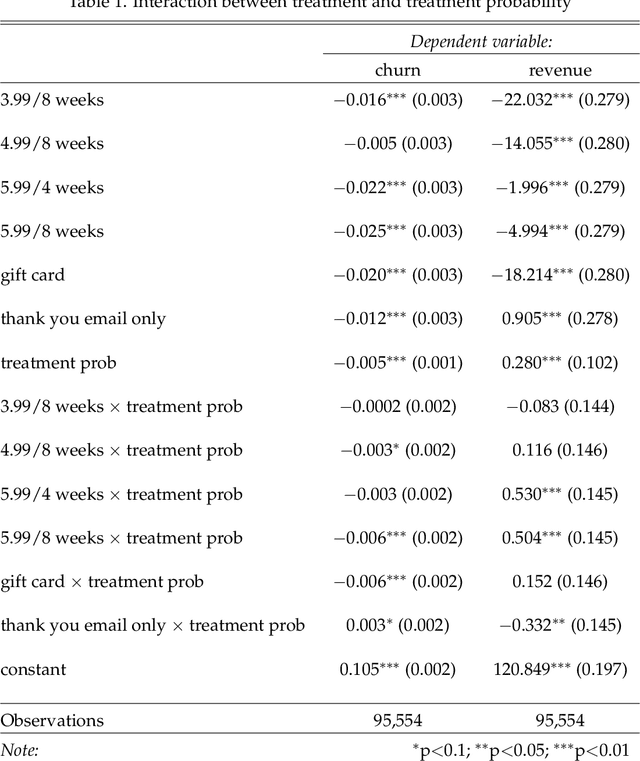
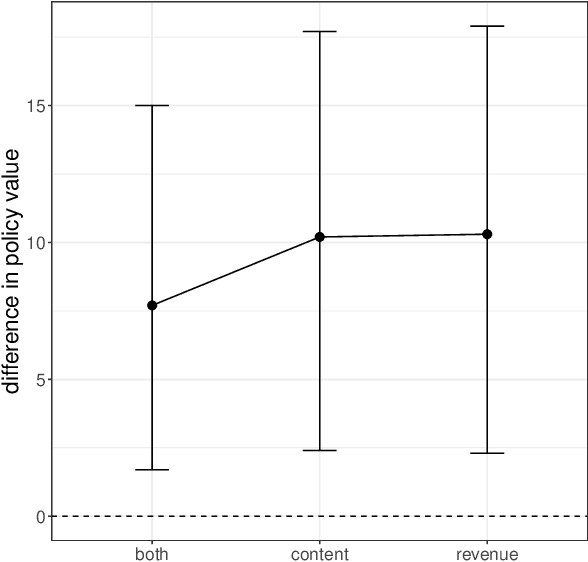
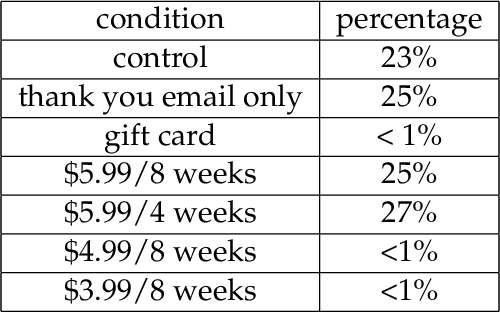
Decision-makers often want to target interventions (e.g., marketing campaigns) so as to maximize an outcome that is observed only in the long-term. This typically requires delaying decisions until the outcome is observed or relying on simple short-term proxies for the long-term outcome. Here we build on the statistical surrogacy and off-policy learning literature to impute the missing long-term outcomes and then approximate the optimal targeting policy on the imputed outcomes via a doubly-robust approach. We apply our approach in large-scale proactive churn management experiments at The Boston Globe by targeting optimal discounts to its digital subscribers to maximize their long-term revenue. We first show that conditions for validity of average treatment effect estimation with imputed outcomes are also sufficient for valid policy evaluation and optimization; furthermore, these conditions can be somewhat relaxed for policy optimization. We then validate this approach empirically by comparing it with a policy learned on the ground truth long-term outcomes and show that they are statistically indistinguishable. Our approach also outperforms a policy learned on short-term proxies for the long-term outcome. In a second field experiment, we implement the optimal targeting policy with additional randomized exploration, which allows us to update the optimal policy for each new cohort of customers to account for potential non-stationarity. Over three years, our approach had a net-positive revenue impact in the range of $4-5 million compared to The Boston Globe's current policies.
The Engagement-Diversity Connection: Evidence from a Field Experiment on Spotify
Mar 17, 2020
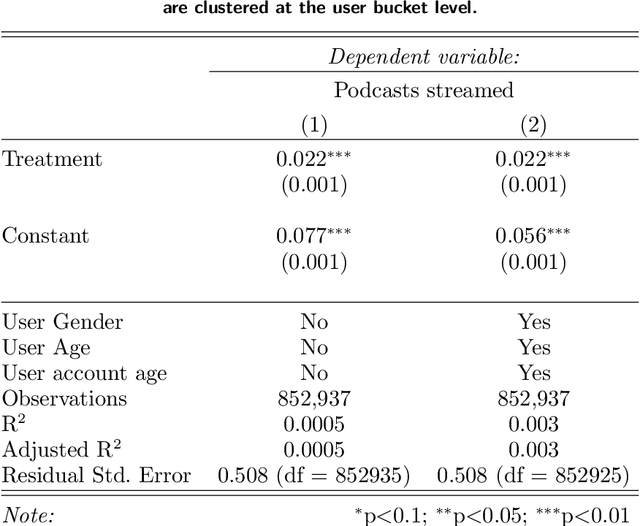
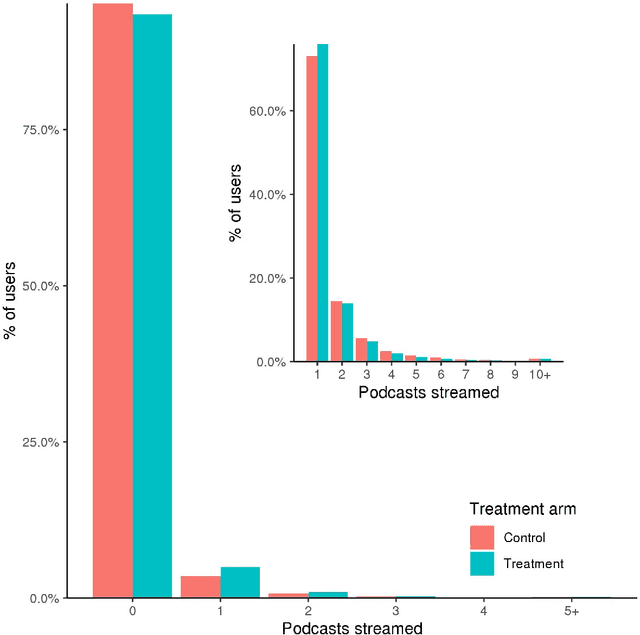
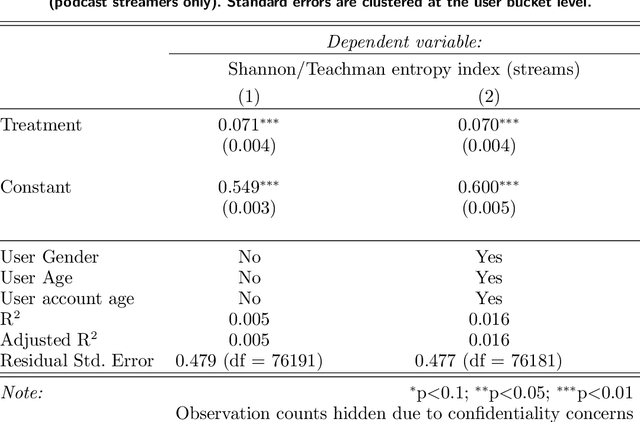
It remains unknown whether personalized recommendations increase or decrease the diversity of content people consume. We present results from a randomized field experiment on Spotify testing the effect of personalized recommendations on consumption diversity. In the experiment, both control and treatment users were given podcast recommendations, with the sole aim of increasing podcast consumption. Treatment users' recommendations were personalized based on their music listening history, whereas control users were recommended popular podcasts among users in their demographic group. We find that, on average, the treatment increased podcast streams by 28.90%. However, the treatment also decreased the average individual-level diversity of podcast streams by 11.51%, and increased the aggregate diversity of podcast streams by 5.96%, indicating that personalized recommendations have the potential to create patterns of consumption that are homogenous within and diverse across users, a pattern reflecting Balkanization. Our results provide evidence of an "engagement-diversity trade-off" when recommendations are optimized solely to drive consumption: while personalized recommendations increase user engagement, they also affect the diversity of consumed content. This shift in consumption diversity can affect user retention and lifetime value, and impact the optimal strategy for content producers. We also observe evidence that our treatment affected streams from sections of Spotify's app not directly affected by the experiment, suggesting that exposure to personalized recommendations can affect the content that users consume organically. We believe these findings highlight the need for academics and practitioners to continue investing in personalization methods that explicitly take into account the diversity of content recommended.
Scalable bundling via dense product embeddings
Jan 31, 2020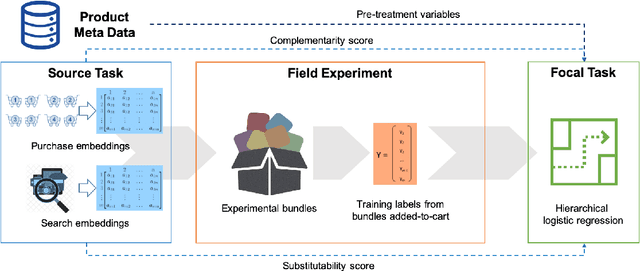
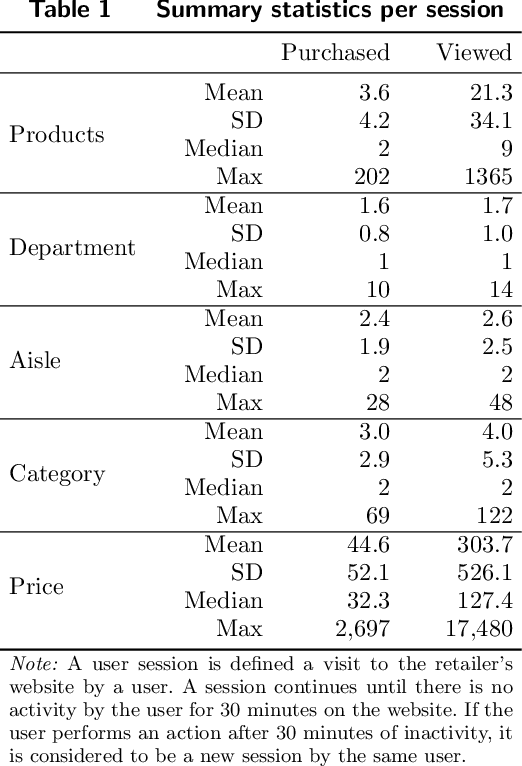
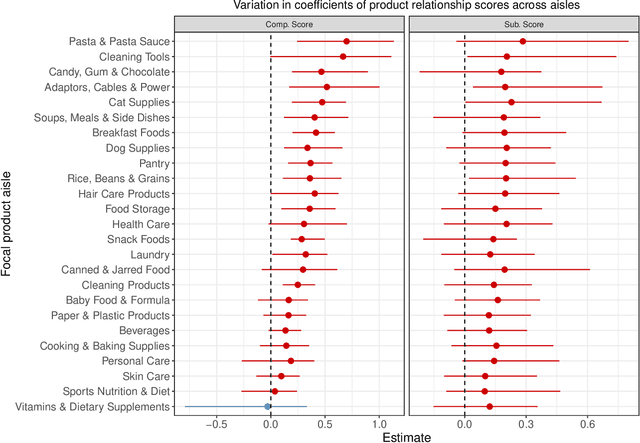
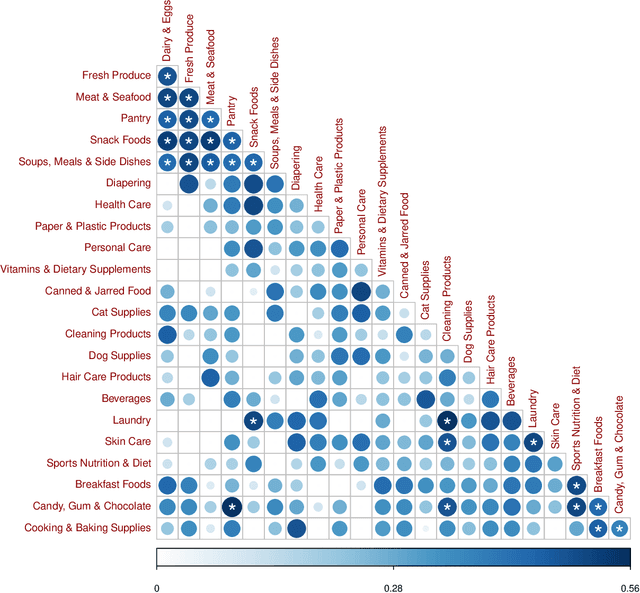
Bundling, the practice of jointly selling two or more products at a discount, is a widely used strategy in industry and a well examined concept in academia. Historically, the focus has been on theoretical studies in the context of monopolistic firms and assumed product relationships, e.g., complementarity in usage. We develop a new machine-learning-driven methodology for designing bundles in a large-scale, cross-category retail setting. We leverage historical purchases and consideration sets created from clickstream data to generate dense continuous representations of products called embeddings. We then put minimal structure on these embeddings and develop heuristics for complementarity and substitutability among products. Subsequently, we use the heuristics to create multiple bundles for each product and test their performance using a field experiment with a large retailer. We combine the results from the experiment with product embeddings using a hierarchical model that maps bundle features to their purchase likelihood, as measured by the add-to-cart rate. We find that our embeddings-based heuristics are strong predictors of bundle success, robust across product categories, and generalize well to the retailer's entire assortment.